 1062
1062 
Недавно мы писали про использование AirFlow для оркестрации dbt-конвейеров. Сегодня познакомимся с адаптером dbt-flink, который позволяет запускать SQL-конвейеры в проекте dbt на Apache Flink.
Зачем нужен адаптер dbt к Apache Flink и как он работает
В аналитике данных огромную роль играет эффективный, стабильный и надежный ETL-процесс, реализовать который можно с помощью инструмента dbt (Data Build Tool). Он позволяет строить конвейеры преобразования данных со встроенной CI/CD-поддержкой и обеспечением качества, не выгружая данные из источников, а работая с теми, которые уже загружены в хранилище, компилируя SQL-запросы в код. Так можно организовать различные задачи преобразования данных, чтобы запланировать их для запуска в автоматизированном и структурированном порядке. Пример такого практического использования мы рассматривали здесь.
Благодаря использованию SQL в качестве средства манипулирования данными, dbt снижает порог входа в ETL-процессы, разгружая дата-инженеров и позволяя аналитикам выполнять операции с данными самостоятельно. Однако, dbt пока еще не очень хорошо работает с аналитическими конвейерами в реальном времени. А вот Apache Flink отлично справляется с этим, будучи мощным Big Data фреймворком с унифицированным API пакетной и потоковой обработки. Высокая производительность и малая задержка Flink делают его идеальным выбором для таких сценариев использования, как аналитика в реальном времени, машинное обучение и обработка сложных событий. Еще одним ключевым преимуществом Flink является поддержка широкого спектра источников и приемников данных, включая Apache Kafka, HDFS, AWS S3, реляционные СУБД и NoSQL-хранилища, что упрощает интеграцию с существующей инфраструктурой данных.
Разработчик Flink-приложения может определить конвейеры в этом фреймворке с помощью DataStream API на языке Java, Scala или Python, а также с помощью SQL-запросов в пакетной и потоковой обработке. Однако, аналитикам довольно сложно сделать это. Поэтому для этих пользователей компания GetInData Streaming Labs разработала адаптер dbt-flink, который позволяет определить SQL-конвейеры в реальном времени на Apache Flink, превращая этот движок в исполняющий механизм, похожий на хранилище данных.
Этот адаптер также поддерживает типичные конвейеры пакетной обработки на Flink, включая множество источников и приемников данных (Elasticsearch, Kafka, DynamoDB, Kinesis, JDBC и другие). В реализации использована функция Flink SQL Gateway, которая предоставляет API для выполнения SQL-запросов в кластере. Это превращает Flink-приложение в мощной ETL-инструмент, управляемый dbt-платформой.
Напомним, Flink SQL Gateway – это сервис, который позволяет нескольким удаленным клиентам одновременно выполнять SQL. Он предоставляет простой способ отправить задание Flink, просмотреть метаданные и проанализировать внешние данные. Шлюз SQL состоит из подключаемых конечных точек и службы процессора SqlGatewayService, который повторно используется ими для обработки запросов. В зависимости от типа конечных точек пользователи могут использовать различные утилиты для подключения. SQL Gateway включен в стандартный дистрибутив фреймворка и готов к обработке таблиц в кластере. Flink изначально поддерживает конечную точку REST и конечную точку HiveServer2. Шлюз SQL по умолчанию связан с конечной точкой REST.
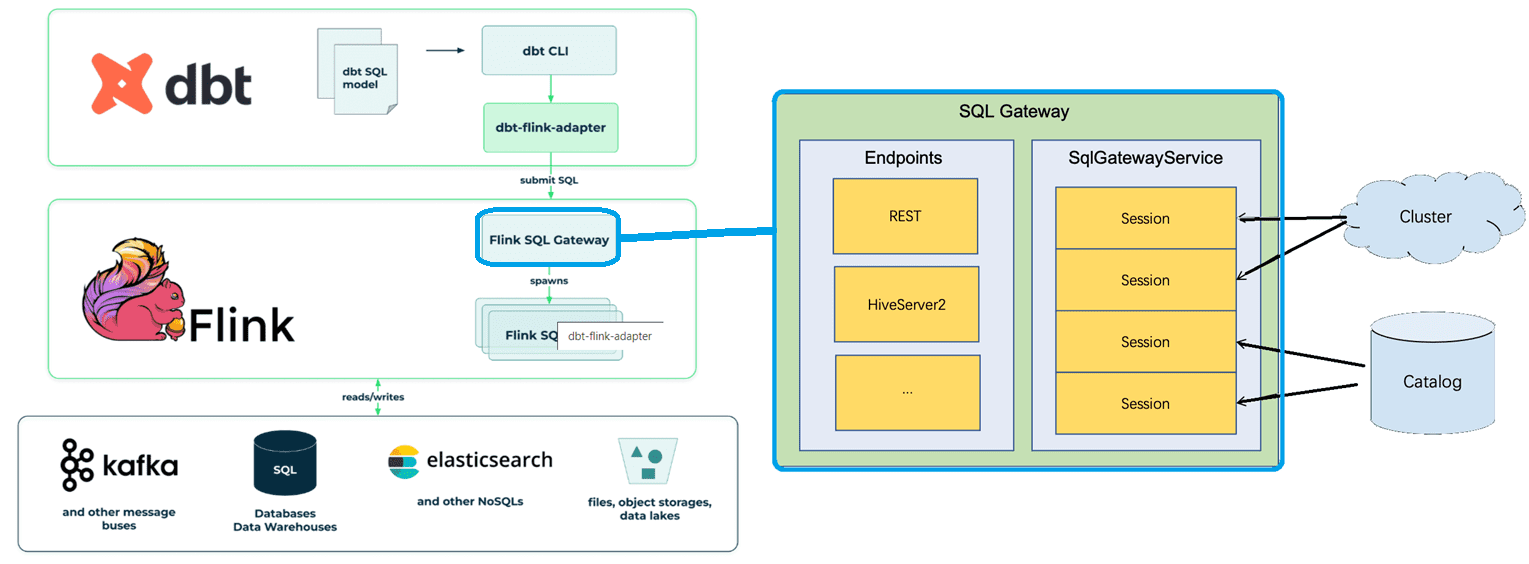
Взаимодействие с кластером Flink осуществляется в сеансах: любая таблица и представление, созданные в одном сеансе, не будут видны в другом сеансе. Сеанс по умолчанию действителен только в течение 10 минут. Из-за этого, запустив тест dbt более чем через 10 минут после запуска платформы, он завершится ошибкой, которая зарегистрируется в журналах Flink. Чтобы обойти это, придется перезапустить всю dbt-модель. Обработчик сеанса хранится в YAML-файле ~/.dbt/flink-session.yml. Если надо инициировать новый сеанс, можно просто удалить этот файл.
В заключение отметим, что адаптер dbt-flink позволяет создавать и развертывать потоковые SQL-конвейеры и пакетные задания dbt в кластере Flink, но пока не включает полного управления жизненным циклом потоковых конвейеров. Чтобы реализовать это, нужно использовать постоянные каталоги, чтобы на любую таблицу или представление, которые материализуются во Flink, можно было ссылаться в более позднее время, задолго до окончания срока действия сеанса.
Также есть проблема с рассогласованием времени жизни потоковых заданий Flink и dbt-моделей. Необходим способ определить, какое задание Flink развернуто из какой модели, чтобы заменить его при обновлении. Этот сценарий не характерен для dbt, поскольку обычно его ETL-процессы не обновляются в середине выполнения. Дата-инженеры GetInData Streaming Labs планируют реализовать это в следующем выпуске своего адаптера. О другом адаптере для Flnk от GetInData мы рассказывали здесь.
Потоковая обработка данных с помощью Apache Flink
Код курса
FLINK
Ближайшая дата курса
15 июня, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
Узнайте больше про применение Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

