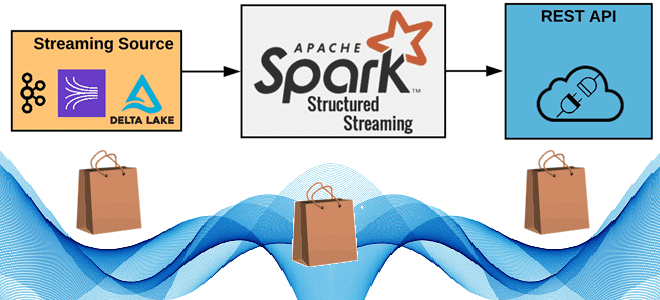
Как реализовать потоковую публикацию данных из приложения Apache Spark Structured Streaming во внешний REST API, используя метод foreachBatch(), зачем перераспределять датафрейм перед его упаковкой в полезную нагрузку HTTP-запроса, от чего зависит число вызовов, и какие приемы помогут избежать сбоев из-за ошибок. 6 шагов потоковой публикации данных в REST API с...

С версии 3.5.0Apache Spark поддерживает Datasketches – программную библиотеку стохастических потоковых алгоритмов. Разбираемся, что это такое, и при чем здесь алгоритм HyperLogLog. Что такое Apache Datasketches и зачем это нужно В аналитике больших данных часто возникают проблемные запросы, которые не масштабируются, поскольку требуют огромных вычислительных ресурсов и времени для получения...
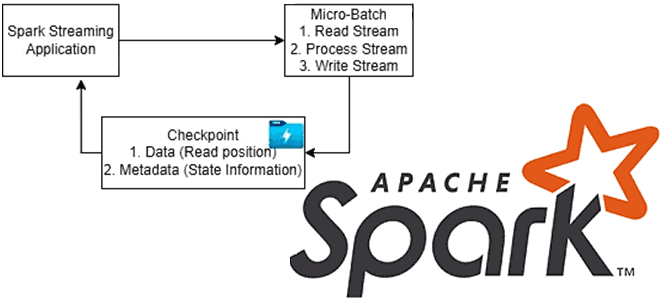
Чтобы обеспечить отказоустойчивость потоковых приложений, Apache Spark использует механизм контрольных точек. Какие они бывают, когда их включать и как настроить для эффективной работы. Что такое checkpoint в Apache Spark и зачем он нужен Чтобы приложение потоковой передачи было устойчиво к сбоям по внешним причинам, например, отказ JVM, Spark Streaming сохраняет...

Зачем разделять таблицы в озере данных, что не так с Hive-разделением и Z-упорядочение в Delta Lake и как работает жидкая кластеризация (Liquid Clustering) – новая стратегия оптимизации размещения данных от Databricks. Что не так с Hive-разделением и Z-упорядочение таблиц в Delta Lake В озере данных физическое расположение данных может оказать...

Каждому специалисту по Data Science и инженеру данных знакома Python-библиотека pandas. Однако, для работы с большими данными она не очень подходит из-за высокого потребления памяти. Тем не менее, отказаться от старых привычек сложно. Поэтому разбираемся, зачем использовать API Pandas в Apache Spark и как это сделать наиболее эффективно. Чем отличается...

Из-за чего приложения Flink работают быстрее Spark: разница в моделях обработки данных, управлении памятью, методах оптимизации, дизайне API и личный опыт использования. Apache Flink vs Spark: сходства и отличия Apache Spark и Flink считаются наиболее популярными фреймворками разработки распределенных приложений в области Big Data. Они достаточно похожи, что мы ранее...

Как разница между Scala и Java отражается на работе Spark-приложения, почему код на Scala работает быстрее и когда выбирать этот язык программирования для разработки приложений аналитики больших данных. Scala vs Java: ключевые отличия Хотя Apache Spark позволяет разработчику писать код на нескольких языках программирования (Scala, Java, R, Python), сам фреймворк...

13 сентября 2023 года вышел Apache Spark 3.5. Знакомимся с самыми важными новинками свежего релиза: расширения Spark Connect и SQL, поддержка DeepSpeed, улучшения потоковой передачи и свежие UDF-функции Python. ТОП-5 новинок Apache Spark 3.5.0 В Apache Spark 3.5. добавлено много исправлений и улучшений, а также реализованы новые функции. Наиболее интересными...

Сегодня рассмотрим, какие улучшения Apache Spark опубликованы в 2023 году и как подать свое предложение по улучшению самого популярного вычислительного движка в стеке Big Data. Что такое SPIP и как подать свое предложение по улучшению фреймворка В любом продукте помимо ошибок есть также предложения по улучшению. В Apache Spark они...

Чем отличается оркестрация ETL-процессов в Databricks и Apache AirFlow: принципы работы, достоинства и недостатки, а также что выбирать дата-инженеру для решения практических задач. Apache AirFlow vs Spark в Databricks: сходства и отличия Облачная платформа Databricks, основанная на Apache Spark, предлагает пользователям единую среду для создания, запуска и управления различными рабочими...

Как получать результаты обработки данных с помощью Apache Spark, адресуя ИИ бизнес-запросы на английском языке: знакомимся с English SDK от Databricks. Настоящий Low Code с PySpark-AI. English SDK for Apache Spark и PySpark-AI: как это работает Большие языковые модели (LLM, Large Language Model), основанные на генеративных нейросетях, применимы не только...
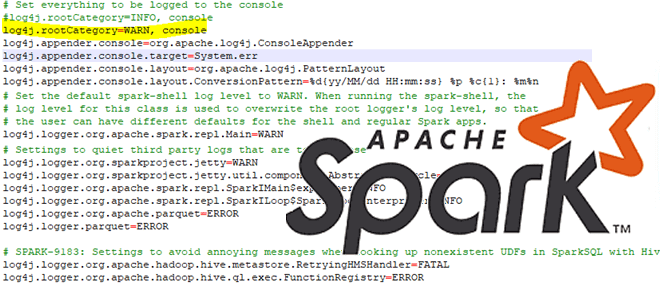
Сегодня рассмотрим особенности отладки PySpark-приложений: как Python-код исполняется в JVM, какие сложности возникают у разработчика при тестировании и исправлении ошибок в программе, написанной локально и запускаемой в кластере, а также как настроить вывод событий в лог-файл. Запуск и выполнение PySpark-кода Хотя Apache Spark и имеет Python API, позволяя писать код...
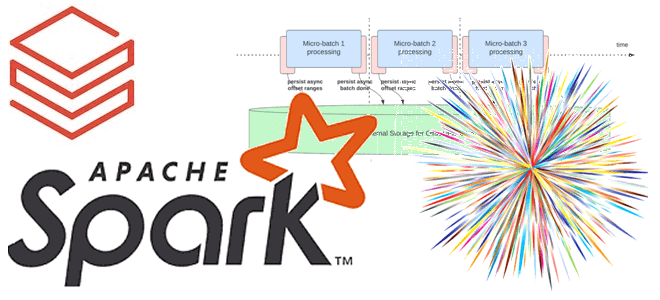
В прошлом году Databricks выпустили новый проект для ускорения потоковой передачи в Apache Spark. Сегодня рассмотрим, как именно Lightspeed сокращает задержку в операционных рабочих нагрузках Structured Streaming с помощью асинхронного управления смещением. Операционные рабочие нагрузки и что их тормозит в Apache Spark Structured Streaming Рабочие нагрузки потоковой передачи можно разделить...
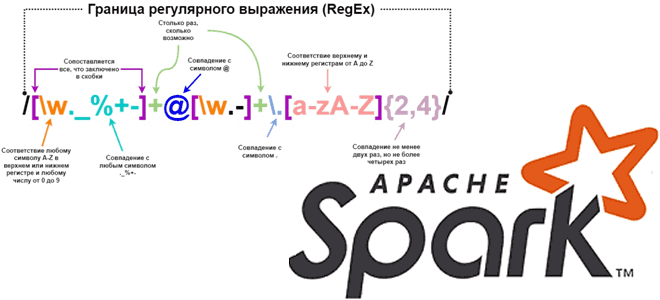
Каждый дата-инженер и аналитик данных активно использует регулярные выражения для поиска значений в тексте по заданному шаблону. Сегодня рассмотрим, как это сделать с функциями regexp_replace(), rlike() и regexp_extract в Apache Spark на примере небольшого PySpark-приложения. Как работает функция regexp_replace() Регулярным выражением называется последовательность символов, задающая шаблон соответствия в тексте. Например,...
Чем полезны новые фичи Apache Spark SQL, выпущенные в релизе 3.4. Разбираемся с псевдонимами столбцов и параметризованными SQL-запросами на простых примерах, запуская Spark-приложение в Google Colab. Псевдонимы столбцов Хотя с момента выхода Apache Spark 3.4 в апреле 2023 года, о чем мы писали здесь, прошло почти полгода, возможность ссылаться на...
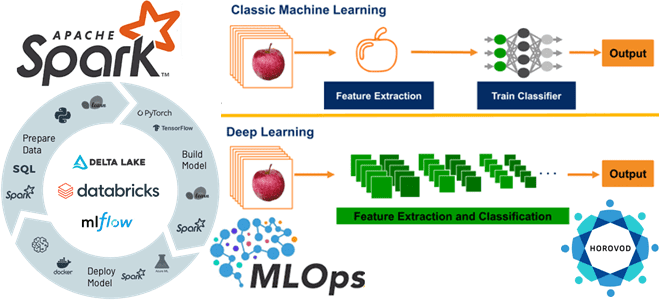
Из чего состоит инфраструктура глубокого обучения Databricks и как масштабировать Deep Learning для нескольких графических процессоров или распределенных вычислений. Знакомимся с очередным MLOps-инструментом под названием Horovod. Что Horovod и как его использовать в Databricks Мы уже писали, почему глубокому обучению не обойтись без MLOps-инструментов, реализующих идеи DevOps для автоматизации разработки,...

От межсайтового скриптинга до внедрения вредоносного кода: какие проблемы информационной безопасности были обнаружены и исправлены в Apache Spark в 2023, 2022 и 2021 годах. Последние известные и исправленные проблемы информационной безопасности Apache Spark Недавно мы писали о механизмах обеспечения информационной безопасности в Apache Spark. Однако, несмотря на наличие этих средств,...

23 июня 2023 года опубликован очередной релиз Apache Spark 3.4.1, который считается отладочным выпуском для предыдущего, содержащий исправления стабильности. Помимо исправления ошибок, в нем также 16 новых фичей и более 20 улучшений, самые главные из которых мы рассмотрим далее. Исправления ошибок и новые фичи Apache Spark 3.4.1 Поскольку выпуск считается...
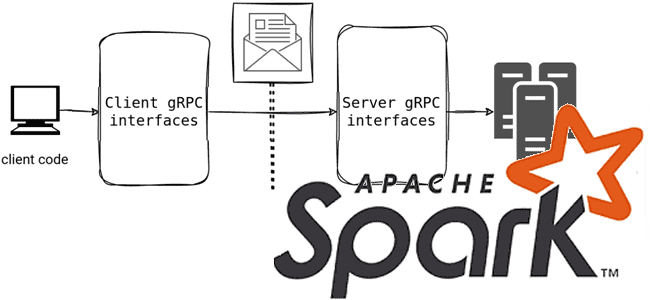
Мы уже писали, что в выпуске 3.4.0 от апреля 2023 года Spark Connect представил несвязанную архитектуру клиент-сервер, которая обеспечивает удаленное подключение к кластерам Spark из любого приложения, работающего в любом месте. Сегодня рассмотрим подробнее, как это работает и каковы плюсы для практического использования. Что такое Spark Connect и зачем это...
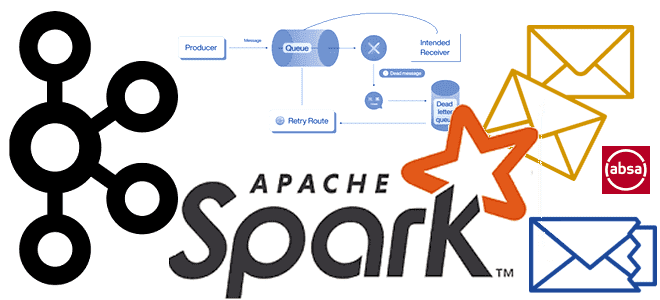
Недавно мы писали про лучшие практики работы с очередями недоставленных сообщений в Apache Kafka. Сегодня рассмотрим, как реализовать DLQ для AVRO-сообщений в приложении Spark Streaming c библиотекой ABRiS. DLQ для Apache Kafka в Spark-приложении Ситуация, когда приложение-продюсер вдруг изменяет формат или схему данных, публикуемых в Apache Kafka, на практике случается....