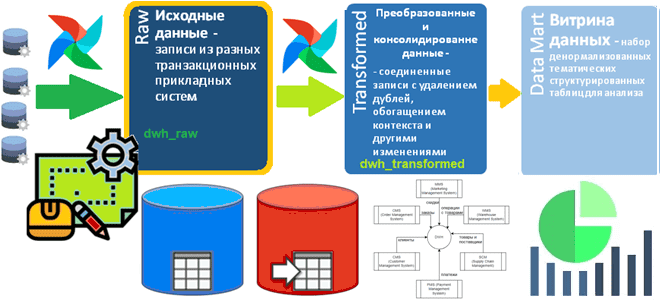
Как определить структуру Raw-слоя корпоративного хранилища данных: пример проектирования и DDL-скрипт для кейса электронной коммерции, выбор компонентов решения для архитектуры данных. Постановка задачи: анализ систем-источников Сегодня корпоративные хранилища данных (DWH, Data Warehouse) обычно реализуются в виде нескольких баз данных, связанных ETL-процессами. Причем каждая из этих гомогенных или гетерогенных, т.е. на...

Как найти зависший процесс в базе данных Greenplum, создать резервную копию каталога, разделить лог-файл по тестам и проверить его на наличие повреждений. Знакомимся с набором утилит gpsupport. 6 инструментов утилиты gpsupport для техподдержки Greenplum Как и любая крупная система Greenplum, помимо компонентов, обеспечивающих ее ключевые функции, также включает дополнительные инструменты,...

Как с помощью Flink SQL организовать потоковую агрегацию данных из таблицы PostgreSQL: знакомство с API таблиц в Ververica Cloud на практическом примере. API таблиц Ververica Cloud: создаем внешние источники и приемники данных Как я недавно рассказывала, немецкая фирма Ververica создала высокопроизводительный облачный сервис для обработки данных в реальном времени на...
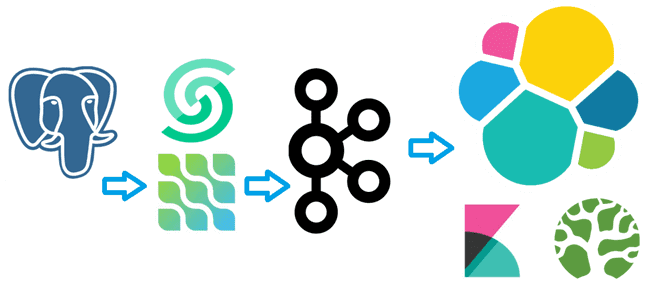
Недавно я писала, как с помощью source-коннектора Debezium организовать потоковый захват изменения данных из таблицы PostgreSQL путем публикации CDC-событий в Apache Kafka. Продолжая эту тему, сегодня покажу пример визуализации аналитики этих данных в Kibana, предварительно загрузив их в Elasticsearch с sink-коннектором Aiven. Постановка задачи и проектирование конвейера Как обычно, в...
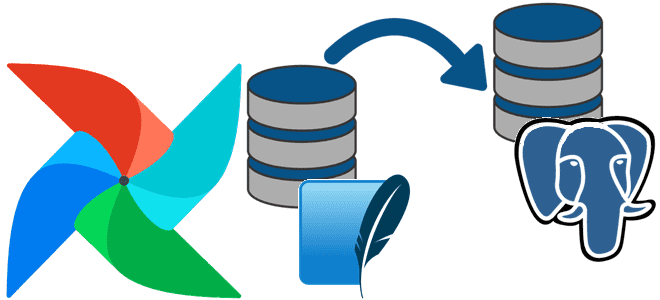
Зачем менять базу данных метаданных в производственном развертывании Apache AirFlow и как это сделать: пошаговое руководство для дата-инженера с примерами и рекомендациями. 5 шагов перехода от SQLLite к PostgreSQL: миграция базы данных метаданных Apache AirFlow Чтобы планировать и запускать конвейеры обработки данных, Apache AirFlow хранит сведения о задачах, DAG, исполнителях,...
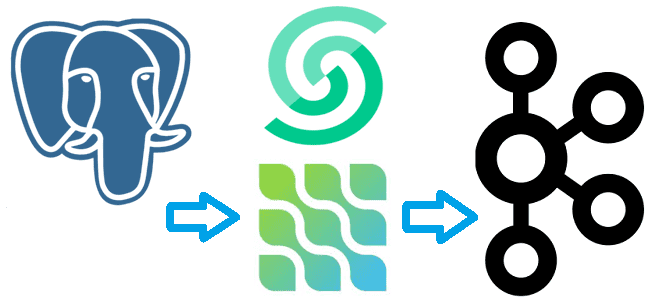
Сегодня я покажу на практическом примере, как реализовать потоковый захват изменения данных из таблицы PostgreSQL и их репликацию в Apache Kafka с помощью Debezium. Создаем и настраиваем свой коннектор на платформе Upstash. Постановка задачи Паттерн захвата измененных данных (CDC, Change Data Capture) является одним из самых распространенных в инженерии данных....
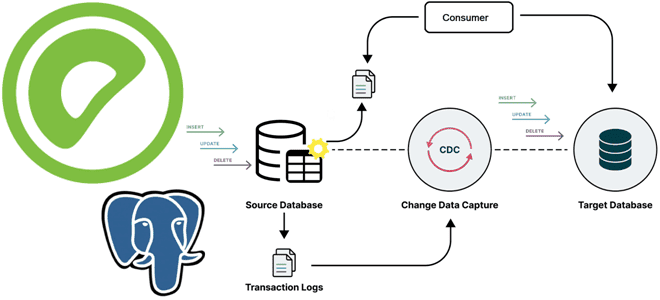
Методы отслеживания изменений в реляционных базах данных: столбцы аудиты, триггеры DDL-событий и WAL-журналы. Плюсы и минусы этих подходов, а также примеры реализации в Greenplum и PostgreSQL. 3 подхода к извлечению данных из реляционных баз Извлечение данных из реляционных баз является наиболее распространенной операцией в ETL-процессах. Поэтому при проектировании конвейеров обработки...

Сегодня познакомимся с возможностями и ограничениями open-source проект Diskquota, направленного на оптимизацию управления дисковым пространством базы данных Greenplum. Зачем ограничивать использование диска в Greenplum и как это сделать Эффективная утилизация аппаратных ресурсов, в т.ч. жесткого диска – один из факторов, позволяющих ускорить работу любой СУБД, в т.ч. Greenplum. Будучи популярным...
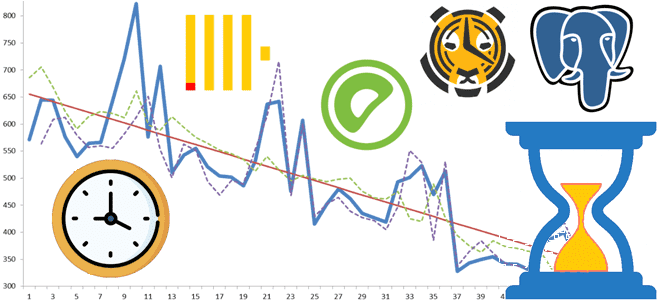
Анализ временных рядов нужен не только в Data Science, но и в мониторинге системных событий. Чем столбец с отметками времени в ClickHouse отличается от гипертаблиц в PostgreSQL и Greenplum c расширением TimescaleDB, и что выбирать для аналитики больших данных. ClickHouse для анализа временных рядов ClickHouse является колоночной СУБД для аналитической...
Как выполнить миграцию данных: лучшие практики и рекомендации на примере Greenplum. Особенности и принципы работы утилит gpbackup, gprestore и gpcopy. Миграция данных из Greenplum на 7 с утилитами gpbackup и gprestore Независимо от причины миграции данных из прикладной системы или корпоративного хранилища данных на новую технологию, эта процедура всегда остается...
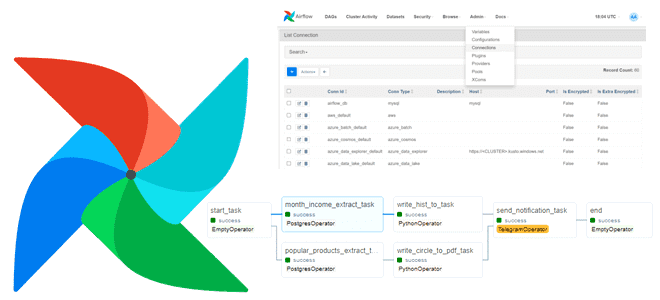
Сегодня на практическом примере посмотрим, как запускать в DAG Apache AirFlow параллельное исполнение нескольких задач, применим пару лучших практик реализации ETL-конвейера для работы с PostgreSQL, а также разберем неоднозначности программного добавления соединений с внешними системами. Постановка задачи Предположим, необходимо получить аналитику по продажам товаров интернет-магазина, выгрузив данные из PostgreSQL в...

Сходства и различия популярных реляционных аналитических СУБД с открытым исходным кодом: что общего у Greenplum с ClickHouse, чем они отличаются, что и когда выбирать. Greenplum и Clickhouse: обзор возможностей для аналитики больших данных Обе СУБД являются реляционными и относятся к классу OLAP-систем, т.е. ориентированы на аналитические варианты использования, т.е. чтение...
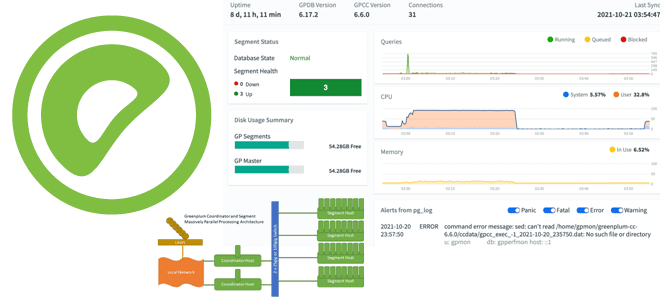
Что такое VMware Greenplum Command Center, как использовать этот инструмент для эффективного управления MPP-СУБД и чем он отличается от Arenadata Command Center для Arenadata DB. Что такое центр управления Greenplum от VMware VMware Greenplum Command Center — это инструмент управления, который отслеживает показатели производительности системы, анализирует состояние кластера и позволяет...

Продолжая тему недавней статьи про настройки Greenplum 7, сегодня рассмотрим еще несколько конфигураций, которые позволят сделать эту MPP-СУБД еще быстрее и надежнее. Глобальные конфигурации Greenplum для настройки рабочих файлов Параметры глобальной конфигурации пользователя (GUC, Global User Configuration) Greenplum могут быть как глобальными, так и локальными по отношению к экземплярам сегмента. Глобальные...

Что настроить в Greenplum 7, чтобы сделать эту MPP-СУБД еще эффективнее. Обзор наиболее популярных параметров конфигурации и рекомендации по установке их значений. Ограничения подключений и выполнения SQL-запросов: 6 параметров с перезагрузкой системы Будучи зрелой системой со множеством настроек, Greenplum предоставляет администратору и дата-инженеру широкие возможности по адаптации этой СУБД к...

Как использовать Greenplum в проектах машинного обучения: знакомимся с расширением PostgresML и модулем pgvector. Возможности и ограничения плагинов, превращающих MPP-СУБД в полноценный MLOps-инструмент. Как превратить Greenplum в векторную базу данных с расширением pgvector Будучи вариацией PostgreSQL с механизмами массово-параллельной загрузки, Greenplum отлично справляется с огромным объемом данных. Однако, к хранилищам...

Почему в Greenplum 7 восстановление данных из резервной копии базы стало медленнее и как разработчики это исправили: причины замедления и способы их устранения. SQL-синтаксис и восстановление из бэкапа Напомним, 7-ой релиз Greenplum имеет много интересных и полезных функций, включая возможность определять партиционированную таблицу без определения дочерних разделов и изменять таблицы...
Сегодня усложним пример из прошлой статьи с простым ETL-конвейером, который добавлял в базу данных интернет-магазина новые записи о клиентах, сгенерированные с помощью библиотеки Faker. Разбираем, как удалить из PostgreSQL данные об успешно доставленных заказах за прошлый месяц, предварительно сохранив их в JSON-файл с многоуровневой структурой. Пишем и запускаем DAG Apache...
Сегодня реализуем простой ETL-конвейер для реляционной СУБД PostgreSQL, запустив Apache AirFlow в интерактивной среде Google Colab. Пример DAG из 3-х задач: получить количество строк в одной из таблиц БД, сгенерировать новые строки и записать их, не нарушив ограничений уникальности первичного ключа. Постановка задачи Возьмем в качестве примера базу данных для...
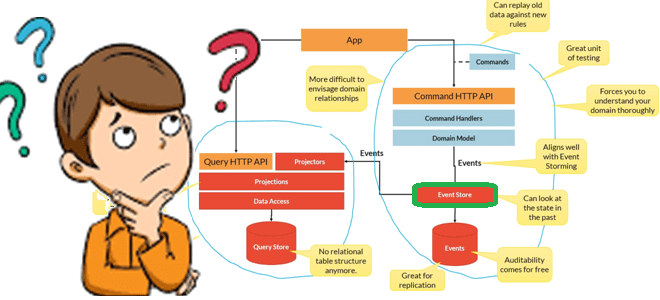
Что представляет собой паттерн проектирования микросервисов под названием источник событий (Event Sourcing) и как его реализовать в реляционных базах данных и NoSQL-системах. Разбираемся с архитектурой данных и архитектурой ПО на практических примерах. Архитектурный шаблон Event Sourcing Многие архитектурные шаблоны рассматривают сущности (entity) как основную концепцию, описывая способы их сохранения и...