 675
675 
Хотя Apache Kafka стала стандартом де-факто для потоковой передачи событий, на этой платформе можно реализовать и пакетный режим вычислений. В рамках обучения дата-инженеров, сегодня рассмотрим, как совместить пакетную парадигму обработки Big Data с потоковой, развернув конвейер аналитики больших данных на Apache Kafka.
Пакеты и потоки: versus или вместе
Пакетную и потоковую обработку данных принято противопоставлять друг другу, называя их разными парадигмами. Однако, независимо от режима обработки, конвейеры данных извлекают их из источника, применяя к ним операции преобразования, фильтрации, соединения или агрегирования, чтобы в итоге опубликовать в системе-приемнике.
Пакетные конвейеры данных запускаются вручную или периодически, а время их обработки зависит от размера потребляемых данных и обычно составляет от нескольких минут до нескольких часов, даже с применением методов распараллеливания. Учитывая, что пакетные конвейеры увеличивают нагрузку на источник данных, они часто выполняются в периоды низкой активности пользователей, например, каждую ночь в 2 часа ночи, чтобы не повлиять на другие рабочие нагрузки. Типичные варианты использования пакетных конвейеров предъявляют сложные требования к обработке данных, например, соединение десятков различных источников или таблиц, независимо от времени: отчеты о заработной плате, выставление счетов или сведение исторических данных.
При этом пакетные конвейеры всегда знают весь набор данных в момент начала их выполнения, что упрощает реализацию операций соединения и агрегации, которые должны полностью обращаться к источнику данных. Пакетные конвейеры могут напрямую подключаться к источникам или приемникам данных напрямую, например, с помощью JDBC- драйверов при интеграции СУБД без какого-либо промежуточного уровня между ними.
Обычно пакетные конвейеры не хранят информацию об изменениях данных: им приходится обрабатывать все данные независимо от их изменений с момента последнего запуска. Это может привести к нерациональной трате вычислительных ресурсов. Кроме того, выполнение пакетных конвейеров влияет на производительность используемого источника данных, особенно при работе с очень большими датасетами, т.к. необходимо извлекать все данные сразу. В свою очередь, системы-приемники всегда основаны на состоянии источника данных на момент начала последнего выполнения пакетного конвейера, что может стать причиной неактуальных данных, при высокой частоте их изменений в источнике.
Для решения этой проблемы дата-инженеры строят конвейеры потоковой передачи данных, которые, в отличие от пакетных data pipeline’ов выполняются постоянно и постоянно. Они потребляют потоки сообщений в реальном времени, применяя к сообщениям операции преобразования, фильтрации, агрегирования или соединения, чтобы опубликовать обработанные сообщения в другом потоке. Обработка в реальном времени — это метод непрерывной обработки данных по мере их сбора в течение нескольких секунд или миллисекунд. Системы реального времени быстро реагируют на новую информацию в архитектуре, основанной на событиях.
Обычно потоковые конвейеры развертываются вместе с коннектором источника данных, который заботится об извлечении событий изменения данных из хранилища данных, и коннектором приемника данных, который извлекает обработанные сообщения из потока и публикует их в хранилище.
В таком сценарии поток, создаваемый коннектором источника данных, напоминает журнал изменений источника, содержащий одно сообщение для каждого выполненного события изменения данных: вставки, обновления или удаления. Традиционные очереди сообщений, такие как RabbitMQ, удаляют сообщения после их использования. А современные платформы потоковой передачи событий, такие как Apache Kafka, позволяют хранить сообщения столько, сколько необходимо: в течение определенного периода времени, до заданного объема дискового пространства или вообще всегда. Это не только позволяет восстановить состояние набора данных во время определенного сообщения или события с возможностью их повторной обработки.
Популярные сценарии конвейеров потоковой передачи данных чувствительны ко времени и должны получать представление о самых последних изменениях, произошедших в хранилище. Например, обнаружение мошенничества, критические отчеты, поддерживающие важные операционные решения, мониторинг поведения клиентов или кибербезопасность. Поэтому потоковые конвейеры должны обрабатывать только те данные, которые были изменены, сохраняя все остальные данные нетронутыми и улучшая общее использование вычислительных ресурсов. Это обеспечивает постоянную синхронизацию приемников данных с их источниками, сводя к минимуму разрыв между временем возникновения события изменения в источнике и временем прибытия обработанного события в приемник.
Благодаря коннекторам отслеживания измененных данных на основе журналов, потоковые конвейеры снижают нагрузку на источник данных, т.к. не нужно выполнять полные запросы, а можно извлекать данные из лог-файлов СУБД. При этом потоковые конвейеры должны восстанавливать наборы данных при выполнении операций соединения и агрегирования, производительность которых зависит от сжатия лог-файлов. Поскольку потоковые конвейеры используются вместе с дополнительными коннекторами при потреблении данных из внешних источников или публикации обработанных данных во внешние приемники, это может увеличить операционные издержки на передачу данных.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
24 февраля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
При выполнении пакетных конвейеров с высокой частотой задержка репликации между приемниками и источниками данных сократится и приблизится к задержке потоковых конвейеров. Потоковые конвейеры могут применяться для реализации очень сложных требований интеграции данных, например, соединение десятков таблиц. Но в случае больших наборов данных, это снизит производительность из-за преобразований датасетов и отсутствия методов оптимизации, таких как индексы базы данных. Поэтому на практике дата-инженеры стараются сочетать пакетный и потоковый подходы к построению конвейеров обработки данных, сочетая преимущества обоих режимов. В частности, потоковые конвейеры очень быстро передают данные и могут применять простые преобразования, тогда как пакетные конвейеры отлично работают на сложных вычислениях.
Таким образом, потоковые конвейеры могут использоваться для извлечения данных из операционной СУБД или внешней веб-службы и приема данных в корпоративное хранилище/озеро данных. А пакетные конвейеры применяются для объединения десятков различных таблиц базы данных при подготовке сложных и редко используемых BI-отчетов.
Преимущества потоковой передачи и анализа данных в реальном времени обеспечивают немедленную автоматизацию бизнес-задач. Но системы реального времени требуют непрерывного ввода, обработки и вывода, поэтому достаточно сложны в реализации и поддержке. Кроме того, большинство систем реального времени не умеют обрабатывать исторические данные. Поэтому, чтобы выбрать подходящий режим обработки данных и построить конвейер, отвечающим конкретным потребностям бизнеса, следует определить сценарии обработки, ответив на простой вопрос: насколько свежими должны быть данные? Допустима ли часовая задержка или требуется real-time обработка? На практике данные в реальном времени нужны не из всех источников, а только из некоторых. Как это реализовать средствами Apache Kafka, мы рассмотрим далее. А о других платформах потоковой аналитики больших данных. читайте в нашей новой статье.
Пакетный конвейер на Apache Kafka
На первый взгляд кажется, что переход от пакетной обработки к потоковой не так уж и сложен. Однако, поток данных предполагает бесконечное поступление записей и их обработку в режиме реального времени. А при пакетной обработке итоговое значение создается только после полной обработки всех связанных данных. Поэтому для потоковой обработки полнота и доступность записей особенно важна, как и соблюдение порядка записей, а также предотвращение дублирования. Все это обеспечивает Apache Kafka, которая считается фреймворком №1 в мире потоковой передачи событий. Несмотря на это, понятие пакета в Kafka также присутствует: продюсер группирует все записи, поступающие между передачами запроса, в один пакет размером batch.size, если сообщения приходят быстрее, чем могут быть отправлены. Уменьшить количество запросов можно, добавив искусственную задержку, чтобы вместо немедленной отправки записи продюсер ожидал какое-то время и упаковал несколько сообщений воедино. Параметр linger.ms задает верхнюю границу задержки для пакетной обработки: как только размер сообщений превысит заданный объем пакета batch.size, они будут отправлены немедленно. По умолчанию значение linger.ms равно 0, что означает немедленную передачу сообщений брокерам. Подробнее об этом мы писали здесь, здесь, здесь и здесь.
Курс Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
26 января, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Итак, данные в Kafka хранятся в топиках, которые делятся на разделы. Количество разделов определяет количество потоков данных, которые могут обрабатываться параллельно. Apache Kafka назначает входящие данные одному из этих разделов на основе настраиваемой стратегии. Назначение выполняется ключом партиционирования по умолчанию. Предположим, необходимо реализовать Kafka-приложение, удовлетворяющее следующим требованиям:
- пакет данных всегда должен быть доступным, т.е. принятым в топик полностью, прежде чем начать его обработку. Для этого необходимо знать, к какому пакету принадлежит набор данных, и сколько всего наборов данных содержит этот пакет.
- гарантия строго однократной обработки – ни один пакет не должен обрабатываться дважды или быть пропущенным;
- порядок записей должен быть сохранен.
- в обрабатываемом пакете не должно быть дубликатов.
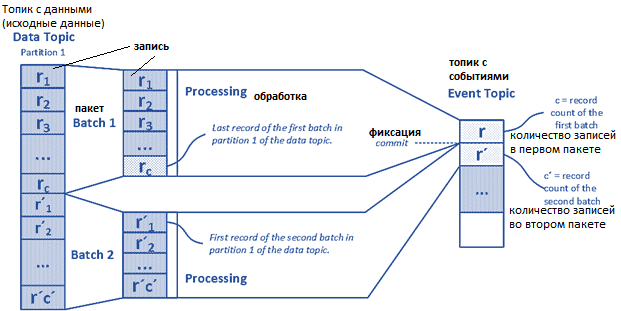
Чтобы фильтровать повторы, записи в пакете нумеруются последовательно. Уникальный идентификатор (UUID) пакета подходит в качестве ключа для отдельных его записей. Однако, если UUID генерируется продюсером Kafka, он становится бессмысленным. В случае ошибки продюсер предоставит уже обработанному пакету новые UUID, сделав невозможной проверку того, какой пакет уже был отправлен в топик. Поэтому лучше выбрать идентификатор, который останется стабильным даже после повторной обработки пакета и может быть связан с исходными данными источника, даже при перезапуске продюсера. Чтобы потребитель знал, что весь пакет, то есть все его записи, находятся в конкретном разделе конкретного топика, соответствующая запись публикуется в топике события.
Таким образом, имя пакета является ключом записей, а нумерация отдельных записей зависит от источника исходных данных, которые следует передать как пакет, например, номер строки в CSV-файле. Пакет должен получить тот же идентификатор, даже если создается и запускается новый продюсер в случае ошибки. Это предотвратит повторную публикацию записей в Apache Kafka и упростит отслеживание операций.
Пронумерованные записи пакета публикуются в топике с данными как часть транзакции. Положение первой записи и раздела публикуется в последней записи в той же транзакции в топике события, и транзакция закрывается. Использование транзакции позволит потребителям избежать неполных данных в случае ошибки. Для отслеживания прогресса продюсера, помимо топика с событиями, можно переименовать файл по завершении записи.
Часто при использовании топика с событиями необходимо скорректировать срок их хранения. Например, если статус обработки управляется топиком события, необходимо убедиться, что связанная запись из него не удалится до того, как исходный файл будет удален или заархивирован. Иначе продюсер будет считать исходный файл не обработанным.
Настройка потребителя проще, чем продюсера: потребитель прослушивает новые записи в топике событий и при появлении новой записи переходит к топику данных. Связанные записи идентифицируются ключом (идентификатор события) и используются последовательно. А дубликаты фильтруются по идентификатору отдельной записи. Обработка всех данных начинается, как только будет получена последняя запись в результате сравнения записей пакета с количеством уже доступных записей.
Чтобы избежать подтверждения записей до того, как пакетная обработка будет полностью завершена, следует отключить автоматическое подтверждение, которое активировано по умолчанию для потребителя: enable.auto.commit = false. Теперь потребитель вручную будет подтверждать успешную обработку записи топика событий после завершения пакетной обработки. После этого все связанные данные завершенного пакета следует удалить из памяти.
Если потребуется повторная обработка пакета, можно просто скопировать запись исходного пакета в топик событий и создать ее как новую запись данных, чтобы потребитель обработал ее снова. Чтобы избежать отдельного топика с событиями, можно изменять положение смещения потребителя извне. Однако, если пакет, который следует повторно обработать, не является последней записью в топике, то все последующие пакеты, которые уже были обработаны, тоже будут снова обработаны. Также пострадает прослеживаемость этой процедуры, поэтому применять такое решение на практике не рекомендуется.
В случае ошибки, которая не решается повторными попытками, например, неправильные записи данных или ошибки синтаксического анализа, пакет должен быть подтвержден как обработанный. Иначе возможен останов цепочки процессов: пакет будет бесконечно передаваться Apache Kafka до тех пор, пока он не будет обработан. Поэтому имеет смысл выявлять все ошибки, которые могут возникнуть во время обработки пакета, чтобы предотвратить сбой потребителя и повторный запуск обработки того же ошибочного пакета. О выявленной ошибке можно сообщить извне, отразить ее в логах или поместить в специальный раздел.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
2 февраля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Таким образом, Apache Kafka позволяет реализовать классическую пакетную обработку, используя преимущества потоковой передачи данных: надежность, масштабирование и партиционирование. А также предотвратить типовые проблемы пакетной обработки файлов, связанные с обнаружением ошибок, с помощью средств мониторинга данных. После того, как данные будут доступны в Apache Kafka, в режиме реального времени можно анализировать их вручную или автоматически, создавать подробные отчеты и обрабатывать записи данных.
Узнайте больше интересных примеров администрирования и эксплуатации Apache Kafka для разработки распределенных приложений потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

