Дополняя наши курсы для дата-инженеров по Apache AirFlow полезными примерами, сегодня поговорим про сложности управления зависимыми конвейерами данных в этом batch-оркестраторе. Как решить проблемы связанных DAG’ов в AirFlow и в альтернативном фреймворке Prefect.
Все сложно: управление зависимыми DAG в Apache Airflow
Apache AirFlow считается одним из самых популярных инструментов современной дата-инженерии, позволяет автоматизировать запуск и выполнение процессов обработки данных в рамках связанных конвейеров. Это особенно востребовано в области Big Data, например, для организации ETL/ELT-процессов при работе с корпоративными озерами и хранилищами данных. Даже в рамках одной компании направленные ациклические графы задач (DAG) Airflow охватывают множество бизнес-процессов и структур. Поэтому проблема управления жизненным циклом производственных развертываний Airflow актуальна для дата-инженеров.
Apache Airflow не случайно считается одним из самых востребованных инструментов современного дата-инженера. Он позволяет автоматизировать запуск и выполнение процессов обработки данных в рамках связанных конвейеров, представленных в виде DAG (Directed Acyclic Graph) – цепочки задач для запланированного запуска по расписанию в виде направленного ациклического графа. В случае нескольких бизнес-процессов подобный конвейер становится очень большим и плохо управляется. Но разделение крупного конвейера на множество мелких не слишком снижает сложность управления из-за особенностей самого AirFlow. Хотя Airflow управляет зависимостями между задачами в рамках одного DAG, он не обеспечивает механизма для взаимозависимостей между DAG’ами. О том, как подобную проблему решила бразильская ИТ-компания QuintoAndar, разработав собственный компонент, мы писали здесь.
Чтобы не изобретать собственный велосипед, можно попробовать типовые возможности самого AirFlow:
- подграфы (SubDags). Но один SubDag интерпретируется как один узел DAG в родительском конвейере данных, даже если дочерний SubDag состоит из многих задач. Поэтому каждая задача из дочернего DAG выполняется последовательно, приводит к взаимоблокировкам в процессах планирования.
- ExternalTaskSensor – датчик в родительском конвейере, который регулярно проверяет состояние выполнения дочернего DAG. Но это работает только, если расписания между родительским DAG и дочерним DAG выровнены, что не всегда возможно. Например, если родительский конвейер активировать вручную, он будет работать вечно, пока не истечет время ожидания, т.к. у дочернего DAG’а другое расписание.
- TriggerDagRunOperator – оператор, который позволяет пользователям получать доступ к DAG, запускаемому задачей. Так можно запустить дочерний DAG из родительского, избегая риска возникновения тупиковых ситуаций и запуска конвейера вне графика, например, через ручной триггер. Но в этом случае родительский DAG не дожидается завершения запущенного дочернего перед запуском следующей задачи.
Таким образом, имеющиеся возможности AirFlow не удовлетворяют все потребности дата-инженера по управлению зависимостями между конвейерами данных. Для иллюстрации этого утверждения рассмотрим пример родительского ETL-конвейера из 3-х задач: сбор данных в staging-область, преобразование по правилам бизнес-логики и выгрузка в дэшборд BI-системы. Задача преобразования (бизнес-логика) декомпозирована на несколько задач в дочернем DAG’е. Использование TriggerDagRunOperator для уровня бизнес-логики в родительском DAG вызовет запуск дочернего конвейера (DagRun) и немедленно запустит задачу дэшборда в родительском, не дождавшись завершения всех задач бизнес-логики в дочернем DAG.
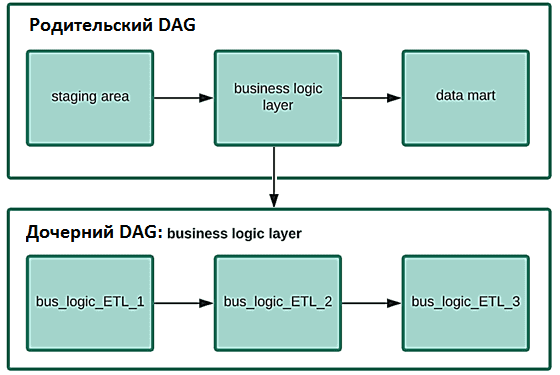
Избежать этого можно следующим образом:
- добавить фиктивное завершение задачи в конце каждого дочернего DAG;
- реализовать датчик WaitForCompletion, который проверяет в базе метаданных Airflow состояние последнего DagRun дочернего DAG. Идентифицировать этот последний DagRun дочернего DAG’а можно по названию, например, он должен начинаться с «trig__», как любой DagRun, запускаемый внешним DAG’ом. Далее можно просортировать эти DagRun по дате выполнения в порядке убывания и взять первый в получившемся списке, т.е. самый последний по времени запуска.
- внутри датчика WaitForCompletion можно узнать состояние финишной задачи в последнем DagRun. В случае успеха датчик завершает задачу и может перейти к задаче дэшборда в родительском конвейере. Иначе задача все еще выполняется или потерпела сбой, т.е. перейти к следующей задаче в родительском конвейере нельзя.
Реализовать эту идею можно проще и быстрее, если вместо AirFlow использовать альтернативную систему управления рабочими процессами Prefect. Прежде чем погружаться в особенности Prefect, рассмотрим, что представляет собой этот фреймворк.
Что такое Prefect и при чем здесь управление workflow
Prefect Core – это система управления рабочими процессами, который упрощает использование конвейеров данных и добавление семантики, включая повторные попытки, логирование, динамическое сопоставление, кэширование, уведомления об ошибках и пр. Prefect преобразует пользовательский код в надежный распределенный конвейер, не меняя существующие инструменты, языки, инфраструктуру и сценарии. Prefect создает богатую структуру DAG и предоставляет функциональный API для преобразования скриптов, позволяя получить доступ к графу напрямую. Также Prefect включает большой набор модульных тестов и подробную документацию, включая аннотации типов.
В Prefect задачи могут получать входные и выходные данные, а система прозрачно управляет этими зависимостями, почти никогда не записывая их в свою базу данных. Вместо хранения результатов пользователям предоставляется возможность безопасного управления логикой их обработки. Этот подход дает следующие преимущества:
- возможность писать код, используя знакомые шаблоны Python;
- зависимости известны движку, поэтому их нельзя пропустить. Это обеспечивает более прозрачную отладку.
- поддержка шаблонов в стиле AirFlow;
- прямой обмен данными между задачами позволяет поддерживать более сложную логику ветвления и различные состояния задач, а также обеспечивает более строгий контракт между задачами и запусками в потоке данных.
Развивая основные идеи Apache AirFlow, Prefect включает множество дополнительных полезных абстракций. Например, FlowRunTask с параметром wait. Установка этого параметра в значение True аналогична WaitForCompletion в Airflow, но без необходимости использовать датчик для периодического поиска в базе данных. Это будет запускать дочерний поток и дожидаться его завершения, прежде чем переходить к следующей задаче родительского DAG. Благодаря наличию инструмента визуализации, в Prefect можно посмотреть движение задач по конвейеру данных.
Чтобы корректно структурировать и запланировать родительско-дочерние зависимости DAG’ов, достаточно планировать только родительские data pipelines, из которых будут запускаться дочерние потоки. Это упрощает возможность менять уровень бизнес-логики, позволяя добавлять к нему задачи и вносить изменения без влияния на другие. Не нужно ничего менять в расписании, а риск попасть в тупик отсутствует. В отличие от AirFlow, в Prefect не нужно было писать какую-либо настраиваемую логику датчика, чтобы отражать зависимости между конвейерами данных. О том, чем AirFlow Отличается от Apache Beam и можно ли использовать их совместно, читайте в нашей новой статье.
Код курса
ADH-AIR
Ближайшая дата курса
Продолжительность
ак.часов
Стоимость обучения
0
Узнайте больше про администрирование и эксплуатацию Apache AirFlow для эффективной по организации ETL/ELT-процессов в аналитике больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

