
2022 год только начался, а John Snow Labs уже радует разработчиков ML-приложений новым релизом библиотеки Spark NLP. Ключевые фичи 3.4.0 для версии Apache Spark 3.2.x на Scala 2.12: новые GPT-2 трансформеры, аннотаторы для ALBERT, XLNet, RoBERTa, XLM-RoBERTa и Longformer, расширенный хаб готовых Machine Learning моделей и конвейеров, а также исправление...

В этой статье для разработчиков Spark-приложений и дата-инженеров рассмотрим особенности взаимодействия с облачным объектным хранилищем больших данных AWS S3. Как повысить эффективность и ускорить выполнения Spark-заданий на чтение данных из S3: рекомендации Pinterest. Пара советов по работе Apache Spark с AWS S3 Прежде чем перейти к опыту дата-инженеров фотохостинга Pinterest,...

Чем хороши JSON-файлы и как с ними работать в Apache Spark и Hive: проблемы обработки вложенных структур данных и способы их решения на практических примерах. Как автоматизировать переименование некорректных названий полей во вложенных структурах данных JSON-файлов на любом количестве таблиц со множеством полей, чтобы создать таблицу в Hive Metastore и...
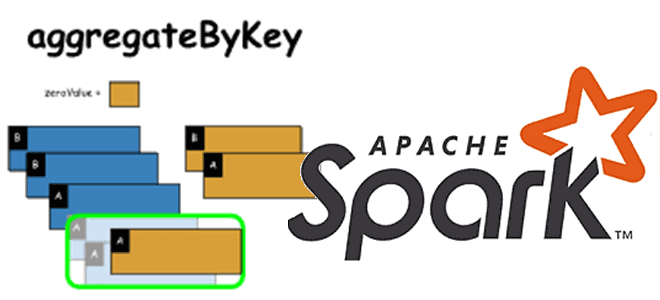
В рамках обучения дата-аналитиков и разработчиков Spark-приложений, сегодня рассмотрим одну из агрегатных функций обработки данных в этом распределенном вычислительном фреймворке. Чем aggregateByKey() отличается от reduceByKey() и groupByKey(), и когда стоит ее использовать. Как устроена функция aggregateByKey(): назначение и синтаксис Функция aggregateByKey() - одна из агрегатных функций, наряду с reduceByKey() и...

Добавляя новые интересные примеры в наши курсы для дата-аналитиков, разработчиков распределенных приложений и администраторов SQL-on-Hadoop, сегодня рассмотрим опыт видеоаналитики в компании Vimeo с использованием Apache Spark. Как быстро запросить множество данных из Apache HDFS через Phoenix и Spark из моментальных снимков HBase с минимальным влиянием на кластер. Аналитика очень больших...

Сегодня рассмотрим кейс международной ИТ-компании AppsFlyer, которая создает SaaS-решения для маркетинговой аналитики в режиме онлайн. В этой статье команда разработки аналитического продукта Data Locker делится опытом оптимизации ETL-приложений Apache Spark для снижения стоимости обработки данных и ускорения вычислений. Предыстория: слишком много файлов в ETL-решении на Spark и AWS S3 в...

В рамках обучения разработчиков Spark-приложений и дата-инженеров, сегодня рассмотрим, что такое локальность данных и как это влияет на производительность заданий. А также разберем, где в UI Apache Spark посмотреть нахождение данных для распределенных вычислений и какие параметры конфигурации следует настроить, чтобы повысить скорость их выполнения. Что такое локальность данных в...
В начале декабря 2021 года мир ИТ взволновала новость о критической уязвимости CVE-2021-44228 в библиотеке Apache Log4j. Разбираемся, что это такое и чем опасно для систем хранения и аналитики больших данных на Apache Hadoop, Kafka, Spark, Elasticsearch и Neo4j. Критическая уязвимость в библиотеке Apache Log4j: чем опасна CVE-2021-44228 9 декабря...
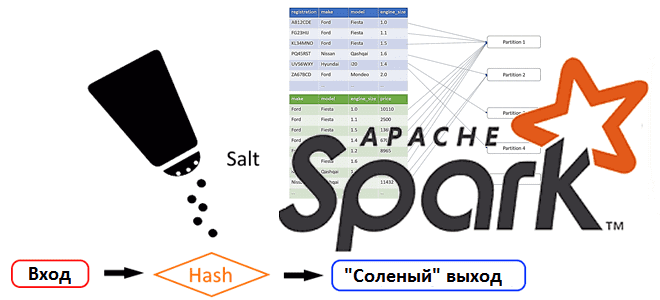
В этой статье для разработчиков Spark-приложений рассмотрим, как избежать искаженных данных с помощью простого и давно известного в криптографии приема, который принято называть «соль». Почему неравномерное распределение данных может вызвать ошибку нехватки памяти и как сбалансировать распределение ключей, добавив столбец со случайными числами. Перекосы и перемешивания Искажение или неравномерное распределение...
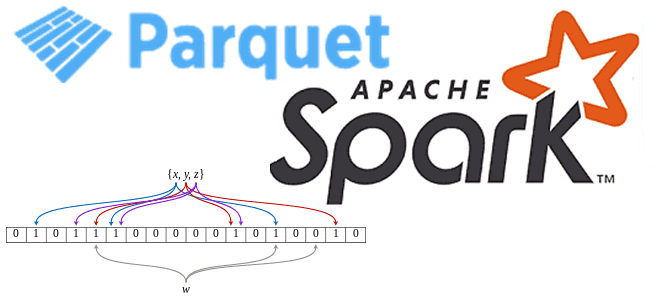
Сегодня рассмотрим, что такое фильтр Блума и как эта структура данных используется в Apache Spark для чтения Parquet-файлов. Про хеширование, UUID, достоинства и недостатки Bloom-фильтра для бинарного колоночного формата хранения больших данных в распределенных системах. Что такое фильтр Блума Фильтр Блума активно используется во многих информационных системах для быстрого поиска...
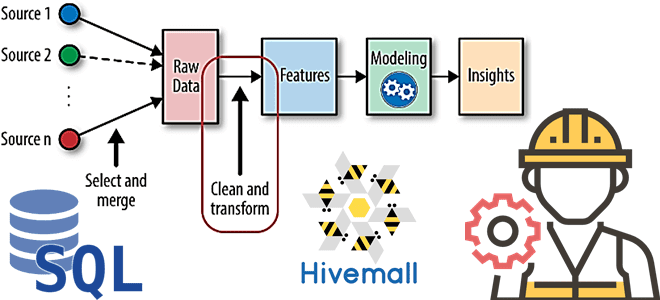
В рамках наших курсов для дата-инженеров и специалистов в области Data Science, сегодня рассмотрим, как реализовать один из важнейших этапов машинного обучения – Feature Engineering. Читайте далее, как генерировать признаки для ML-модели с помощью SQL, напрямую обращаясь к источникам данных и хранилищам фич, а также что такое Apache Hivemall и...

В этой статье для разработчиков распределенных приложений разберем проблему с производительностью Apache Spark из-за неоптимальной стратегии переброса данных между оперативной и постоянной памятью. Что такое spill-эффект, почему он случается, как его идентифицировать и устранить. Что такое spill и почему он случается: под капотом Spark-приложений При том, что spill можно рассматривать...
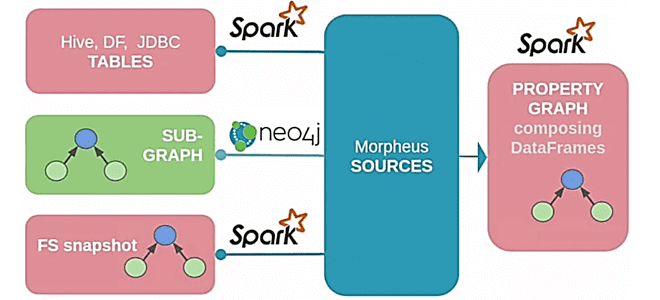
В рамках нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, как язык запросов Cypher должен был появиться в Apache Spark 3.0, зачем это нужно и почему до сих пор не реализовано. Краткая история проекта Morpheus, его связь с Neo4j, а также модулями Spark GraphX и GraphFrames. Что такое Morpheus...
Добавляя в наши курсы для дата-инженеров еще больше полезных примеров, сегодня рассмотрим, как Airbnb развивает Apache AirFlow и на практике используют эту платформу для создания, планирования и мониторинга конвейеров данных. Что такое Smart Sensor и как умные датчики экономят ресурсы на выполнение долгосрочных легковесных задач. Легкие, долгие и ресурсоемкие: проблемы...

Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня заглянем под капот коннектора Neo4j к Apache Spark. Сценарии использования, принципы работы, поддержка потоковой передачи Spark и другие новинки версии 4.1 для построения эффективных аналитических коннекторов с помощью алгоритмов на графах. Как работает коннектор Neo4j к Apache Spark: краткий обзор Осенью...
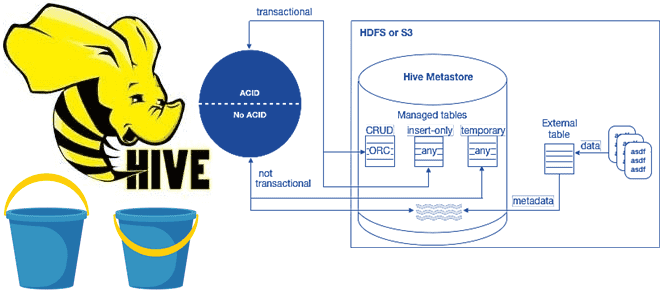
В рамках обучения аналитиков данных и дата-инженеров тонкостям работы с Apache Hive, сегодня разберем особенности ACID-транзакций в этом популярном инструменте класса SQL-on-Hadoop. Зачем и когда нужны ACID-транзакции в Apache Hive, какие параметры нужно настроить для их выполнения, при чем здесь блокировки, каковы ограничения и особенности уплотнения дельта-каталогов. Еще раз про...

Apache AVRO не случайно считается очень востребованным форматом и популярной системой сериализации данных, который активно в Kafka. Сегодня рассмотрим, как сериализуются данные в AVRO, каким образом это связано со структурами JSON и при чем здесь реестр схем Confluent. Еще раз про AVRO и сериализацию данных Apache Kafka часто используется в...
В этой статье для дата-аналитиков и разработчиков распределенных приложений рассмотрим несколько распространенных ошибок, которые можно сделать в PySpark-коде. Когда PySpark-код на DataFrame DSL лучше запросов Spark SQL, как изящно решить проблему длинных строк, почему пользоваться функцией cache() надо осторожно, а также откуда появляются NULL-значения при внешних соединениях потоковых таблиц. Spark...

В начале сентября 2021 года вышел 3-й релиз языка программирования Scala, который разработчики называют полностью переработанным из-за модернизации системы типов и добавления новых функций. Текущая версия Apache Spark 3.2.0, выпущенная месяцем позже, поддерживает Scala 2.13 и 3.0 с ограничением некоторых возможностей. Читайте далее, как разработчикам распределенных Spark-приложений писать задания на...
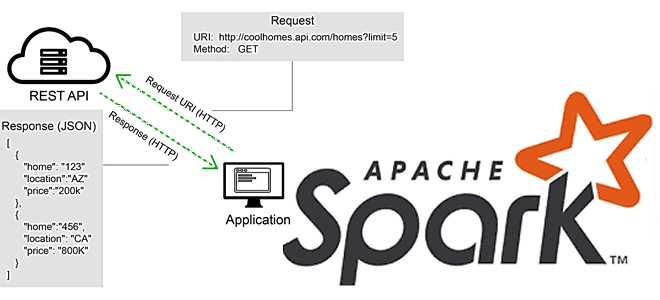
В этой статье для разработчиков Apache Spark разберем, что не так с вызовами REST API в этом фреймворке, и как решить эту проблему с помощью готовых библиотек или создания собственных UDF-функций на PySpark и не только. Для наглядности рассмотрим практический пример вызова REST API на PySpark с библиотекой Rest Data...