
В рамках курсов по Apache Hadoop для дата-аналитиков и инженеров данных сегодня рассмотрим пару практических примеров работы с популярным SQL-on-Hadoop инструментом этой экосистемы. Читайте далее, как настроить соединение удаленного сервера Apache Hive к Spark-приложению через JDBC и решить проблему запроса таблицы HBase в Hive вместо повторной репликации данных. Подключение удаленного...

При том, что Apache Spark является одной из главных технологий стека Big Data, этот фреймворк не очень хорошо работает с множеством файлов небольшого размера. Поэтому в рамках обучения дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим, почему это происходит, зачем динамически сжимать файлы в Apache Spark и как это делает платформа...

Сегодня разберем кейс компании Renault по масштабированию своей цифровой платформы и снижению затрат с помощью BigQuery и Apache Spark на Google Dataproc. Цифровизация в автомобильной промышленности: конвейер сбора и аналитики больших данных с производства средствами Google сервисов и снижение затрат на облако в 2 раза через изменение конфигурации Spark SQL....

В рамках курсов для дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим пример построения системы потоковой передачи для аналитики больших данных на базе Apache Kafka, Spark и Google BigQuery. Читайте далее про Proof of Concept для конвейера продуктовой аналитики, который обрабатывает 50 миллиардов событий каждый день, и какие важные уроки ИТ-архитектор...

YARN считается самым распространенным диспетчером ресурсов в кластерах Apache Hadoop и Spark, отвечая за выделение ресурсам распределенным приложениям. Сегодня в рамках обучения дата-инженеров и администраторов Hadoop рассмотрим достоинства и недостатки 3-х вариантов планирования ресурсов в YARN. Читайте далее, что такое иерархия очереди и как вычисляется ее мгновенная справедливая доля. Планирование...

Apache Storm обычно сравнивают со другими популярными фреймворками потоковой аналитики больших данных: Spark и Flink. Однако для несложной обработки событий дата-инженер может заменить эти платформы более легким инструментом маршрутизации потоковых данных в виде Apache NiFi. Сегодня сравним Apache NiFi co Storm и разберем практический пример, когда предпочтительнее именно его для...

Сегодня в рамках обучения дата-аналитиков и разработчиков Spark-приложений, рассмотрим еще несколько особенностей этого фреймворка. Почему count() работает по-разному для RDD и DataFrame, как отличается уровень хранения при применении метода cache() для этих структур, когда использовать SortWithinPartitions() вместо sort(), а также парочка тонкостей обработки Parquet-таблиц в Spark SQL и кэширование метаданных...

Специально для разработчиков распределенных приложений, Data Scientist’ов и аналитиков больших данных, работающих с Apache Spark, в этой статье мы собрали несколько полезных советов по ежедневным операциям в этом фреймворке. Читайте далее, как добавить библиотеку TypeSafe в файл sbt-конфигурации Spark-приложения, получить датафреймы из JSON-массивов и структур, а также обработать CSV-формат с...

Чтобы дополнить наши курсы по Kafka и Spark интересными примерами, сегодня рассмотрим практический кейс разработки микросервисного конвейера машинного обучения на этих фреймворках. Читайте далее, зачем выносить ML-компонент в отдельное Python-приложение от остальной части Big Data pipeline’а, и как Docker поддерживает эту концепцию микросервисного подхода. Постановка задачи и компоненты микросервисного ML-конвейера...

В июле 2021 года «Аренадата Софтвер», российская ИТ-компания разработчик отечественных решений для хранения и аналитики больших данных, представила минорный релиз корпоративного дистрибутива на базе Apache Hadoop — Arenadata Hadoop 2.1.4. Главными фишками этого выпуска стало наличие 3-й версии Apache Spark и External PostgreSQL для Hive MetaStore. Сегодня рассмотрим, что именно...

Сегодня в рамках обучения разработчиков Apache Spark и дата-аналитиков, поговорим про детерминированность UDF-функций и особенности их обработки оптимизатором SQL-запросов Catalyst. На практических примерах рассмотрим, как оптимизатор Spark SQL обрабатывает недетерминированные выражения и зачем кэшировать промежуточные результаты, чтобы гарантированно получить корректный выход. Еще раз про детерминированность функций и планы выполнения...

Мы уже рассказывали про коннектор Greenplum-Spark, 2-я версия которого вышла в октябре 2020 года. А сегодня рассмотрим российскую альтернативу для отечественной MPP-СУБД Arenadata DB на базе Greenplum, выпущенную компанией Аренадата в июле 2021 года. Краткий обзор ADB-Spark Connector: архитектура, принципы работы, сценарии использования, а также отличия от PXF-фреймворка и варианта...

Вчера мы упоминали, что использование Spark или Tez в качестве движка исполнения SQL-запросов в Apache Hive вместо классического Hadoop MapReduce намного ускоряет аналитику больших данных. Сегодня рассмотрим подробнее, чем отличаются эти механизмы и какой из них выбирать в разных случаях использования. Что такое Apache Tez и как он работает с...

Apache Hive – востребованный инструмент класса SQL-on-Hadoop, который также активно используется в работе с фреймворком Spark. Поэтому сегодня разберем важную тему из обучения дата-инженеров и аналитиков больших данных про оптимизацию SQL-запросов в этом NoSQL-хранилище. Смотрите, чем полезна векторизация HiveQL-операций, какие форматы файлов обрабатываются быстрее, почему денормализация данных в Hive –...

Чтобы добавить в наши курсы по Spark еще больше практических кейсов, сегодня ответим на самые частые вопросы относительно масштабирования распределенных приложений, написанных с помощью этого фреймворка. Читайте далее о пользе динамического распределения, оптимальном выделении ресурсов на драйверы и исполнители, а также каковы тонкости управления разделами в Apache Spark. Лебедь, рак...

Обучая разработчиков Big Data, сегодня рассмотрим, почему в распределенных приложениях Apache Spark случаются OOM-ошибки. Читайте далее, как работает сборка мусора JVM в Spark-приложениях, почему из-за нее случаются утечки памяти и что можно сделать на уровне драйвера и исполнителя для предупреждения OutOfMemoryError. Сборка мусора JVM и OOM-ошибки в Spark-приложениях На практике...

В этой статье по обучению Apache Spark рассмотрим, чем графический веб-интерфейс этого фреймворка полезен разработчику распределенных приложений. Читайте далее, где посмотреть кэшированные данные, визуализацию DAG, переменные среды, исполняемые SQL-запросы, а также прочие важные метрики кластерных вычислений и аналитики больших данных. 9 страниц Apache Spark UI Apache Spark предоставляет набор пользовательских...

Мы уже рассказывали, что приложения Kafka Streams используют RocksDB в качестве хранилища состояний. Сегодня рассмотрим, как это key-value NoSQL-СУБД используется для разработки stateful-приложений Apache Flink. Читайте далее о преимуществах и особенностях применения RocksDB для управления состоянием Flink-приложения, а также заблуждениях, связанных с этими фреймворками. 3 бэкенда Apache Flink для хранения...
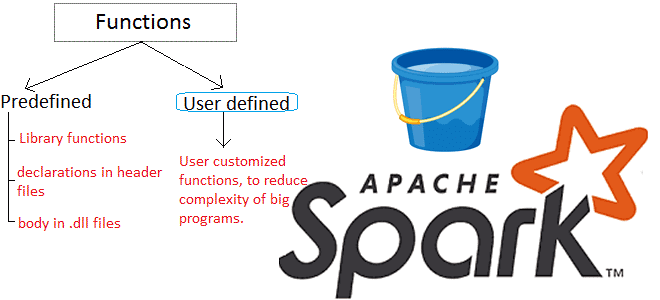
Продвигая наши курсы по Apache Spark для разработчиков, сегодня рассмотрим пользовательские функции и особенности работы с ними в API SQL-модуле этого фреймворка. Читайте далее про идемпотентность UDF-функций и их влияние на распределение данных в кластере Apache Spark. Как устроены UDF в Apache Spark: краткий ликбез Пользовательские функции (User Defined Functions,...
В рамках обучения разработчиков Apache Spark, сегодня рассмотрим еще несколько интересных особенностей этого фреймворка, ограничивающих его типовые возможности и на PySpark-примерах разберем, как с этим бороться. Читайте далее, что такое оконные функции и зачем они нужны, как сортировка влияет на фрейм окна в Spark SQL и чем опасны действия над...