 927
927 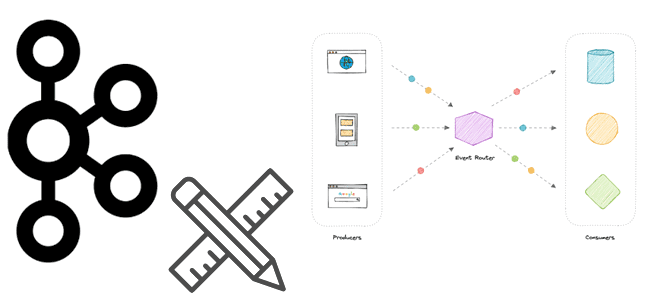
Содержание
Будучи распределенной платформой передачи событий, Apache Kafka часто используется для построения архитектуры, управляемой событиями (EDA, Event Driven Architecture). Разбираемся, что такое событие и как его спроектировать, чтобы воплотить идеи EDA с Kafka.
Проектирование событий для Apache Kafka
В общем смысле событие – это свершившийся факт. В EDA-архитектуре события используются различными автономными приложениями для обмена данными через платформу потоковой передачи событий. События создаются, сохраняются и потребляются из потока событий. Событие обычно содержит одно или несколько полей данных, описывающих произошедший факт, а также метку времени, указывающую, когда событие было создано его источником. Событие также может содержать различные метаданные, например, источник происхождения и информацию на уровне хранилища, такая как положение в потоке событий.
В Apache Kafka события называются записями или сообщениями и представляют собой пару ключ/значение с отметкой времени и необязательными метаданными (заголовками). Значение записи обычно содержит представление объекта предметной области приложения или некоторую форму необработанного значения сообщения (выходные данные датчика или значения бизнес-метрик). Ключ записи используется Kafka для определения того, как данные разделяются по разделам топика. По сути, ключ представляет собой категорию события, например, идентификатор пользователя или устройства. Заголовки как метаданные записи добавляют дополнительные описания к ней и моделируются как сопоставление ключей и значений.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
25 февраля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Ключи записи, значения и заголовки являются непрозрачными типами данных, т.е. брокеры Kafka не выполняют их синтаксический анализ, а читают, хранят и записывают эти данные как необработанные массивы байтов. За десериализацию данных и их синтаксический анализ отвечает клиентские приложения Kafka, такие как потоковая база данных ksqlDB, микросервисы, реализованные с помощью библиотек Kafka Streams, Kafka Go или Consumer API.
Очень часто для представления события используется человеко-читаемый формат JSON, например, приложение-продюсер из этой статьи генерирует и публикует в Kafka события клиентских обращений в интернет-магазин:
{
"id": "08/14/2023 14:06:35",
"name": "Amy Dodson",
"subject": "app",
"content": "cacao 80"
}
Хотя событие очень похоже на объект, например, объект Обращение клиента в Магазин, в EDA-архитектуре они обрабатываются по-разному. Вместо того, чтобы запрашивать, был ли обновлен объект, EDA-система в режиме реального времени реагирует на генерируемые события. Поэтому при проектировании системы с EDA-архитектурой дизайн события очень важен, поскольку именно он является концептуальной моделью представления данных и того, как система на них реагирует.
Потоковая передача событий означает не только их публикацию в реальном времени, но и соединение, фильтрацию и группировку несколько потоков. А проектирование, управляемое событиями, означает разработку архитектуры с учетом реактивного характера событий. Поэтому значения в событии отражают реактивный характер EDA-системы с точки зрения приложения-потребителя. Определив структуру данных события, можно отражать в ней временные изменения, задавая их в ключе, например, updated_address.
Структура события может меняться в зависимости от того, предназначено ли событие для внутреннего или внешнего чтения. Например, иногда целесообразно включить изменения ключей, которые приводят к внутренней тесной связи с источником данных. Но зачастую это становится проблемой для другой команды, разрабатывающей другой сервис. Отношения между событиями также могут повлиять на проект всей системы. Например, для работы с нормализованной базой данных источника событий, потребителям потребуется разрешать внешние ключи и перемешивать данные, что приводит к жесткой связи с внутренней системой. Чтобы устранения этой жесткой зависимости, можно денормализовать данные или ввести новый уровень абстракции.
Также при проектировании структуры данных для событий разных типов следует решить, в одной или в нескольких топиках Kafka они будут храниться. Хотя публикация в один топик проще, это усложняет обработку данных на стороне потребителя, а также снова приводит к сильной связи.
Отношения между событиями и потребителями формируют дизайн событий через поток данных. Дискретные потоки определяют изменения состояния в конечном автомате приложения-потребителя, например, поток останавливается при отмене заказа. С другой стороны, непрерывные потоки — это не способы управления состоянием приложения, а серия независимых событий.
Таким образом, при проектировании структуры данных события следует ориентироваться на эти рекомендации:
- использовать схемы данных для обеспечения единообразия событий. Например, в вышеприведенном кейсе публикации событий пользовательского поведения для этого в полезной нагрузке JSON-сообщения используется ключ subject, который содержит значения, идентифицирующие тему клиентского обращения, например, заявка на покупку товара или вопрос по работе магазина.
- использовать заголовки и временные метки для идентификации времени и источника генерации события;
- использовать идентификаторы событий, чтобы аудит потоков на стороне потребителя мог выявить отсутствующие или повторяющиеся записи. Например, в уже упомянутом кейсе публикации событий пользовательского поведения для этого в полезной нагрузке JSON-сообщения используется ключ id.
Потоковая передача событий и шаблоны проектирования EDA-архитектуры
Когда есть повторяющееся явление, которое надо отслеживать, можно хранить запись в состоянии покоя внутри постоянного хранилища, например, реляционной базы данных, или записать поток событий, отражающих это явление. Связывание нескольких потоков событий и создание новых с помощью таких операций, как фильтрация и агрегирование, называется обработкой потока. В Kafka эти потоки событий называются топиками, в которых события хранятся в непрерывном логе. Операции над несколькими потоками часто выполняются клиентской библиотекой, такой как Kafka Streams, или механизмом обработки потоков, таким как ksqlDB или Flink.
Например, приложение позволяет пользователям просматривать объявления на маркетплейсе о тех категориях вещей, которые их интересуют. Как только в эту категорию добавится новый товар, изменятся какие-либо характеристики существующего, появятся вопросы или отзывы, какой-нибудь товар будет удален с продажи, подписчик получает об этом уведомление. Это можно реализовать в Apache Kafka, создав один или несколько топиков для хранения событий изменения и приложение-потребитель, считывающее эти данные.
Таким образом, мы приходим к EDA-архитектуре: дизайну системы, управляемому событиями. Для реализации этой идеи можно использовать следующие архитектурные паттерны проектирования:
- Поиск событий (Event Sourcing), когда события выступают в качестве модели хранения данных, т.е. они ограничены одним приложением с одним источником данных. Если добавить потоковую передачу данных, можно сделать метаданные об этих событиях доступными во всей системе, подобно тому как контроль версий работает с кодом. Подробнее об шаблоне Event Sourcing и особенностях его использования с Apache Kafka мы писали здесь.
- Уведомление о событии (Event notification) описывает шаблон, в котором часть архитектуры прослушивает событие и реагирует на него, выполняя какие-то действия. Например, вместо отправки запроса в базу данных каждые несколько секунд, чтобы узнать, есть ли у пользовательского объекта новые изменения, клиент прослушивает новые события изменений и реагирует на них.
- Перенос состояния по событию (Event-carried state transfer), когда состояние нижестоящих систем обновляется поступающими событиями. Это похоже на оркестрационный стиль взаимодействия систем, о котором мы рассказываем здесь.
- Разделение ответственности между запросами и командами (CQRS, Command query responsibility segregation) предполагает разделение процессов, которые записывают и считывают данные. События в результате вычислений записываются в общую структуру данных одним клиентом, а затем считываются в отдельном. CQRS имеет преимущества в производительности, поскольку команды могут управляться на разных узлах, а запросы на чтение могут быть быстро оптимизированы сами по себе. Apache Kafka может стать надежным способом реализации шаблона CQRS, поскольку принципы работы этой платформы потоковой передачи событий, похожие на парадигму издатель-подписчик (pub/sub), эффективно отделяют источники данных от приемников. Подробнее про использование этого паттерна с Apache Kafka мы писали здесь.
Как специфицировать структуры данных сообщения в AsyncAPI, читайте в нашей новой статье.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Архитектура Данных
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
[elementor-template id=»13619″]
Источники

