
Для практического использования Apache Airflow в production дата-инженеру необходимо не только обучение основам работы с этим фреймворком, но и знания о базовой инфраструктуре его развертывания. Поэтому сегодня поговорим о 3-х популярных средах для развертывания и сопровождения этого ETL-фреймворка: Astronomer, Google Cloud Composer и Amazon Managed Workflows, разобрав их основные возможности...

Продолжая разговор про оптимизацию приложений Apache Spark в Kubernetes, сегодня разберем, как сократить расходы на облачный кластер с помощью спотовых узлов. А в качестве практического примера рассмотрим кейс компании Weather2020, дата-инженеры которой смогли всего за 3 недели развернуть террабайтные ETL-конвейеры в AWS с AirFlow и Spark на Kubernetes без глубокой...

Недавно мы рассказывали об особенностях запуска приложений Apache Spark в кластере Kubernetes с учетом новшеств релиза 3.1.1, где с этого варианта развертывания снят экспериментальный режим. В дополнение к ранее рассмотренным способам оптимизации Спарк-приложений, сегодня разберем, как инженеру Big Data ускорить их при запуске на платформе K8s. Как ускорить Spark-приложения на...

Вчера мы упоминали, что с марта 2021 года в версии Apache Spark 3.1.1 с развертывания на Kubernetes снят экспериментальный режим, внесено множество улучшений для стабильной работы контейниризованных приложений и добавлены другие полезные обновления. Читайте далее, почему развертывание Spark на Kubernetes стало еще проще, как реализуется плавное завершение работы узла без...

С учетом тренда на контейнеризацию при разработке и развертывании любых технологий, в т.ч. Big Data, сегодня рассмотрим плюсы и минусы совместного использования Apache Spark с Kubernetes. Читайте далее, как отправить Спарк-задание в кластер Кубернетес и почему это сэкономит затраты на вашу инфраструктуру аналитики больших данных, не повысив производительность отдельных приложений,...
В этой статье поговорим про KSQL на примере кейса компании американской компании Pluralsight, которая предлагает различные обучающие видео-курсы для разработчиков ПО, ИТ-администраторов и творческих профессионалов. Читайте далее, как использовать Apache Kafka с Kubernetes для построения надежных систем потоковой аналитики больших данных, а также чем ksqlDB отличается от KSQL. Apache Kafka...

Хорошие курсы дата-инженеров предполагают не только изучение теории и практики, но и проверку полученных знаний. Поэтому сегодня мы предлагаем вам открытый интерактивный тест по Apache AirFlow. Ответьте на 10 простых вопросов и узнайте, насколько хорошо вы знакомы с особенностями администрирования и эксплуатации этого популярного фреймворка для автоматизации batch-заданий обработки и...
Поскольку курсы инженеров Big Data предполагают практическое обучение на реальных кейсах, сегодня поговорим про тестирование конвейеров обработки и аналитики больших данных и разберем несколько прикладных примеров для компонентов экосистемы Apache Hadoop. Читайте далее про проверку работоспособности, а также поиск ошибок в Spark-заданиях и DAG-цепочках Airflow. Конвейер для конвейера: сложности тестирования...

Вчера мы говорили про сложности развертывания множества stateful-приложений Apache Kafka Streams в кластере Kubernetes и роль контроллера StatefulSet, который поддерживает состояние реплицированных задач за пределами жизненного цикла отдельных подов. В продолжение этой темы, сегодня рассмотрим механизм проб, которые позволяют определить состояние распределенного приложения, развернутого на платформе контейнерной виртуализации. В качестве...
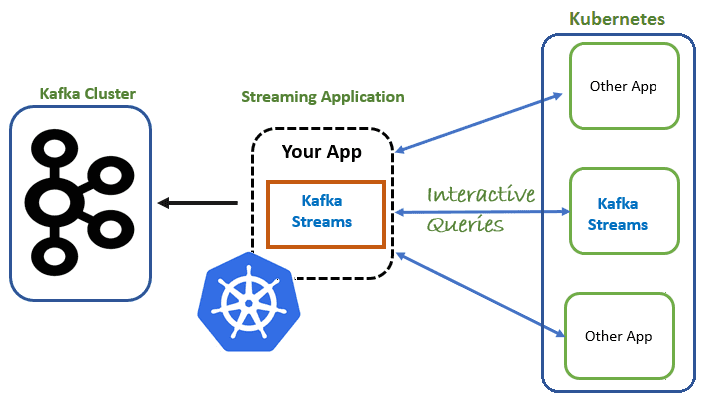
Сегодня рассмотрим особенности запуска приложений Apache Kafka Streams для потоковой обработки больших данных с отслеживанием состояния в кластере Kubernetes. Читайте далее, в чем проблема управления stateful-приложениями Kafka Streams в Kubernetes и как ее решает контроллер StatefulSet. Что обеспечивает хранение состояний в Apache Kafka Streams Напомним, Kafka Streams – это легковесная...

В рамках обучения инженеров больших данных, вчера мы рассказывали о новой версии Apache AirFlow 2.0, вышедшей в декабре 2020 года. Сегодня рассмотрим особенности перехода на этот релиз: в чем сложности миграции и как их решить. Читайте далее про сохранение кастомизированных настроек, тонкости работы с базой метаданных и конфигурацию для развертывания...

В конце 2020 года вышел мажорный релиз Apache AirFlow, основные фишки которого мы рассмотрим в этой статье. Читайте далее про 10 главных обновлений Apache AirFlow 2.0, благодаря которым этот DataOps-инструмент для пакетных заданий обработки Big Data стал еще лучше. 10 главных обновлений Apache AirFlow 2.0 Напомним, разработанный в 2014 году...

Чтобы добавить в наш новый курс по Apache Kafka для разработчиков еще больше практических примеров, сегодня мы приготовили для вас кейс немецкой железнодорожной компании Deutsche Bahn AG. Читайте далее, почему приложения Kafka Streams заменили Apache Storm и как крупнейшая транспортная компания Германии построила собственную информационную платформу на базе Apache Kafka,...
Чтобы максимально приблизить обучение Airflow к практической работе дата-инженера, сегодня мы рассмотрим, какие еще есть альтернативы для оркестрации ETL-процессов и конвейеров обработки больших данных. Читайте далее, что такое Luigi, Argo, MLFlow и KubeFlow, где и как они используются, а также почему Apache Airflow все равно остается лучшим инструментом для оркестрации...

Мы уже рассказывали про основные достоинства и недостатки Apache Airflow, с которыми чаще всего можно столкнуться при практическом использовании этого оркестратора конвейеров обработки больших данных (Big Data). Сегодня рассмотрим некоторые специфические ограничения, характерные для этой open-source платформы и способы решения этих проблем на реальных примерах. Все по плану: 5 особенностей...

Сегодня мы продолжим разговор о событийно-процессной архитектуре Big Data систем на примере использования Apache Kafka в The New York Times. Читайте далее, как одно из самых известных американских СМИ с более чем 160-летней историей хранит в Apache Kafka все свои статьи и с помощью API Kafka Streams публикует контент в...
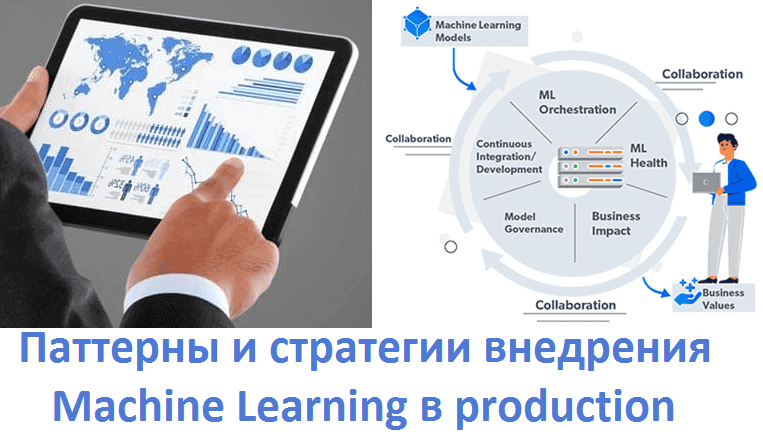
Завершая цикл статей про MLOps, сегодня мы расскажем про 5 шаблонов практического внедрения моделей Machine Learning в промышленную эксплуатацию (production). Читайте далее, что такое Model-as-Service, чем это отличается от гибридного обслуживания и еще 3-х вариантов интеграции машинного обучения в production-системы аналитики больших данных (Big Data), а также при чем тут...

Самообслуживаемая аналитика больших данных – один из главных трендов в современном мире Big Data, который дополнительно стимулирует цифровизация. В продолжение темы про self-service Data Science и BI-системы, сегодня мы рассмотрим, что такое Cloudera Data Science Workbench и чем это зарубежный продукт отличается от отечественного Arenadata Analytic Workspace на базе Apache...

Продолжая разговор про обучение Spark на реальных примерах, сегодня мы рассмотрим, как работает этот Big Data фреймворк на Kubernetes, популярной DevOps-платформе автоматизированного управления контейнеризированными приложениями. Читайте в нашей статье, как запустить приложение Apache Spark в кластере Kubernetes (K8s) с помощью submit-скрипта и оператора, а также при чем здесь Docker-образ. Запуск...

Вчера мы рассказывали об основных сценариях запуска Apache Spark на Kubernetes и преимуществах этого варианта развертывания популярного Big Data фреймворка на DevOps-платформе автоматизированного управления контейнеризированными приложениями. Сегодня поговорим про обратную сторону всех этих преимуществ: читайте в нашей статье, каковы основные ограничения и главные недостатки запуска Apache Spark на Kubernetes (K8s)....