
Чтобы добавить в наши практические курсы по Apache Spark еще больше приемов, полезных для дата-инженеров и разработчиков, сегодня рассмотрим, как упаковать PySpark-приложение, используя нативные Python-функции и сторонние решения. Отличия Virtualenv от PEX и Conda. 4 способа упаковать PySpark-приложение для запуска в кластере Apache Spark Разработчики распределенных приложений знают, что недостаточно...
При том, что большинство современных озер данных представляют собой облачные объектные хранилища типа AWS S3, многие предприятия хранят данные в собственном кластере HDFS или даже MinIO. Поэтому сегодня специально для обучения дата-инженеров и ИТ-архитекторов рассмотрим, что представляет собой это хранилище и насколько хорошо с ним взаимодействует Apache Spark. Что такое...
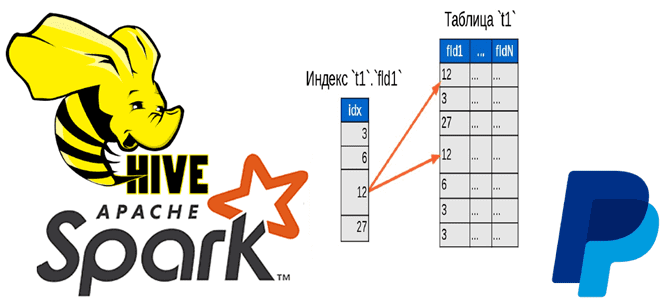
Чтобы добавить в наши курсы по Apache Hadoop и Spark еще больше интересных примеров, сегодня рассмотрим кейс компании PayPal, которой удалось ускорить работу Hive с помощью open-source библиотеки Dione. Зачем индексировать данные в HDFS и как это сделать быстро. Трудности бакетирования в Hive и Spark Вычислительный движок Apache Spark отлично...

Мы уже писали, что технологии Big Data ориентированы на работу с большими данными, а не множеством маленьких. Сегодня рассмотрим подробнее, почему Apache Hadoop, Spark и основанные на HDFS NoSQL-СУБД Hive и HBase плохо работают с большим количеством маленьких файлов, а также как это исправить. Почему HDFS плохо работает со множеством...

Мы регулярно добавляем в наши курсы по Apache Flink и Spark для дата-инженеров полезные материалы и инструменты, которые помогают повысить эффективность разработки и эксплуатации приложений аналитики больших данных. Читайте далее, что такое SeaTunnel и как эта высокопроизводительная платформа интеграции распределенных данных упрощает их потоковую синхронизацию средствами SQL-заданий Apache Flink и...

В этой статье для дата-инженеров и разработчиков распределенных приложений рассмотрим, что такое динамическое партиционирование таблиц в Apache Spark, зачем это нужно и как реализовать такие вставки разделов. Разбираем на практическом примере. Что такое динамическое партиционирование в Apache Spark Партиционирование – это разделение данных на основе значения столбца и их сохранение...

Сегодня рассмотрим особенности использования оператора LIMIT в Spark SQL: как он выполняется и почему вместо него лучше использовать оператор TABLESAMPLE. Для этого в рамках обучения дата-инженеров, разработчиков распределенных приложений и аналитиков данных заглянем под капот оптимизатора Catalyst в Apache Spark и сравним физические планы выполнения SQL-запросов. Недостатки оператора LIMIT в...

Недавно мы писали про Lakesoul – новое унифицированное решение для хранения потоковых и пакетных таблиц, которое реализует архитектуру данных LakeHouse. Сегодня заглянем под капот этого унифицированного механизма на базе Apache Spark и разберемся с преимуществами его последнего релиза. Как работает LakeSoul: краткий обзор Напомним, LakeSoul от команды DMetaSoul представляет собой...
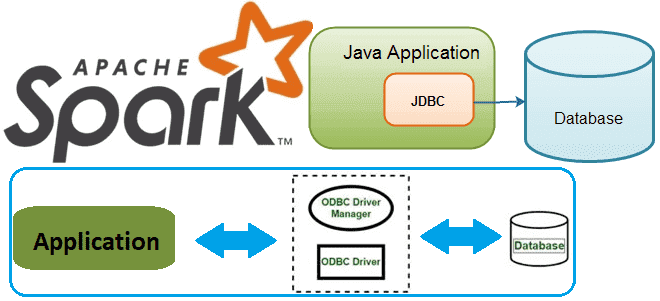
В этой статье для разработчиков распределенных приложений и дата-инженеров разберем, как Spark-задание может подключиться к базе данных через JDBC и ODBC драйверы. В качестве примера рассмотрим код на PySpark и Python-библиотеки pyodbc, а также JDBC-коннекторы в Spark SQL. Доступ к БД из кластера Spark с ODBC-драйвером Напомним, получить соединение с...

Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, что такое Nebula Graph и как использовать мощные возможности обработки графов этой NoSQL-СУБД в сочетании с Apache Spark, одним из самых популярных механизмов анализа данных. Что такое Nebula Graph и как это работает Nebula Graph — это...

Сегодня рассмотрим новое унифицированное решение для хранения потоковых и пакетных таблиц, созданное на основе Apache Spark. Что такое Lakesoul, чем это лучше Apache Iceberg, Hudi и Deta Lake. Также разберем, в чем конкурентные преимущества этого табличного хранилища по сравнению с этими форматами открытых таблиц, включая поддержку upsert, управление метаданными и...

Постоянно добавляя в наши курсы для дата-инженеров и разработчиков распределенных Spark-приложений интересные примеры, сегодня мы хотим поделиться с вами простыми, но эффективными приемами, как улучшить производительность этого вычислительного движка. Чем метод take() лучше collect() в Apache Spark, какие открытые инструменты помогут выполнить профилирование кода и как быстро прочитать множество маленьких...
Чтобы добавить в наши курсы для дата-инженеров и разработчиков распределенных приложений еще больше практических примеров, сегодня рассмотрим, как написать Python-код для вычисления задержки потребителя Apache Kafka, расширив типовой слушатель StreamingQueryListener, который есть в Java и Scala API библиотеки Spark Structured Streaming, но недоступен в PySpark. Проблема отставания потребителя Apache Kafka...

Как Cluster Autotuner от Sync для автонастройки кластера Spark в AWS EMR помог edtech-компании Duolingo снизить затраты на 55%. Полезный сервис для дата-инженера и администратора кластера, чтобы устранить неэффективную ручную настройку, обеспечив оптимальную стоимость, производительность и надежность распределенных вычислений без изменения кода. Дорогой Apache Spark на AWS EMR Duolingo –...

Постоянно добавляя в наши курсы по Apache Spark полезные материалы, сегодня мы рассмотрим, что происходит под капотом этого вычислительного движка, чтобы помочь разработчикам распределенных приложений и дата-инженерам повысить его эффективность. Тонкости сериализации данных, компиляции SQL-запросов в JavaBytecode и сборка мусора. 2 библиотеки сериализации данных в Apache Spark В распределенных системах...

28 июня 2022 года в сотрудничестве с сообществом разработчиков Apache Spark компания Databricks анонсировала проект Lightspeed, новое поколение этого потокового движка. Читайте далее, что это такое и чем оно отличается от классического Apache Spark Structured Streaming. Потоковая обработка данных с Apache Spark Structured Streaming Потоковая передача событий весьма востребована современным...
Чтобы добавить в наши курсы для дата-инженеров и специалистов по Machine Learning еще больше практических примеров, сегодня рассмотрим, как построить ETL-конвейер для преобразования речи в текст с использованием Apache Kafka, Airflow и Spark. А также познакомимся с популярными фреймворками и готовыми сервисами распознавания речи. ETL-конвейер распознавания речи: используемые технологии Предположим,...

Сегодня разберемся, когда для Data Science-проектов вместо Apache Spark, самого популярного вычислительного движка аналитики больших данных, стоить выбрать Dask – легковесную Python-библиотеку для параллельных вычислений. И, наоборот, в каких случаях инженер данных и Data Scientist получают преимущества, выбирая Spark. Что такое Dask и зачем он нужен Data Scientist’у Прежде чем...
Недавно мы говорили про трудности наблюдаемости данных вообще и возможности мониторинга их происхождения в Apache Spark. Сегодня рассмотрим, зачем дата-инженеру прерывать DAG lineage в Spark-приложениях и как это сделать. Что такое DAG lineage и зачем его прерывать? Напомним, Apache Spark использует концепция DAG для выполнения распределенных вычислений. Направленный ациклический граф...

16 июня 2022 года вышла новая версия Apache Spark – 3.3.0. Разбираем главные фичи этого минорного релиза, особенно важные для дата-инженера и разработчика распределенных приложений: от расширения поддержки ANSI SQL до профилирования UDF на Python. Главные изменения Apache Spark 3.3.0 Apache Spark 3.3.0 — это четвертый релиз линейки 3.x, в...