Может ли Apache Kafka поддерживать не только хореографический стиль взаимодействия между разными сервисами, кто и как организует оркестрацию рабочих процессов с помощью этой распределенной платформой потоковой передачи и почему она не заменит BPM-движки.
Оркестрация событий с Apache Kafka
При использовании Apache Kafka в архитектуре, управляемой событиями (EDA, Event Driven Architecture), в большинстве случаев реализуется именно хореографический паттерн взаимодействия микросервисов с отсутствием единого центра управления и асинхронной интеграцией систем. Однако, это не единственный вариант использования Apache Kafka. Эту распределенную платформу потоковой передачи событий можно также применять в качестве средства оркестрации рабочих процессов.
Например, разработчики Salesforce реализовали Junction Workflow – механизм рабочих процессов, который использует сжатые топики Kafka для управления переходами состояний рабочих процессов, которые пользователи передают в него. Этот движок предназначен для использования нескольких форматов определения рабочего процесса.
Еще одним полноценным EDA-оркестратором на базе Apache Kafka стал проект Kestra. Этот управляемый событиями оркестратор с открытым исходным кодом упрощает операции с данными и улучшает сотрудничество между инженерами и бизнес-пользователями. Применяя подход «Инфраструктура как код» к конвейерам данных, Kestra позволяет создавать надежные рабочие процессы и уверенно управлять ими. Благодаря декларативному интерфейсу YAML для определения логики оркестрации пользователи разного уровня подготовки могут участвовать в процессе создания конвейера данных. Пользовательский интерфейс автоматически корректирует определение YAML каждый раз при внесении изменения в рабочий процесс из пользовательского интерфейса или через вызов API. Таким образом, логика оркестровки определяется декларативно в коде, даже если некоторые компоненты рабочего процесса изменяются другими способами.
Хотя топик Kafka является источником истины для всей истории с гарантированным упорядочением, сжатый топик можно использовать для быстрого поиска текущего обновленного состояния. Это обеспечивает постоянное хранение данным и оперативный доступ к ним как к значениям через запросы к ключам.
Apache Kafka и BPM-системы
BPM-система позиционируется как сквозной механизм управления бизнес-процессами (Business Process Management System), позволяющий не только визуализировать деятельность в формальной нотации BPMN (Business Process Model and Notation), но и автоматизировать эти модели путем генерации веб-приложения без программирования (Low-Code). Поскольку комплексная автоматизация бизнес-процессов предполагает, в т.ч. интеграцию нескольких сервисов, под капотом у BPM-систем находятся средства организации такого взаимодействия. Для обеспечения высокой надежности и отказоустойчивости под нагрузкой, многие BPM-системы сегодня поддерживают Apache Kafka для потоковой передачи данных в реальном времени вместо простой интеграции запросов и ответов по веб-API с протоколами HTTP и SOAP/WSDL. Таким образом, BPM-системы становятся ближе к ETL-инструментам и корпоративным сервисным шинам обмена данными (ESB, Enterprise Service Bus), включая коннекторы Kafka.
Например, один из лидеров рынка BPM-систем, Camunda построила механизм рабочего процесса и принятия решений Zeebe, создав собственный движок с характеристиками, аналогичными Kafka. Zeebe распределяет данные по всем брокерам в кластере с хранилищем непосредственно в файловой системе сервера. Если один брокер выйдет из строя, другой заменит его без потери данных. Этот предварительно настроенный механизм репликации гарантирует, что Camunda сможет восстановиться после сбоя аппаратного или программного обеспечения без вмешательства человека, без потери данных и с минимальным временем простоя.
Аналитика больших данных для руководителей
Код курса
BDAM
Ближайшая дата курса
4 августа, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
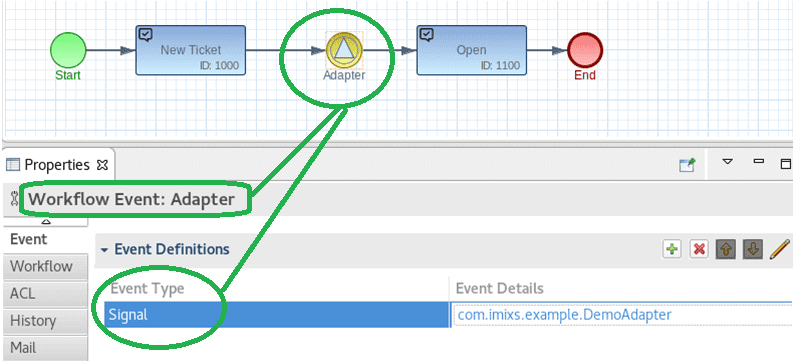
А BPM-система Imixs-Workflow поддерживает собственный адаптер для интеграции с Apache Kafka, чтобы обрабатывать асинхронные сообщения в рамках сложного бизнес-процесса. С помощью адаптера Imixs-Kafka можно настроить сценарий, в котором сообщения рабочего процесса генерируются автоматически в течение жизненного цикла обработки. Благодаря функции Autowire новые экземпляры процессов отправляются в топик Kafka, чтобы приложения-потребители мог считать эти данные и отреагировать на них. Адаптер фильтрует события рабочего процесса по номеру версии модели, позволяя контролировать, какие рабочие процессы отправляются в топик Kafka. Также можно отправить сообщения рабочего процесса в Kafka с помощью класса Imixs-Adapter. Эта реализация основана на концепции Imixs-Adapter и позволяет более детально моделировать интеграцию асинхронных сервисов. Адаптер Imixs-Kafka можно настроить непосредственно в модели BPMN 2.0, например, привязав его к событию типа Cигнал.
BPM-платформа от IBM, предназначенная для комплексного управления бизнес-процессами, включающая набор инструментов для их создания, тестирования и развертывания, также поддерживает интеграцию с Apache Kafka. Для этого есть решения от вендора, так и от сторонних разработчиков. Например, проект BPMKafkaIntegration показывает, как запустить определение бизнес-процесса IBM BPM, запускаемое сообщением Kafka. Это позволяет использовать топик Kafka в качестве очереди входящих сообщений и реагировать на входящие сообщения в BPM-системе. Настраиваемая логика обработки сообщений выполняется в общей системной службе.
Служба интеграции ProcessKafkaEventsIntoUCA подключается к настроенному топику Kafka через действие интеграции Java на основе образца коннектора BPMKafkaConnectorSample. Общая системная служба IssueUCA содержит логику, которая решает, каких агентов (Undercover Agents) назначать для каждого входящего сообщения.
Таким образом, Apache Kafka не заменяет BPM-движки, а дополняет их, позволяя расширить классическую оркестрацию и хореографию бизнес-процессов и интеграцию микросервисов сценариями потоковой передачи данных.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://www.kai-waehner.de/blog/2023/05/08/apache-kafka-as-workflow-and-orchestration-engine/
- https://github.com/salesforce/junction-workflow
- https://github.com/kestra-io/kestra
- https://camunda.com/platform/zeebe/
- https://blog.imixs.org/2019/04/19/bpm-with-apache-kafka/
- https://github.com/schwarztho/BPMKafkaIntegration