
Мы уже писали, как ускорить выполнение заданий Spark SQL по чтению данных из JDBC-источников. В продолжение этой важной темы для обучения дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим, зачем настраивать опции функции spark.read() и как это сделать наиболее эффективно. Скорость выполнения SQL-запросов и параметры чтения данных из JDBC-источников в Apache...

Чем задание в Spark-приложениях отличается от задачи, зачем нужны этапы и при чем здесь драйверы с исполнителями. Разбираемся с основами разработки в самом популярном движке для распределенных вычислений: ликбез для дата-инженеров. Основные концепции Spark-приложений Приложение Spark — это программа, созданная с помощью Spark API и работающая в совместимом с этим...

Интерактивные блокноты Jupyter стали фактически стандартом де-факто для Data Scientist’ов, использующих Python. Многие дата-инженеры и разработчики Spark тоже используют этот легковесный, но очень удобный инструмент. Однако, чтобы применять его для промышленной разработки Big Data приложений, нужно подключить сервер Jupyter к кластеру Spark. Читайте, как это сделать, если кластер Apache Spark...
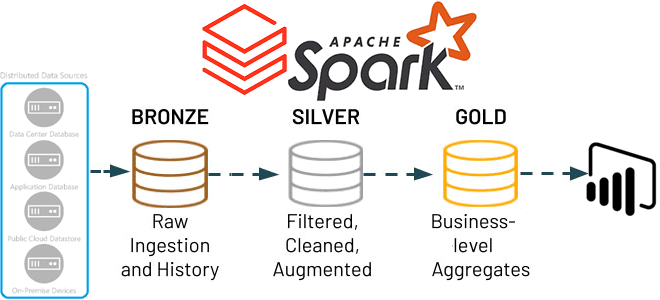
В этой статье для обучения дата-инженеров и ИТ-архитекторов рассмотрим, как Apache Spark Structured Streaming помогает реализовать самообслуживаемый сервис потоковой передачи данных в Delta Lake. А также вспомним каноническую 3-хслойную модель этого уровня хранения от Databricks. Много потоковых сценариев в одном приложении Apache Spark Structured Streaming Мы недавно писали, что архитектуры,...

Риски и возможности отечественного рынка труда с точки зрения профессиональной сертификации по технологиям больших данных. Как и зачем Школа Больших Данных разрабатывает профессиональную вендор-независимую сертификацию по продуктам и технологиям Big Data для еще лучшей подготовки и оценки ИТ-специалистов на российском рынке, опустевшем после ухода западных вендоров. Как изменился рынок профессиональных...

Специально для обучения дата-инженеров и разработчиков распределенных программ, сегодня рассмотрим подходы к организации модульного тестирования Spark-приложений через классы тестовых данных. Зачем и как генерировать эти классы, где их хранить и при чем здесь система автоматической сборки приложений Gradle. Сборка и тестирование Spark-приложений Модульное тестирование лежит в основе проверки работоспособности программного...

Как Apache Spark организует параллельные вычисления, зачем нужны аккумуляторы и каким образом они помогают организовать мониторинг качества данных в аналитических конвейерах их обработки. Смотрим с точки зрения дата-инженера и разработчика распределенных приложений. Как Apache Spark распараллеливает обработку данных Параллельная обработка — это метод вычислений, при котором работает более одного ЦП...

В этой статье для обучения дата-инженеров и разработчиков распределенных приложений, сегодня разберем опыт ИТ-компании Similarweb, где Apache Spark на платформе Databricks вместо AWS Athena ускорил пакетную обработку данных в 50 раз. Также рассмотрим приемы повышения производительности ODBC-драйвера Databricks для улучшенного взаимодействия с озерами данных. Постановка задачи и ограничения POC для...

Учитывая рост интереса к DevOps-инструментам, сегодня рассмотрим, зачем переводить кластер Apache Spark, управляемый YARN, в Kubernetes, и как это сделать наиболее эффективно. А также разберем, какие системные метрики контейнерных Spark-приложений надо отслеживать и с помощью каких средств. Зачем переводить кластер Apache Spark от YARN на Kubernetes Apache Spark не зря...

Недавно мы писали про чтение данных из AWS S3 с помощью PySpark-задний. Продолжая разбираться, как перейти от HDFS к облачным объектным хранилищам, сегодня рассмотрим пример чтения и записи файлов из Google Cloud Storage с помощью Apache Spark. От HDFS к GCS Распределенная файловая система Apache Hadoop (HDFS) уже много лет...

Чтобы сделать наши курсы по Apache Spark для дата-инженеров еще более полезными, сегодня рассмотрим, как PySpark-задания могут считывать данные из корзин объектного хранилища AWS S3, используя Python-пакет boto3. Читайте далее, что представляет собой этот SDK, как использовать его вместе с IAM-ролями, а также как обеспечить безопасность конфиденциальных данных с помощью...

Можно ли применять Apache Spark Structured Streaming для пакетных заданий и в каких случаях это целесообразно. Разбираемся, как устроена потоковая передача событий в Spark Structured Streaming, с какой частотой разные режимы триггеров микропакетной обработки данных запускают потоковые вычисления и что выбрать дата-инженеру. Потоковая передача событий и пакетные задания: versus или...
В июле 2022 года на конференции Data and AI Summit компания Databricks представила новый проект для экосистемы Apache Spark под названием Spark Connect. Что это такое и как оно пригодится разработчикам распределенных приложений и дата-инженерам, читайте далее. Что не так с Apache Spark и зачем нужен новый проект Databricks Появившись...

Сегодня мы продолжим говорить про Apache Spark Structured Streaming и его применение для обновления данных в таблицах Delta Lake. А также на практических примерах разберем, как выполняются основные операции работы с данными средствами Spark Structured Streaming API. Таблицы в Delta Lake Delta Lake – это уровня хранилища данных с открытым...

Продолжая недавний разговор про Apache Spark Structured Streaming, сегодня рассмотрим, как этот движок потоковой обработки данных помогает дата-инженеру реализовать идемпотентную запись в таблицы Delta Lake, а также выполнить операции слияния и обновления/вставки в помощью метода foreachBatch(). Идемпотентность потоковых приложений Apache Spark Идемпотентность – важное свойство распределенных систем, которое гарантирует, что...

Разработка высоконагруженных систем потоковой аналитики больших данных включает не только написание кода, но и его оптимизацию. Поэтому разработчикам приложений Apache Spark Structured Streaming и дата-инженерам полезно знать, как можно повысить эффективность своих Big Data систем. В этой статье мы рассмотрим конфигурации и приемы, которые могут ускорить пакетные и потоковые вычисления....
Сегодня рассмотрим, как реализовать MLOps-идеи при разработке приложений Apache Flink с использованием MLeap, библиотеки сериализации для моделей машинного обучения. Зачем инженеры GetInData разрабатывали для этого свой коннектор и как его использовать на практике. Что такое MLeap и при чем здесь MLOps Будучи популярным вычислительным движком для потоковой аналитики больших данных,...
Мы уже писали про использование криптографии в Apache Spark. Сегодня в рамках обучения дата-инженеров и разработчиков распределенных приложений рассмотрим, как шифровать столбцы датафрейма в PySpark и расшифровывать их с использованием алгоритма шифрования AES. Основы кибербезопасности: ликбез по шифрованию данных Шифрование данных преобразует данные в другую форму или код, чтобы их...
Сегодня разберем тему, важную для обучения дата-инженеров и разработчиков распределенных Spark-приложений. Почему чтение данных из реляционных баз в Apache Spark может быть медленным и как его ускорить, изменив SQL-запрос или структуру таблицы. JDBC-источники данных для Apache Spark Apache Spark является средством обработки, а не хранения больших данных. Поэтому, чтобы использовать...

Сегодня рассмотрим важную тему для обучения дата-инженеров и разработчиков распределенных Spark-приложений. Как устроена потоковая обработка данных в Apache Spark Structured Streaming, зачем нужны водяные знаки и с какими сложностями при этом можно столкнуться. Как работают водяные знаки в потоковой передача событий Apache Spark Библиотека потоковой обработки событий Structured Streaming основана...