 1083
1083 
В этой статье мы поговорим про работу с представлениями в Apache Impala. Также рассмотрим структуру представлений в этой SQL-подобной распределенной СУБД, входящей в экосистему Hadoop. Читайте далее про особенности работы с представлениями в Impala, которые делают эту СУБД весьма удобным и мощным средством хранения и обработки Big Data.
Как работает механизм представлений в Apache Impala: особенности работы с виртуальными таблицами
Представление (view) — это виртуальная таблица (фактически не существует в базе данных), которая хранится в виде файла SQL-запроса в файловой системе (а также в базе данных). В отличие от обычных таблиц, представление в Impala не является самостоятельной частью набора данных, так как создается на основе данных, которые находятся в реальных таблицах. Следовательно, изменение данных в исходной (реальной) таблице базы данных немедленно отражается в содержимом всех представлений, которые были созданы на основе этой таблицы [1].
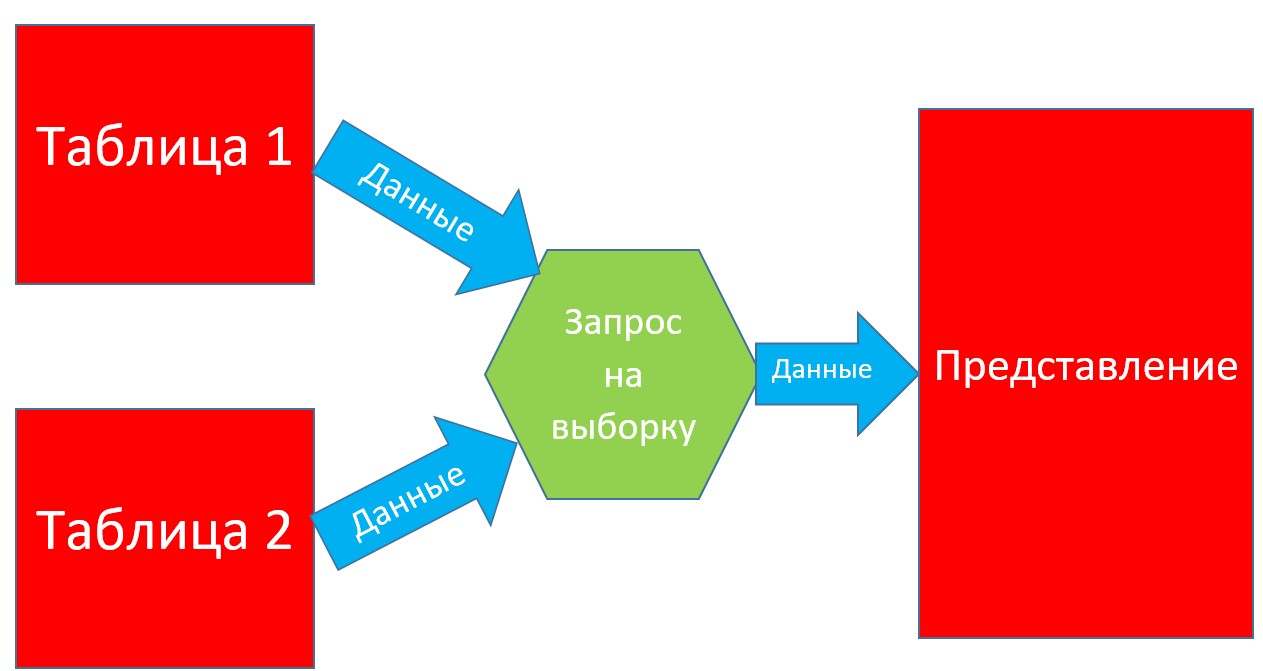
Представления в Impala имеют следующие особенности:
- Сокрытие структуры таблиц базы данных — когда пользователю нужна таблица с определенным набором данных, ему достаточно сделать простой запрос выборки (select) из подготовленного представления.
- Обеспечение защиты данных — пользователю могут предоставляться права только на представление, благодаря чему он не будет иметь доступа к данным, находящимся в тех же таблицах, но не предназначенных для использования.
- Увеличение скорости выполнения SQL-запросов — запрос на выборку данных для представления фиксируется и компилируется в момент его создания. Следовательно, при обращении к таблицам через представление, база данных не создает новый запрос, а использует уже имеющийся, что значительно ускоряет работу по получению данных [1].
Особенности работы с представлениями в Impala: несколько практических примеров
За создание представления отвечает SQL-команда CREATE VIEW. В отличие от создания обычной таблицы, при создании представления не требуется указывать типы данных полей. Следующий код на диалекте SQL Impala отвечает за создание представления customers_view [2]:
CREATE VIEW IF NOT EXISTS customers_view AS SELECT name, age FROM customers
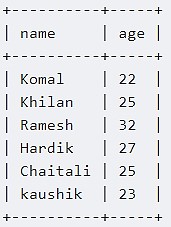
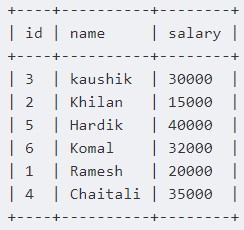
Из кода видно, что представление customers_view создается на основе выборки данных (имени и возраста) из таблицы customers (за это отвечает оператор AS SELECT FROM). Стоит также отметить, что представление с именем «customers_view» будет создано только в том случае, если в базе данных не встречается представление с таким же именем (за это отвечает оператор IF NOT EXISTS). Это делается для того, чтобы избежать получения некорректных результатов при обращении к нескольким представлениям с одинаковыми именами, но разной структурой. В Impala существует возможность изменять содержимое представлений путем добавления новых данных или удаления старых. За изменение представления отвечает команда ALTER VIEW. Изменение представления также происходит на основе выборки данных из соответствующей таблицы. Данные, которые не указываются в выборке, автоматически удаляются из представления. Например, можно изменить ранее созданное представление, добавив столбцы id и salary [2]:
ALTER VIEW customers_view AS SELECT id, name, salary FROM customers
Для того, чтобы посмотреть содержимое измененного представления, можно использовать простую выборку с помощью оператора SELECT [2]:
SELECT * FROM customers_view
За удаление существующего представления отвечает команда DROP VIEW. При удалении желательно указывать базу данных, из которой будет удалено представление. Если не указать конкретную базу данных, Impala может удалить представления с указанным в запросе именем из всех существующих на сервере баз данных. Следующий код на диалекте SQL Impala отвечает за удаление представления из базы данных my_db [2]:
DROP VIEW my_db.customers_view
Таким образом, благодаря поддержке механизма представлений, Impala обеспечивает высокий уровень безопасности хранения данных и скорости выполнения SQL-запросов, что делает ее весьма полезным средством для работы с Big Data.
Больше подробностей про применение Apache Impala в проектах анализа больших данных вы узнаете на практических курсах по Impala в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
HBASE: Администрирование кластера HBase
HIVE: Hadoop SQL администратор Hive
Источники

