
В одной из статей мы говорили о TaskFlow API, который позволяет задачам передавать и получить друг от друга информацию. За кулисами этого приема и передачи в Apache Airflow лежит XCom. Сегодня расскажем вам о том, как взаимодействуют задачи через XCom, а также, как задаются параметры конфигурации через особые переменные Apache...

В рамках обучения разработчиков Spark-приложений, аналитиков данных и дата-инженеров, сегодня рассмотрим, как улучшить и визуализировать понимание обработки данных в этом Big Data фреймворке. Читайте далее про API встроенных механизмов наблюдения за качеством данных в Apache Spark и открытые библиотеки профилирования на примере Deequ. 2 уровня абстракции мониторинга Spark-приложений для дата-инженера...

Добавляя в наши курсы для дата-инженеров по Apache Airflow полезные примеры, сегодня рассмотрим тонкости контроля доступа к DAG в этой платформе. Читайте далее, какие роли есть в Apache Airflow, каковы разрешения для них и как Flask AppBuilder осуществляет управление доступом к пользовательскому интерфейсу веб-сервера. Безопасность DAG’ов в Apache AirFlow: роли...

Когда имеются графы (dags), зависимые от других, то лучше всего объединить их в один или использовать TaskGroup, о котором говорили в прошлой статье. Но если по каким-то причинам сделать это не удается, то Apache Airflow предоставляет различные способы запуска графа внутри другого. Одним из таких является TriggerDagRunOperator. В этой статье...
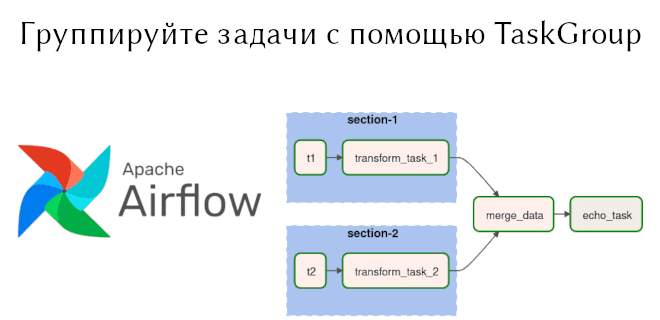
В предыдущей статье мы рассмотрели TaskFlow API, появившийся в Apache Airflow 2.0. Сегодня поговорим о способах задания операторов, отличных от PythonOperator, а также о способе группировки задач TaskGroup. Читайте далее: как сформировать BashOperator, используя TaskFlow API, когда следует использовать TaskGroup, в чем преимущества TaskGroup перед SubDag. Используем Bash Operator в...

В предыдущей статье мы говорили о том, как начать работать с Apache Airflow. Сегодня пойдет речь о новом инструменте, появившемся в Airflow 2, — TaskFlow API. Он обеспечивает кросс-коммуникацию между задачами с помощью обычных функций Python. На примере ETL-конвейера мы объясним, как соорудить DAG на основе TaskFlow API, а также...
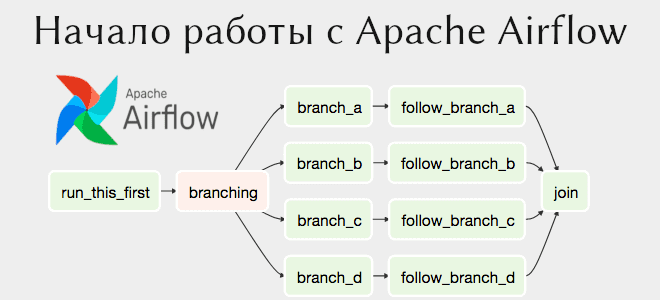
В прошлой статье мы рассмотрели установку Apache Airflow на свой компьютер. Данная платформа предназначена для планирования задач, например, выполнения скриптов Bash и Python в заданное время, в заданной последовательности. Сегодня на примере выполнения двух Bash-команд расскажем, как создать свой первый граф. Читайте в этой статье: связи между задачами, создание графа...
Чтобы добавить в курсы по Apache AirFlow еще больше полезных примеров, сегодня рассмотрим, как избежать дублирования кода при загрузке данных. Этот пример пригодится дата-инженерам в работе с ELT-процессами наполнения информацией корпоративных хранилищ и озер данных. Читайте про фреймворк динамической загрузки данных на базе конфигурационных YAML-файлов, DAG-фабрик и загрузчиков. Проблема дублирования...

Чтобы дополнить наши курсы по Kafka и Spark интересными примерами, сегодня рассмотрим практический кейс разработки микросервисного конвейера машинного обучения на этих фреймворках. Читайте далее, зачем выносить ML-компонент в отдельное Python-приложение от остальной части Big Data pipeline’а, и как Docker поддерживает эту концепцию микросервисного подхода. Постановка задачи и компоненты микросервисного ML-конвейера...

Сегодня в рамках обучения разработчиков Apache Spark и дата-аналитиков, поговорим про детерминированность UDF-функций и особенности их обработки оптимизатором SQL-запросов Catalyst. На практических примерах рассмотрим, как оптимизатор Spark SQL обрабатывает недетерминированные выражения и зачем кэшировать промежуточные результаты, чтобы гарантированно получить корректный выход. Еще раз про детерминированность функций и планы выполнения...

Мы уже писали про преимущества разделения пакетов в Apache AirFlow 2.0. Сегодня рассмотрим, как открытый реестр Python-пакетов от компании Astronomer облегчает разработку конвейеров обработки данных, чем провайдеры отличаются от модулей и насколько удобно дата-инженеру всем этим пользоваться. От монолита к мульти-пакетной архитектуре в Apache Airflow 2.0 Напомним, во 2-ой версии...

Сегодня рассмотрим, как упростить работу дата-инженера в Apache AirFlow, автоматизировав процесс создания DAG’ов из одного или нескольких Python-файлов. На практических примерах разберем достоинства и недостатки 5 способов динамической генерации, а также особенности масштабирования Big Data pipeline’ов. Что такое динамическая генерация DAG в Apache Airflow и зачем она нужна В статье...

В рамках практического обучения дата-инженеров сегодня мы собрали 10 лучших практик проектирования конвейеров обработки данных в рамках Apache AirFlow, которые касаются не только особенностей этого фреймворка. Также рассмотрим, какие принципы разработки ПО особенно полезны для инженерии больших данных с Apache AirFlow. ТОП-10 рекомендаций дата-инженеру для настройки Apache Airflow и не...
Добавляя в наши курсы по Apache AirFlow еще больше полезных практик, сегодня разберем опыт дата-инженеров американской компании Groupon по настройке этого фреймворка. Читайте далее, как добавить собственные KPI исполнения конвейеров обработки данных в эту workflow-платформу, делая его веб-GUI более наглядным и удобным для управления DAG’ами. Типовые возможности веб-GUI Apache Airflow...

Развивая наши курсы по Apache AirFlow для дата-инженеров и администраторов, сегодня рассмотрим, как автоматизировать обслуживание этого фреймворка, запуская поддерживающие операции как рабочие задачи по расписанию. В этой статье разбираем опыт дата-инженеров американской ИТ-компании Clairvoyant, предложивших сообществу 3 разных DAG по обслуживанию Apache AirFlow в виде open-source проектов, доступных для свободного...
Продвигая наши курсы по Apache Spark для разработчиков, сегодня рассмотрим пользовательские функции и особенности работы с ними в API SQL-модуле этого фреймворка. Читайте далее про идемпотентность UDF-функций и их влияние на распределение данных в кластере Apache Spark. Как устроены UDF в Apache Spark: краткий ликбез Пользовательские функции (User Defined Functions,...

В сферу ответственности дата-инженера входит не только проектирование быстрых и производительных конвейеров обработки данных, но обеспечение их надежности, в т.ч. с точки зрения информационной безопасности. Сегодня рассмотрим, как управлять чувствительной информацией (секретами) в Apache AirFlow, каких видов они бывают, где хранятся и что нужно сделать, чтобы не отображать их в...
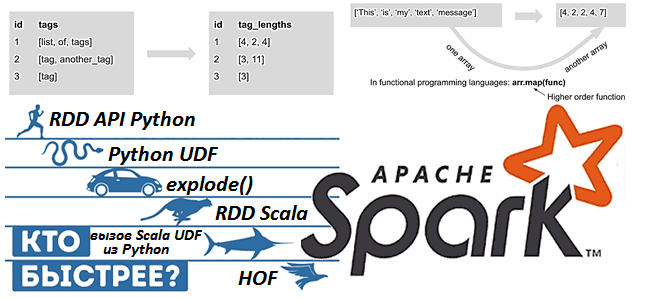
Apache Spark предоставляет для разработчика распределенных приложений множество возможностей, позволяя достигать одной целей разными способами. Чтобы проиллюстрировать это, сегодня рассмотрим бенчмаркинговое сравнение 9 методов обработки массивов в Spark 3.1, обращая внимание на их производительность и особенности использования. Также разберем важные для обучения разработчиков Spark темы про отличия преобразований от действий...

Apache Spark + AirFlow – известная каждому дата-инженеру комбинация технологий Big Data для запуска сложных конвейеров обработки данных. Но совместное использование этих фреймворков ограничено недостатками AirFlow, часть из которых можно обойти с помощью Apache Livy. Однако эксплуатация AirFlow менее удобна, чем Dagster. Поэтому сегодня рассмотрим, как этот альтернативный оркестратор данных...

Apache AirFlow – это не только инструмент планирования batch-процессов, но и средство мониторинга ETL-задач и конвейеров обработки данных. Однако, наблюдать за выполнением data pipeline’а в веб-интерфейсе этого фреймворка не всегда удобно. Читайте далее, с какими проблемами AirFlow сталкиваются дата-инженеры и как альтернативный оркестратор Dagster позволяет решить их. Проблемы мониторинга data...