
Продолжая разговор про рассмотренные в прошлой статье принципы взаимодействия процессов Python с Java, на которой написан Apache NiFi, сегодня разберем, как использовать это на практике. Пишем свои процессоры, используя классы FlowFileTransform и RecordTransform. Python-процессор Apache NiFi на базе FlowFileTransform Хотя Apache NiFi предоставляет более 300 процессоров для вычислительных операций и...
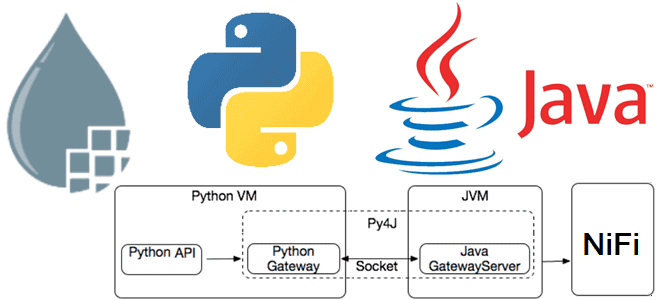
Недавно мы писали про Nifi-Python-Api —клиентский SDK, поддерживающий Python для работы с Apache NiFi. Сегодня на примере разработки процессоров более подробно разберем принципы взаимодействия процессов Python с Java, на которой написан Apache NiFi. Принципы работы Python-кода в Java-среде Apache NiFi Поскольку Apache NiFi написан на Java, именно этот язык предпочтителен...
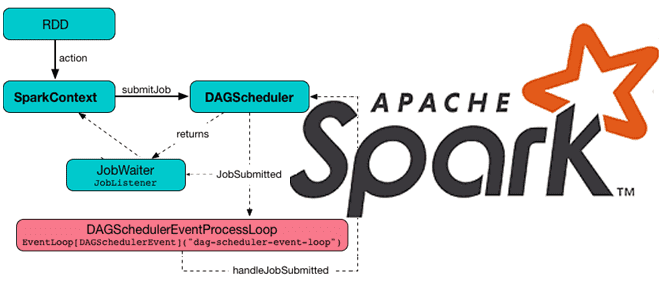
Какие механизмы и компоненты позволяют Apache Spark планировать задания и эффективно утилизировать ресурсы кластера. Чем статическое разделение ресурсов отличается от динамического, и как настроить планировщик для ускорения вычислений. Планирование заданий в Apache Spark Распределенный характер Apache Spark предполагает наличие инструментов для разделения ресурсов между вычислениями. В режиме кластера каждое приложение...

14 декабря 2023 года вышел очередной релиз Apache AirFlow, который содержит более 20 новых фичей, 60 улучшений и 50 исправлений. Знакомимся с самыми главными для дата-инженера новинками выпуска 2.8. ТОП-10 новинок Apache AirFlow 2.8 Многие обновления в версии 2.8 направлены на расширение возможностей создания DAG, улучшение ведения журналов и исправление...
Сегодня разберем, как повысить эффективность использования объектов XCom в Apache AirFlow и сделать свои конвейеры обработки данных еще более гибкими с помощью настройки триггерных правил. Возможности TaskFlow API для XCom Объекты XCom позволяют задачам DAG в Apache AirFlow обмениваться данными. Это очень удобно для реализации конвейера с атомарными задачами, которые...
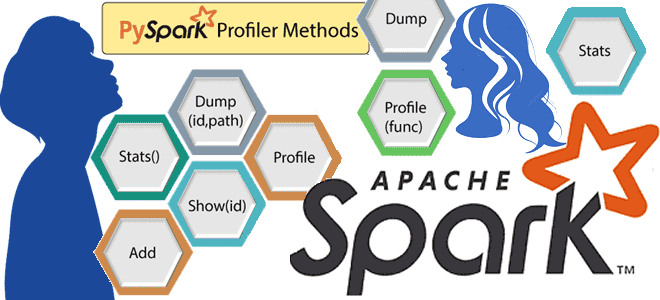
Что такое профилирование кода, зачем это нужно и как работают Python-профилировщики в приложениях Apache Spark. Пример профилирования PySpark-программы. Что такое профилирование и почему это важно для PySpark-приложений Будучи написанном на java и Scala, Apache Spark также поддерживает декларативные API-интерфейсы Python, которые позволяют разработчику писать и запускать код на этом более...
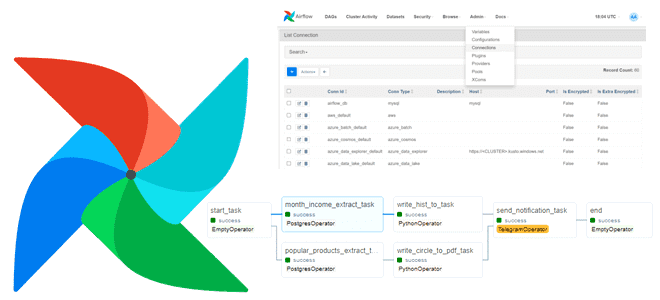
Сегодня на практическом примере посмотрим, как запускать в DAG Apache AirFlow параллельное исполнение нескольких задач, применим пару лучших практик реализации ETL-конвейера для работы с PostgreSQL, а также разберем неоднозначности программного добавления соединений с внешними системами. Постановка задачи Предположим, необходимо получить аналитику по продажам товаров интернет-магазина, выгрузив данные из PostgreSQL в...
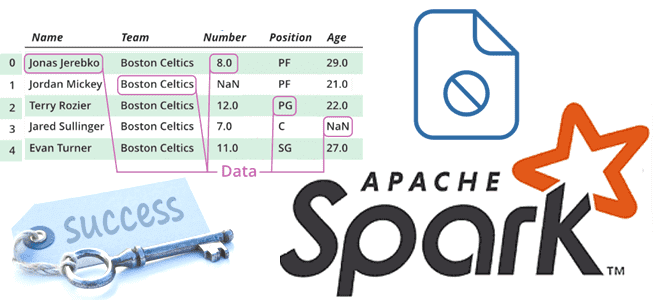
Когда и зачем Spark-приложение создает файл _SUCCESS, почему в нем нет данных, как его использовать, можно ли обойтись без него и как это сделать. Пример запуска PySpark-приложения в Google Colab. Когда и зачем Spark-приложение создает файл _SUCCESS В Apache Spark при выполнении операций записи с использованием таких методов, как saveAsTextFile(),...

Недавно мы писали об анонсированных новинках Apache NiFi 2.0. Наконец, 25 ноября 2023 года этот долгожданный мажорный релиз опубликован. Знакомимся с главными новостями версии 2.0, в которой более 900 обновлений, включая новые функции, улучшения и исправления ошибок. ТОП-7 новинок в Apache NiFi 2.0 Прежде всего, важной новинкой NiFi 2.0 является...
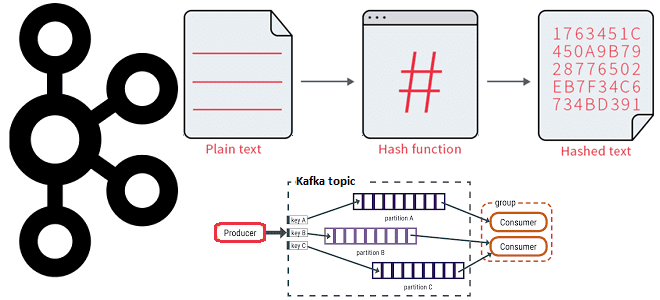
Как работает распределение сообщений по разделам топика Kafka с явно заданным ключом партиционирования и на что влияет язык разработки приложения-продюсера при использовании этой стратегии. 3 стратегии распределения сообщений по разделам в Apache Kafka В Apache Kafka единицей параллелизма выступает раздел топика. Используя несколько разделов, можно распределять нагрузку на брокеров в...
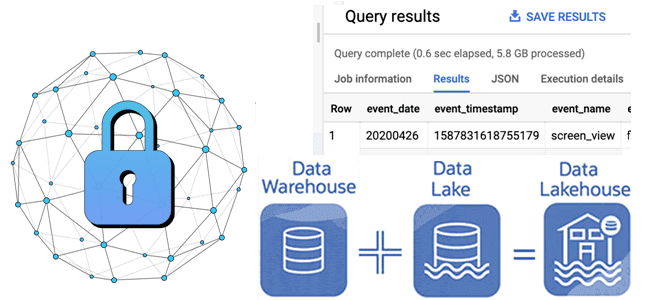
Как отметки времени о событиях в архитектуре данных Lakehouse позволяют обеспечить безопасность Delta Lake: примеры извлечения и преобразования, а также лучшие практики. Почему отметки времени в логах системных событий так важны для архитектуры больших данных Архитектура Lakehouse построена на открытых стандартах и API, которые позволяют сочетать ACID-транзакции и управление данными...

Как управлять средой PySpark-приложения в распределенной вычислительной среде: проблемы зависимостей Python в кластере и способы их решения с помощью сеансов Spark Connect в версии 3.5.0. Управление зависимостями в Python и PySpark Каждый Python-разработчик хотя бы раз сталкивался с проблемой несовместимости пакетов. Эта ситуация называется ад зависимостей (dependency hell), когда вновь...

Что не так с Neosemantics и зачем нужна очередная библиотека для Neo4j: знакомство с Python-пакетом для RDF-графов rdflib-neo4j. Возможности, ограничения и пример использования. Что не так с Neosemantics и зачем нужна очередная библиотека для Neo4j Что такое RDF-графы, триплеты и плагин Neosemantics для работы с этими концепциями в графовой СУБД...

Что представляет собой MLOps-платформа Tecton и как запустить на ней конвейеры машинного обучения, используя провайдер Tecton-AirFlow, чтобы управлять ресурсами Tecton в этом ETL-оркестраторе. Что такое Tecton и при чем здесь MLOps Поскольку концепция MLOps направлена на безбарьерную автоматизацию всех этапов жизненного цикла систем машинного обучения, для этого нужны специализированные средства....
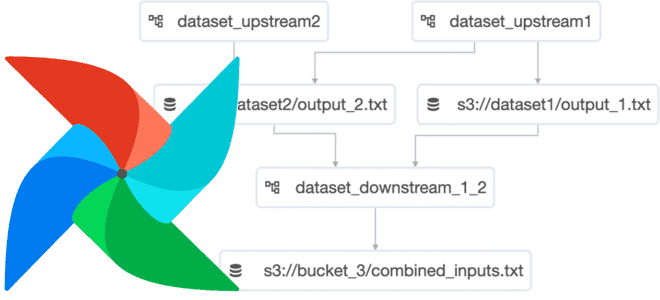
Что такое набор данных в Apache AirFlow и как эта концепция обмена данными между задачами разных DAG улучшает управляемость ETL-конвейера и повышает производительность фреймворка. Что такое набор данных в Apache AirFlow и где это использовать Набор данных (Dataset) – это замена логической группировки данных в Apache AirFlow. Наборы данных могут...
Как расширить возможности Apache NiFi, используя Python: знакомимся с библиотекой NiPyAPI. Возможности, принципы работы и примеры использования NiPyAPI в управлении средой NiFi: очистка от неиспользуемых компонентов. Python в Apache NiFi Хотя официальная поддержка Python ожидается в релизе 2.0, о чем мы писали здесь, использовать этот язык программирования в Apache NiFi...
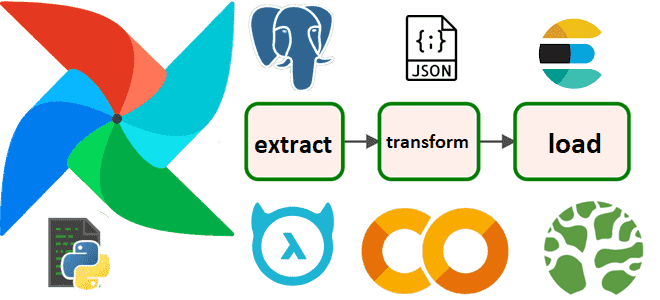
Пример ETL-процесса в DAG Apache AirFlow: извлечение данных о выполненных заказах из PostgreSQL, преобразование в JSON-документ и загрузка в NoSQL-хранилище Elasticsearch в виде JSON-документа с отправкой уведомления в Telegram. Разработка и запуск кода в Google Colab. Постановка задачи и проектирование конвейера в виде DAG AirFlow О том, как построить простой...
Мы уже писали про особенности тестирования систем машинного обучения. Чтобы не повторяться, сегодня рассмотрим фреймворки для реализации идей MLOps, а также рассмотрим, какие тесты должны быть пройдены для проверки работоспособности ML-продукта. 3 категории тестов для ML-систем Согласно концепции MLOps, полный конвейер разработки включает в себя три основных компонента: конвейер данных,...

Насколько быстро работает Apache Kafka в облачной платформе Upstash: пишем простой пример для пары продюсер-потребитель на Python и измеряем задержку. Миллисекундное отставание при публикации и минутная задержка обработки данных на потребителе. Задержка публикации сообщений в Kafka Чтобы измерить задержку асинхронного обмена данными в системе с EDA-архитектурой из продюсера и потребителя...

Каждому специалисту по Data Science и инженеру данных знакома Python-библиотека pandas. Однако, для работы с большими данными она не очень подходит из-за высокого потребления памяти. Тем не менее, отказаться от старых привычек сложно. Поэтому разбираемся, зачем использовать API Pandas в Apache Spark и как это сделать наиболее эффективно. Чем отличается...