
В рамках обучения разработчиков Spark-приложений и дата-инженеров, сегодня рассмотрим, как повысить эффективность выполнения Python-кода с помощью кросс-языковой платформы Apache Arrow. Что такое PyArrow и как это улучшает производительность PySpark-программ. Почему Spark Java быстрее PySpark и как это исправить с Apache Arrow Будучи популярным вычислительным движком в области Big Data, Apache...

Постоянно добавляя в наши курсы по Apache Spark и машинному обучению практические примеры для эффективного повышения квалификации Data Scientist’ов и инженеров данных, сегодня рассмотрим задачу пакетного прогнозирования и планирование ее запуска по расписанию без применения масштабных MLOps-решений. Apache Spark для пакетного прогнозирования Есть много готовых решений и инструментов для пакетного...
Обучая специалистов по Data Science, аналитиков и инженеров данных лучшим практикам MLOps, сегодня поговорим про переносимость моделей машинного обучения между разными этапами жизненного цикла ML-систем, от разработки до развертывания в production. А в качестве примера разберем, как использовать обученную ML-модель из Apache Spark за пределами кластера, упаковав ее в ONNX...
Недавно мы писали про обновление хранилища метаданных Apache Hive с помощью команды MSCK REPAIR TABLE, операторов AirFlow и Spark-заданий. В продолжение этой темы про работу с партиционированными Parquet-файлами сегодня рассмотрим применение Spark SQL для этого случая, чтобы использовать таблицу Hive вместо временного представления Spark. Временные таблицы Hive/Spark и разделы в Parquet-файлах...

Как снизить затраты на AWS EMR, сохранив эффективность Spark-конвейеров обработки данных на спотовых инстансах и других типах узлов облачного кластера. Также рассмотрим, что такое прерываемые виртуальные машины в Яндекс.Облаке и каким образом настроить такую облачную инфраструктуру, чтобы сократить затраты на выполнение Spark-приложений, одновременно повысив их отказоустойчивость. Блеск и нищета спотовых...

В рамках обучения дата-инженеров и разработчиков Spark-приложений сегодня рассмотрим, как повысить эффективность обработки данных, используя всю мощь этого распределенного движка. Проблемы производительности и эффективности конвейера обработки данных с учетом разницы между действиями и преобразованиями в Apache Spark. Снова про разницу между действиями и преобразованиями в Apache Spark Основное преимущество Apache...

В этой статье для дата-инженеров и разработчиков распределенных приложений потоковой аналитики больших данных разберем пример перевода сервиса Strava с кластера Cassandra в облачное хранилище AWS S3 и какую роль в этом сыграл вычислительный движок Apache Spark. Постановка задачи: слишком дорогая Cassandra Strava – это глобальный сервис отслеживания активности велосипедистов, бегунов...

Практический пример аналитики больших данных в реальном времени с Apache Spark, Kafka, ClickHouse и AWS S3: возможности, архитектура, также специально для дата-инженеров и разработчиков распределенных приложений рассмотрим, сколько времени нужно для разрешения каждого вызова API в определенном временном диапазоне. Анализ событий пользовательского поведения в реальном времени Основным продуктом международной ИТ-компании...
Сегодня рассмотрим, как загружать большие объемы данных из REST API-сервисов с Apache Spark, написав на PySpark собственную UDF-функцию с преобразованием withColumn(), чтобы воспользоваться всеми преимуществами распределенных вычислений этого фреймворка. Локальное исполнение на драйвере и распараллеливание REST-API вызовов в Apache Spark Мы уже рассказывали, что конвертация Python-скрипта в распределенный код Apache...

Как организовать удобный мониторинг за приложениями Apache Spark в кластере Kubernetes с помощью Prometheus и Grafana: пошаговый guide для администраторов и дата-инженеров с примерами. Создаем свою альтернативу наглядным дэшбордам AWS EMR с Java-библиотекой Dropwizard Metrics и средством настройки оповещений Alertmanager. Не только AWS EMR или как следить за Spark-приложениями в...

В рамках обучения дата-инженеров и ML-специалистов лучшим практикам MLOps, сегодня рассмотрим практический пример построения конвейера машинного обучения на Airflow, MLFlow, SageMaker и других сервисах Amazon. А также как Apache Spark версии 3 сократил расходы на облачный EMR-кластер почти в 2 раза. MLOps с AirFlow и MLFlow в облаке AWS Ранее...

В этой статье для дата-инженеров и аналитиков рассмотрим пример мониторинга состояния электрогенераторов с помощью анализа данных временных рядов и ранжирования в pandas для предупреждения выхода оборудования из строя. А также разберем основы анализа временных рядов на больших данных с открытой библиотекой Flint для Apache Spark. Постановка задачи: температура и производительность...
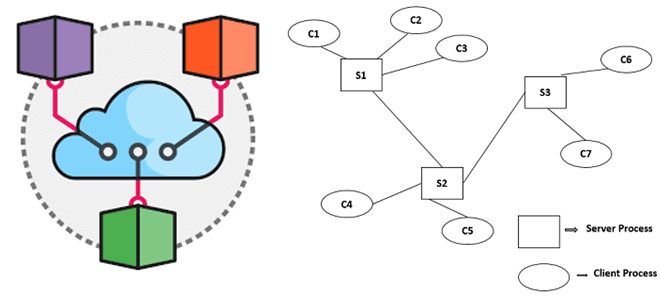
Недавно мы писали про архитектурный шаблон CQRS и его реализацию на базе Apache Kafka. В продолжение этой темы для обучения ИТ-архитекторов и разработчиков Big Data приложений, сегодня рассмотрим еще несколько популярных шаблонов проектирования распределенных систем: достоинства, недостатки, примеры реализации и способы их использования. Шаблоны проектирования распределенных систем: что это и...

Развивая наши курсы по Apache Spark и AirFlow для дата-инженеров и администраторов кластеров, сегодня рассмотрим кейс крупного маркетплейса Joom по переходу от 2-ой версии фреймворка на облачной платформе EMR к развертыванию сотен распределенных заданий на 3-ей версии в Amazon Elastic Kubernetes Service. Про сокращение расходов, повышение производительности и апдейт вычислительных движков. Постановка...
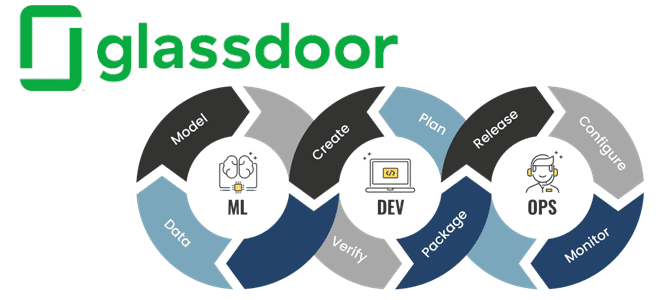
Практическая реализация MLOps-концепции на примере международной рекрутинговой компании Glassdoor. Как построить самоуправляемую автоматизированную систему разработки и сопровождения ML-моделей с MLFlow, Apache Spark и AirFlow, Kubernetes, GitLab, SageMaker Feature Store, Whylogs, Jenkins, Spinnaker и Prometheus с Grafana. Предыстория: зачем MLOps в Glassdoor Glassdoor с 2008 года помогает соискателям по всему миру...

Чтобы сделать наши курсы по Apache Spark еще более полезными, сегодня разберем 2 варианта решения типовой задачи инженерии данных. Как быстро и эффективно считать данные из множества CSV-файлов с одинаковой схемой за несколько строк кода на PySpark. Постановка задачи: рутинная работа с CSV-файлами Наряду с JSON-файлами, про которые мы писали...
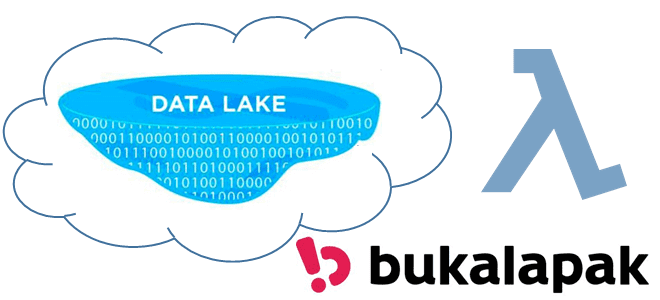
Сегодня обсудим ключевые тренды развития дата-инженерии и инструментальные средства их реализации. Как это применяется на практике, рассмотрим на примере эволюции хранилища данных в индонезийской ИТ-компании Bukalapak, от локального кластера Apache HBase до Лямбда-архитектуры в облаке Google Cloud Platform с Kafka, Spark и AirFlow. 7 главных драйверов развития дата-инженерии В наши...

Недавно мы писали про сложности обработки вложенных структур данных в JSON-файлах при работе с Apache Hive и Spark. В продолжении этой темы про парсинг, сегодня поговорим, как быстро преобразовать данные формата JSON в простой читаемый файл CSV или плоскую таблицу, чтобы анализировать их с помощью типовых методов DataFrame API или...

Чтобы сделать наши курсы для дата-инженеров еще более интересными, сегодня рассмотрим практический пример построения инфраструктуры для автоматической диагностики и исправления ошибок пакетной и потоковой обработки данных в Netflix. Комплексная система на базе Apache Spark, Kafka, Flink, Druid, сервисов AWS и других технологий Big Data. Предыстория: зачем Netflix разработал Pensive Обработка...

В рамках обучения разработчиков распределенных Spark-приложений, сегодня рассмотрим, как добавить функции из пользовательских JAR-файлов в кластер AWS EMR. Достоинства и недостатки действия начальной загрузки EMR с переопределением конфигурации Spark, а также расширенное управление зависимостями через spark-submit. Трудности обращения к пользовательским JAR в Amazon EMR с Apache Spark и Livy На...