
Хорошие курсы дата-инженеров предполагают не только изучение теории и практики, но и проверку полученных знаний. Поэтому сегодня мы предлагаем вам открытый интерактивный тест по Apache AirFlow. Ответьте на 10 простых вопросов и узнайте, насколько хорошо вы знакомы с особенностями администрирования и эксплуатации этого популярного фреймворка для автоматизации batch-заданий обработки и...

Продвигая наши курсы для разработчиков Spark с примерами реальных систем аналитики больших данных, сегодня рассмотрим библиотеку для чтения файлов формата DICOM от индийской компании Abzooba. Читайте далее, как автоматизировать поиск по миллиардам медицинских изображений с помощью машинного обучения и технологий Big Data: Apache Spark, Hadoop, Kafka, Elasticsearch и Kibana. Что...
Поскольку курсы инженеров Big Data предполагают практическое обучение на реальных кейсах, сегодня поговорим про тестирование конвейеров обработки и аналитики больших данных и разберем несколько прикладных примеров для компонентов экосистемы Apache Hadoop. Читайте далее про проверку работоспособности, а также поиск ошибок в Spark-заданиях и DAG-цепочках Airflow. Конвейер для конвейера: сложности тестирования...

Чтобы показать, насколько разной бывает аналитика больших данных, сегодня рассмотрим кейс международной компании Spidertracks, которая с помощью технологий Big Data создает ИТ-решения для отслеживания, связи и управления безопасностью воздушных судов. Читайте далее, почему для потоковой обработки событий был выбран Kinesis Analytics for SQL, а не конвейер из Apache Kafka и...

Сегодня продолжим разбираться с реализацией CDC-подхода в современных Big Data решениях и погрузимся в Databricks Delta Lake – облачный уровень хранения и аналитики больших данных с поддержкой ACID-транзакций. Читайте далее про переход от ночных ETL-пакетов с Informatica к быстрому обновлению данных в Amazon S3 на конвейере Spark и Kafka. Возможности...
Вчера мы упоминали про CDC-подход в проектировании транзакционных систем аналитики больших данных на базе Apache Kafka и Spark Streaming. Сегодня рассмотрим подробнее примеры такого применения технологий Big Data и лучшие практики Change Data Capture в потоковой обработке финансовых и других транзакций. Зачем нужны потоковые конвейеры транзакционной обработки Big Data на...

В этой статье рассмотрим особенности совместного использования Apache Kafka и Spark Streaming для обработки финансовых транзакций в режиме онлайн. Читайте далее про типовые кейсы практического применения конвейера аналитики больших данных на базе Kafka и Spark, а также проблемы или технологические особенности такой Big Data системы и пути обхода этих ограничений....

Продолжая разговор про оптимизацию Apache Spark и повышение эффективности Big Data приложений, сегодня рассмотрим способы ускорения Shuffle-операций в Spark SQL, разберем, чем хороши широковещательные JOIN-операции и как количество разделов влияет на производительность запросов в распределенных приложениях аналитики больших данных. 4 способа оптимизации Shuffle-операций При аналитике больших данных с помощью Apache...

Недавно мы рассматривали, как повысить производительность конвейеров Apache Spark и повысить скорость распределенных приложений для аналитики больших данных. Сегодня разберемся, почему тормозят отдельные Spark-задачи и как их ускорить. Читайте далее про инициализацию Спарк-контекста, предзагрузку артефактов и применение клиентского режима. Почему некоторые задачи в быстром Apache Spark выполняются так медленно Напомним,...
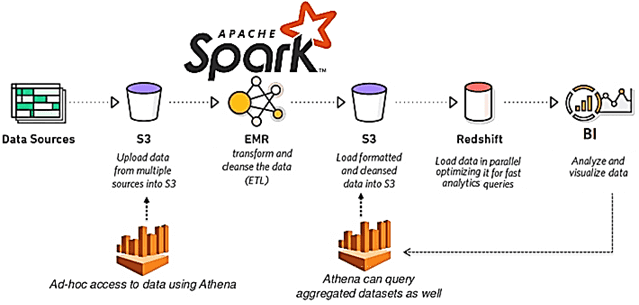
Мы уже рассказывали, почему качество данных является важнейшим аспектом разработки и эксплуатации Big Data систем. Приемлемое для эффективного использования качество массивов информации достигается не только с помощью процессов подготовки датасета к машинному обучению и профилирования данных, но и за счет их согласования. Читайте далее, что такое Data reconciliation, зачем это...

Чтобы сделать ваше самостоятельное обучение Apache Kafka и прочим технологиям Big Data по статьям нашего блога еще более интересным, сегодня мы предлагаем вам открытый интерактивный тест по этой платформе потоковой обработки событий. Ответьте на 10 простых вопросов и узнайте, насколько хорошо вы знакомы с особенностями администрирования и эксплуатации этого популярного...

Вчера мы говорили про ускорение аналитики больших данных в конвейере из множества заданий Apache Spark. Продолжая речь про обучение инженеров данных, сегодня рассмотрим, как снизить стоимость выполнения Spark-приложений, сократив накладные расходы на обработку Big Data и повысив эффективность использования кластерной инфраструктуры. Экономика Big Data систем: распределенная разработка и операционные затраты...

Сегодня рассмотрим несколько простых способов ускорить обработку больших данных в рамках конвейера задач Apache Spark. Читайте далее про важность тщательной оценки входных и выходных данных, рандомизацию рабочей нагрузки Big Data кластера и замену JOIN-операций оконными функциями. Оптимизируй это: почему конвейеры аналитической обработки больших данных с Apache Spark замедляются Обычно со...

Недавно мы уже рассматривали выполнение Join-операций в Apache Spark SQL. Сегодня поговорим про особенности потокового соединения в модуле Structured Streaming этого популярного фреймворка аналитики больших данных. Читайте далее, в чем специфика внешних и внутренних соединений потоков Big Data в Apache Spark Structured Streaming, а также как и зачем Inner/Outer Join...

Совместное использование Apache Kafka и Spark очень часто встречается в потоковой аналитике больших данных, например, в прогнозировании пользовательского поведения, о чем мы рассказывали вчера. Однако, временные метки (timestamp) в приложении Spark Structured Streaming могут отличаться от времени события в топике Kafka. Читайте далее, почему это случается и какие подходы к...
В продолжение разговора о применении технологий Big Data и Machine Learning в рекламе и маркетинге, сегодня рассмотрим архитектуру системы прогнозирования конверсии рекламных объявлений. Читайте далее, как организовать предиктивную аналитику больших данных на Apache Kafka и компонентах ELK-стека (Elasticsearch, Logstash, Kibana), почему так важно тщательно подготовить данные к машинному обучению, какие...
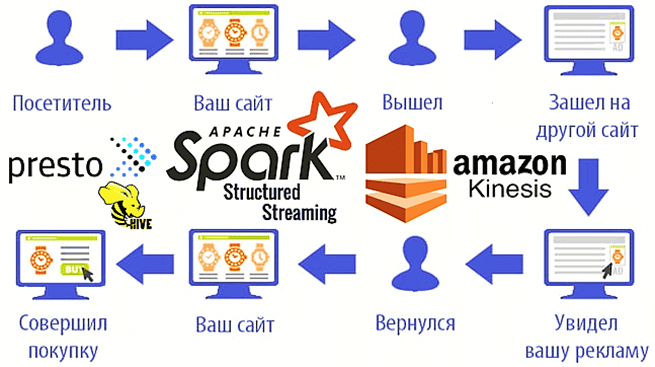
Мы уже рассказывали о возможностях ретаргетинга и использовании Apache Spark Structured Streaming для реализации этого рекламного подхода на примере Outbrain. Такое применение технологий Big Data сегодня считается довольно распространенным. Чтобы понять, как это работает на практике, рассмотрим кейс маркетинговой ИТ-компании MIQ, которая запускает Spark-приложения на платформе Qubole и сервисах Amazon,...

Продолжая разговор про фиксацию заданий Apache Spark при работе с облачными хранилищами больших данных, сегодня подробнее рассмотрим, насколько эффективны commit-протоколы экосистемы Hadoop, предоставляемые по умолчанию, и почему известный разработчик Big Data решений, компания Databricks, разработала собственный алгоритм. Читайте далее про сравнение протоколов фиксации заданий в Spark-приложениях: результаты оценки производительности и...

Сегодня поговорим про особенности транзакций в Apache Spark, что такое фиксация заданий в этом Big Data фреймворке, как она связано с протоколами экосистемы Hadoop и чем это ограничивает переход в облако с локального кластера. Читайте далее, как найти компромисс между безопасностью и высокой производительностью, а также чем облачные хранилища отличаются...

В этой статье рассмотрим, что такое Apache Spark Structured Streaming и Spark Streaming, чем они отличаются и что общего между этими 2-мя способами обработки потоковых данных в самом популярном фреймворке аналитики больших данных. Читайте далее, как микро-пакетная передача приближается к режиму реального времени и при чем здесь структуры данных для...