
Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим работу Data Science исследователей из Пизанского университета и сотрудников крупного ритейлера H&M по анализу данных торгового ассортимента компании с помощью ML-моделей на графах. Читайте далее, как машинное обучение на графовых нейросетях автоматизирует подбор сочетаемых предметов одежды и...

Сегодня разберем типовые ошибки, которые часто возникают в системах аналитики больших данных на базе Apache Hadoop YARN, Spark и RESTful-интерфейсу Livy, а также каким образом их избежать. В качестве практического примера используем ранее рассмотренный кейс интерактивной аналитики о пользовательском поведении в фотохостинге Pinterest. Интерактивная аналитика больших данных в Pinterest Недавно...

В этой статье рассмотрим 2 способа физической группировки данных для ускорения последующей обработки в Apache Hive и Spark: партиционирование и бакетирование. Чем они отличаются друг от друга, что между ними общего и какой рост производительности дает каждый из методов в зависимости от задач аналитики больших данных средствами Spark SQL. Еще...

В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, что такое DataStax Enterprise Graph. Читайте далее, как немецкая ИТ-компания Traversals с помощью этой распределенной графовой СУБД построила масштабное аналитическое решение для кибербезопасности, обнаружения мошенничества, анализа конкурентов и оповещения клиентов в реальном времени. Также разберем, при...

Сегодня в качестве полезного примера для обучения дата-инженеров и разработчиков Spark-приложений, разберем кейс компании Pinterest по интерактивной аналитике больших данных средствами SQL-модуля этого популярного фреймворка. Читайте далее, почему дата-инженеры решили заменить HiveServer2 на Spark Thrift JDBC/ODBC, зачем понадобилось писать собственный клиент поверх Apache Livy и как это было сделано. Зачем...
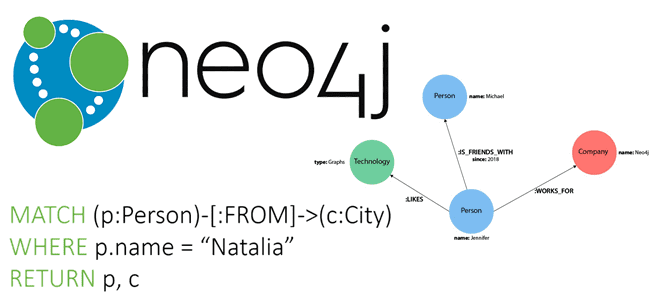
Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим ключевые отличия графовых СУБД от реляционных, а также познакомимся с основами Neo4j и ее языком запросов - Cypher. Также вас ждет практический пример построения несложного графа средствами Cypher. Когда графовые СУБД лучше реляционных и почему Несмотря на...

В продолжение недавней статьи для дата-инженеров про альтернативные платформы потоковой передачи событий вместо Apache Kafka, сегодня рассмотрим пример аналитики больших данных средствами Flink SQL, записи результатов в Elasticsearch и их визуализации в Kibana. Читайте далее, чем Redpanda отличается от Kafka, а Flink – от Apache Spark с точки зрения потоковой...

В рамках обучения разработчиков Spark-приложений, аналитиков данных и дата-инженеров, сегодня рассмотрим, как улучшить и визуализировать понимание обработки данных в этом Big Data фреймворке. Читайте далее про API встроенных механизмов наблюдения за качеством данных в Apache Spark и открытые библиотеки профилирования на примере Deequ. 2 уровня абстракции мониторинга Spark-приложений для дата-инженера...

Анализ данных в рамках пользовательский сеансов (сессий) – довольно востребованный кейс в Apache Spark, который не так просто реализовать из-за особенностей потоковой и пакетной обработки, а также эксплуатационных расходов. Сегодня рассмотрим, как работают сеансовые окна Spark Structured Streaming и каковы ограничения этого фреймворка. Что такое сеансовые окна: краткий ликбез по...

Чтобы добавить в наши курсы для дата-инженеров по технологиям Apache Kafka, Spark, AirFlow, NiFi, Flink и Greenplum, еще больше практических примеров, сегодня разберем кейс ритейлера Леруа Мерлен. Читайте далее, как сотрудники российского отделения этой международной компании интегрировали в единую платформу более 350 реляционных СУБД и NoSQL-источников с помощью CDC-подхода на...
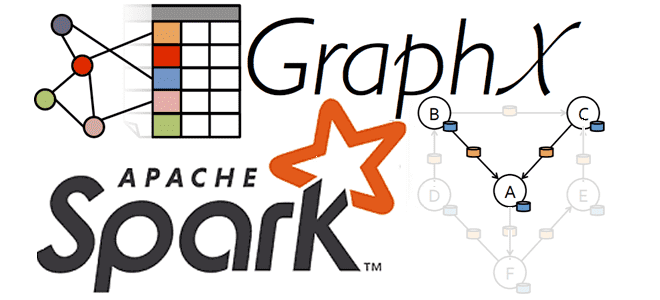
В рамках продвижения нашего нового курса по графовым алгоритмам на больших данных, сегодня разберем, что такое Pregel, и как API этой платформы реализован в Apache Spark GraphX. Читайте далее, как из RDD вершин и ребер образуется триплет, а также какие механизмы отвечают за отказоустойчивость графовой аналитики больших данных. Что такое...

В этой статье для дата-инженеров рассмотрим кейс компании PayPal, которая переводит свои аналитические рабочие нагрузки из локального кластера Apache Spark в Google Cloud Processing. Читайте далее, чем это решение оказалось лучше выполнения Spark-заданий в кластере DataProc с использованием данных BigQuery и облачного хранилища Google (GCS, Google Cloud Storage) для потоковой...

Сегодня рассмотрим пару кейсов по использованию Apache Flink в качестве основного фреймворка пакетной и потоковой аналитики больших данных. Читайте далее, как фото-хостинг Pinterest построил вокруг Flink собственную инфраструктуру работы с изображениями в реальном времени, а китайский ритейл-гигант Alibaba Group успешно обрабатывал 7 ТБ в секунду во время глобального дня шопинга....

Продвигая наш новый курс по графовым алгоритмам на больших данных, сегодня рассмотрим, почему концепция графов сегодня так востребована в Big Data и Machine Learning. Вас ждет краткий ликбез по модулю GraphX в Apache Spark и его отличия от API GraphFrames, а также особенности кластерной обработки и сохранения данных графа свойств....
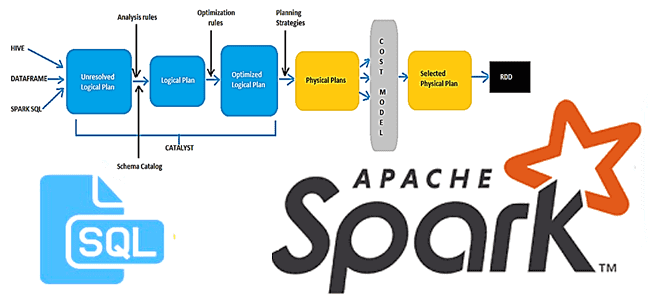
В этой статье для разработчиков Spark-приложений и дата-аналитиков рассмотрим новый оптимизатор этого фреймворка, Radiant. Он основан на SQL-оптимизаторе Catalyst и представляет собой open-source проект от энтузиастов сообщества Apache Spark. Читайте далее, чем хорош Spark-Radiant и как использовать его для оптимизации SQL-запросов при аналитике больших данных. Что такое SQL-оптимизатор Spark-Radiant и...

При том, что Apache Airflow сегодня считается главным инструментом дата-инженерии, он далеко не единственное средство оркестрации пакетных заданий и построения конвейеров обработки больших данных. В рамках продвижения наших курсов для инженеров Big Data, сегодня рассмотрим, что такое Apache Hop, чем это отличается от AirFlow и где использовать эту платформу, а...

Реклама является одним из наиболее крупных сегментов практического применения технологий Big Data. Поэтому сегодня рассмотрим, как Flink SQL реализует потоковую аналитику больших данных в AdTech-кейсах. Разбираем пример JOIN-соединения двух потоков событий - показов и кликов, чтобы вычислить конверсию рекламной кампании средствами Apache Flink или Spark. Потоки Big Data за фасадом...
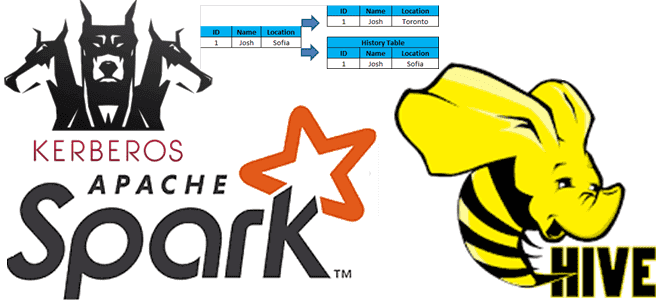
В этой статье для разработчиков распределенных приложений Apache Spark, администраторов SQL-on-Hadoop и дата-аналитиков рассмотрим особенности аутентификации удаленного пользователя, а также отслеживание измененных данных в таблицах Apache Hive. Читайте далее, зачем ограничивать доступ к keytab-файлу в кластерах с поддержкой защищенного протокола Kerberos, а также как реализовать отслеживание медленно меняющихся измерений в...

В рамках обучения разработчиков Spark-приложений, сегодня рассмотрим, как сохранить датафрейм в памяти вне кучи исполнителя и зачем это нужно. Вас ждет краткий ликбез по управлению памятью в Apache Spark с описанием настраиваемых конфигураций. Также на простом практическом примере разберем, как это сделать и где в пользовательском веб-интерфейсе фреймворка посмотреть результаты...

В этой статье для дата-инженеров мы собрали лучшие практики построения масштабируемых конвейеров обработки данных, а также популярные рекомендации по проектированию ETL/ELT-процессов с Apache Spark, AirFlow и другими технологиями Big Data. Читайте далее, когда ELT лучше ETL и наоборот, чем хорош Apache Spark в конвейерах обработки Big Data, зачем нужен AirFlow,...