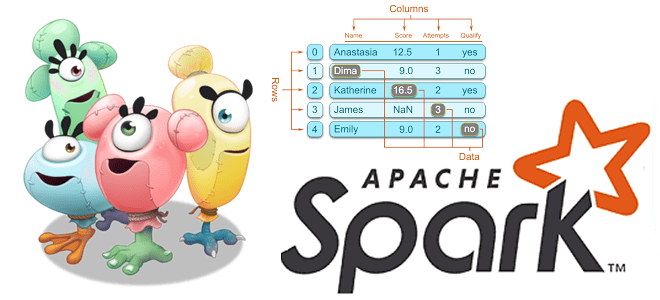
Чтобы сделать наши курсы по Apache Spark еще более полезными, мы рассказываем о неочевидных тонкостях этого фреймворка, знание которых позволит разработчику распределенных приложений использовать возможности этой технологии более эффективно. Сегодня на практических примерах PySpark в API DataFrame рассмотрим разницу между функциями сортировки массивов и особенности объединения контенкации, а также разберемся...
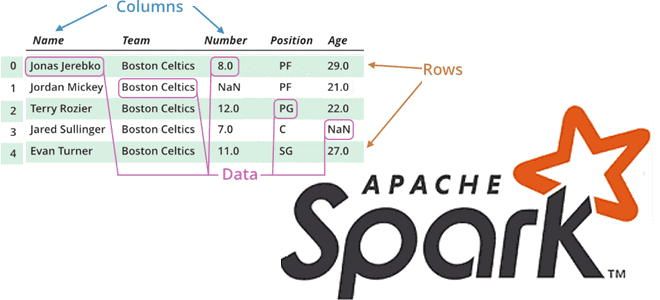
Продолжая разговор про вычислительные операции над датафреймами в Apache Spark, сегодня рассмотрим, какие преобразования (transformations) и действия (actions) чаще всего используются при разработке распределенных приложений и аналитике больших данных. Читайте далее, про виды столбцовых преобразования и отличия действия collect() от take(). Преобразования в Apache Spark: виды и особенности реализации Напомним,...
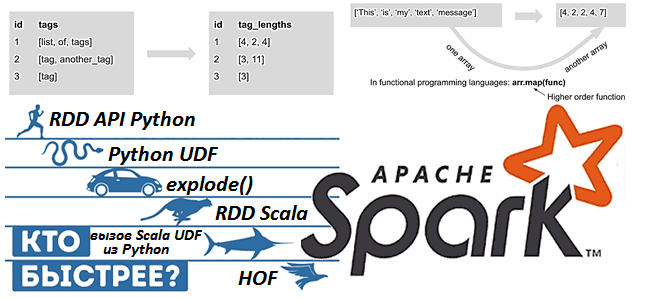
Apache Spark предоставляет для разработчика распределенных приложений множество возможностей, позволяя достигать одной целей разными способами. Чтобы проиллюстрировать это, сегодня рассмотрим бенчмаркинговое сравнение 9 методов обработки массивов в Spark 3.1, обращая внимание на их производительность и особенности использования. Также разберем важные для обучения разработчиков Spark темы про отличия преобразований от действий...

Сегодня рассмотрим пример построения системы потоковой аналитики больших данных на базе Apache Kafka, Spark, Flink, NoSQL-СУБД, BI-системой Tableau или визуализацией в Kibana. Читайте далее, кому и зачем исследовать Twitter-посты в реальном времени, как это реализовать технически, визуализировать в наглядных BI-дэшбордах для принятия data-driven решений и при чем здесь Kappa-архитектура. Еще...

Apache Spark + AirFlow – известная каждому дата-инженеру комбинация технологий Big Data для запуска сложных конвейеров обработки данных. Но совместное использование этих фреймворков ограничено недостатками AirFlow, часть из которых можно обойти с помощью Apache Livy. Однако эксплуатация AirFlow менее удобна, чем Dagster. Поэтому сегодня рассмотрим, как этот альтернативный оркестратор данных...
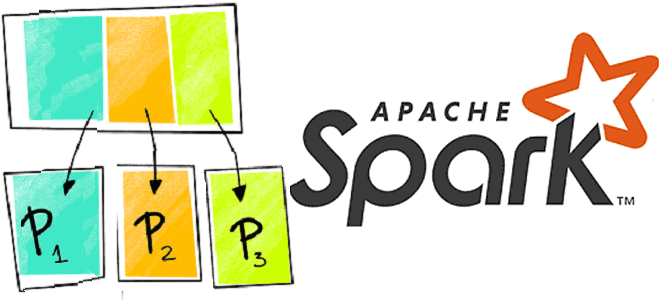
Чтобы сделать обучение разработчиков Apache Spark, дата-аналитиков и инженеров Big Data еще более наглядным, сегодня рассмотрим проблему JOIN-соединений при неравномерном распределении данных по узлам кластера и способы ее решения. Читайте далее, как избавиться от перекосов и ускорить выполнение SQL-запросов в Spark-приложениях. Перекосы данных в Apache Spark: что это и чем...

Продолжая добавлять в наши практические курсы по Apache Kafka и Spark еще больше интересных примеров, сегодня рассмотрим, как с помощью этих технологий Big Data анализировать метаданные сетевых потоков в реальном времени. В этой статье мы приготовили для вас кейс по потоковой аналитики больших данных о сетевом трафике с помощью Apache...
Сегодня поговорим про обработку геопространственных данных с Apache Spark и рассмотрим, что такое Apache Sedona, как этот фреймворк связан с GeoSpark, какие форматы и структуры данных он поддерживает. Читайте далее про пространственные RDD, Spatial SQL-запросы и построение конвейеров обработки геоданных в облачных сервисах Amazon. Как обработать геопространственные данные в...

Сегодня рассмотрим инструмент, который облегчает практическое использование Apache Spark, позволяя дата-аналитику и разработчику распределенных приложений быстро писать и выполнять SQL-запросы в рамках удобного веб-редактора. Читайте далее, что такое Hue, как он связан со Spark SQL и Hive, а также причем здесь Livy. Что Hue и при чем здесь Apache Livy...
В этой статье рассмотрим особенности подключения Apache Spark к внешним СУБД как к источникам данных для аналитики Big Data средствами SQL-модуля этого фреймворка. Читайте далее о том, что такое JDBC-драйвер, чем источник данных JDBC отличается от сервера Spark SQL JDBC, при чем здесь RPC-фреймворк и язык описания интерфейсов Thrift, а...

Сегодня рассмотрим Apache Spark с точки зрения Data Science специалиста: поговорим про сходства и отличия библиотек машинного обучения в этом фреймворке. Также ответим на вопрос «Spark ML vs MLLib», разберем, зачем Data Scientist’у и аналитику больших данных нужны курсы по Apache Spark, а в заключение отметим наиболее важные улучшения библиотеки...

Продолжая разбирать особенности бакетирования таблиц в Apache Spark, сегодня мы рассмотрим несколько примеров, как дата-инженер и аналитик данных могут работать с этим методом оптимизации SQL-запросов. Также читайте далее, какие конфигурации Apache Spark SQL связаны с бакетированием таблиц и что нового появилось в 3-ей версии этого Big Data фреймворка, чтобы такой...
Бакетирование таблиц в Apache Spark – один из самых популярных методов оптимизации производительности задач последовательного чтения данных. Сегодня поговорим про сложности бакетирования с точки зрения дата-инженера, а также рассмотрим факторы, от которых зависит оптимальное количество бакетов. Большая проблема маленьких файлов и бакетирование таблиц в Apache Spark Напомним, бакетирование ускоряет выполнение...

В рамках обучения аналитиков Big Data и разработчиков Apache Spark и Kafka, сегодня рассмотрим кейс ИТ-компании Southworks по онлайн-обработке потокового видео как наглядный пример эффективного сочетания этих потоковых фреймворков с пакетными задачами. Читайте далее, как реализовать лямбда-архитектуру масштабируемой Big Data системы на базе Apache Kafka, Spark Structured Streaming и NoSQL-СУБД...

Развивая наши курсы по Apache Spark, сегодня мы рассмотрим несколько особенностей, с разработчик которыми может столкнуться при выполнении обычных операции, от чтения архивированного файла до обращения к сервисам Amazon. Читайте далее, что не так с методом getDefaultExtension(), зачем к AWS S3 так много коннекторов и почему PySpark нужно дополнительно конфигурировать...

В этой статье продолжим говорить про обучение разработчиков Apache Spark и рассмотрим, какие сегменты памяти есть в этом Big Data фреймворке и как с ними работать наиболее эффективно. Читайте далее, почему процессы PySpark и SparkR потребляют внешнюю память, чем пользовательская память кучи JVM отличается от памяти хранилища и какие конфигурации...

Продолжая разговор про практическое обучение разработчиков Apache Spark, сегодня рассмотрим пример повышения скорости выполнения SQL-запросов к большому датафрейму. Читайте далее, как определить и исправить асимметрию распределения данных по разделам, зачем добавлять контрольные точки в длинные DAG и в чем здесь опасность, чем хороша широковещательная трансляция, для чего фильтровать данные перед...

На практике каждый аналитик Big Data и Data Scientist часто сталкивается с удалением дублирующихся значений в датасете. Поэтому, чтобы добавить в наши курсы по Apache Spark еще больше полезных примеров, сегодня рассмотрим 5 простых способов решения этой востребованной задачи. Читайте далее, чем distinct() отличается от dropDuplicates(), а reduceByKey() - от...

Сегодня рассмотрим преимущества потоковой обработки данных с Apache Kafka и Flink над пакетными Big Data технологиями в виде Hadoop, Spark и Oozie. В качестве примера разберем реальный кейс аналитики больших данных по пользовательским сеансам в музыкальном онлайн-сервисе Spotify, а также возможность замены Apache Flink на Spark Structured Streaming. От рекламы...

Сегодня рассмотрим, что такое Data Build Tool, как этот ETL-инструмент связан с корпоративным хранилищем и озером данных, а также чем полезен дата-инженеру. В качестве практического примера разберем кейс подключения DBT к Apache Spark, чтобы преобразовать данные в таблице Spark SQL на Amazon Glue со схемой поверх набора файлов в AWS...