 531
531 
Содержание
Продолжая разговор про обучение разработчиков Apache Kafka, сегодня рассмотрим, чем ksqlDB отличается от Kafka Streams. Также читайте далее про основные достоинства и недостатки перезапуска KSQL в виде отдельной базы данных потоковой передачи событий с API-интерфейсом на основе SQL для запроса и обработки информации из топиков Kafka.
ksqlDB vs Kafka Streams: ключевые отличия
ksqlDB основан на клиентской библиотеке Kafka Streams, которая является частью платформы потоковой обработки событий Apache Kafka и позволяет разработчику Big Data создавать надежные распределенные приложения для взаимодействия с информацией из топиков Кафка. По сравнению с Kafka Streams, ksqlDB предоставляет более высокий уровень абстракции для разработки приложений потоковой аналитики больших данных, скрывая значительную часть сложного программирования. Таким образом, при выполнении операций в реальном времени с потоками данных одна строка SQL-запросов может выполнять работу десятка строк на Java или Scala [1]. Это существенно снижает порог входа в технологию, позволяя аналитику данных или Data Scientist’у анализировать информацию прямо из топиков Kafka.
Побочным эффектом такой простоты использования является снижение уровня контроля над кодом, что ограничивает возможности оптимизации распределенных программ, заставляя разработчика полагаться на встроенные средства движка ksqlDB. Поэтому, при выборе технологии разработки следует учитывать, что ksqlDB проще в использовании, а Kafka Streams и, тем более, API Consumer/Producer самой Kafka. Впрочем, возможно совмещение и одновременное использование всех этих технологий. Кроме того, можно реализовать пользовательскую логику и агрегаты в ksqlDB-приложениях, используя определяемые пользователем функции (UDF, User Defined Functions) в Java.
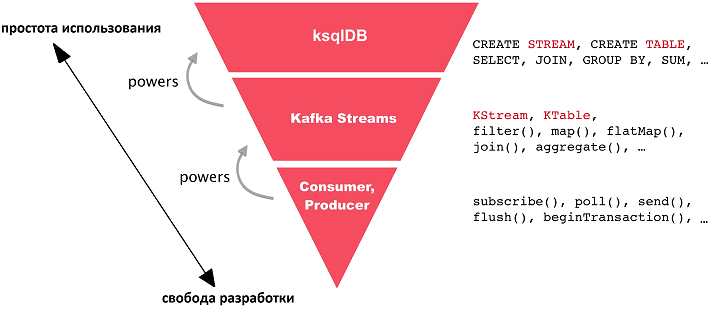
Основные отличия ksqlDB от Kafka Streams показаны далее в таблице.
|
Фактор |
ksqlDB |
Kafka Streams |
|
Результат |
SQL-выражения |
JVM-приложения |
|
GUI-интерфейс |
имеется в Confluent Control Center Confluent Cloud |
отсутствует |
|
CLI-интерфейс |
имеется |
отсутствует |
|
Форматы данных |
Avro, Protobuf, JSON, JSON_SR, CSV |
Любой формат данных, в т.ч. Avro, JSON, CSV, Protobuf, XML |
|
Имеется |
Отсутствует, но можно реализовать свой собственный |
|
|
Время запуска (Runtime) |
На стороне ksqlDB-сервера |
Приложения запускаются как типовые JVM-процессы |
|
Запрашиваемое состояние (Queryable state) |
Отсутствует |
Имеется |
Таким образом, ksqlDB можно рассматривать в качестве своего рода надстройки над Kafka Streams, поскольку этот инструмент позволяет преобразовать SQL-запросы для потоковой аналитики больших данных, в распределенные приложения. Это выполняется следующим образом [1]:
- Разработчик регистрирует поток или таблицу ksqlDB из существующего топика Kafka, например, CREATE STREAM <my-stream> WITH <topic-name>;
- Для описания нужной бизнес-логики разработчик использует соответствующий SQL-оператор, например, CREATE TABLE AS SELECT FROM <my-stream>;
- ksqlDB анализирует пользовательский SQL-оператор в абстрактное синтаксическое дерево (AST, abstract syntax tree);
- на основе AST и создается логический план пользовательского SQL-оператора;
- на базе логического плана создается физический план для SQL-выражения;
- ksqlDB создает и запускает приложение Kafka Streams;
- разработчик управляет приложением как ПОТОКОМ или ТАБЛИЦЕЙ с соответствующим постоянным запросом (persistent query).
Что не так с обновленным KSQL: 3 существенных недостатка
Поскольку ksqlDB представляет собой развитие KSQL, SQL-движка Кафка, с добавлением 2-х новых возможностей (управление коннекторами и pull-запросы), о чем мы рассказывали вчера, этим обусловлены некоторые специфические ограничения данного инструмента [2]:
- предназначенный для потоковой обработки и материализации асинхронно вычисляемых представлений, он не обеспечивает согласованности чтения после записи и не предназначен в качестве OLTP-хранилища для первичных данных.
- доступность обслуживающего уровня ограничена временем переключения при отказе.
- производительность простых pull-запросов, когда система ввода-вывода не является узким местом, составляет до нескольких тысяч запросов в секунду. Для больших наборов данных, которые не помещаются в памяти при разделении и репликации в кластере, производительность зависит от RocksDB (встроенной СУБД Кафка) или другого встроенного хранилища, по выбору пользователя.
Также стоит помнить, что при развертывании ksqlDB-приложений на Kubernetes, некоторые операции потоковой аналитики больших данных, в частности, группировка, зависят от размера потока и памяти пода Kubernetes. Это связано с неограниченностью обрабатываемых потоков событий, которая прекращается только при явной остановке ksqlDB-приложений [3].
Завтра мы расскажем про обновления всей платформы Кафка в релизе 2.7.0, вышедшем в декабре 2020 года. А узнать больше о компонентах Apache Kafka для потоковой аналитики больших данных, а также научиться разрабатывать быстрые распределенные приложения и эффективно администрировать кластера, вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

