
Как организовать удобный мониторинг за приложениями Apache Spark в кластере Kubernetes с помощью Prometheus и Grafana: пошаговый guide для администраторов и дата-инженеров с примерами. Создаем свою альтернативу наглядным дэшбордам AWS EMR с Java-библиотекой Dropwizard Metrics и средством настройки оповещений Alertmanager. Не только AWS EMR или как следить за Spark-приложениями в...

В рамках обучения дата-инженеров и ML-специалистов лучшим практикам MLOps, сегодня рассмотрим практический пример построения конвейера машинного обучения на Airflow, MLFlow, SageMaker и других сервисах Amazon. А также как Apache Spark версии 3 сократил расходы на облачный EMR-кластер почти в 2 раза. MLOps с AirFlow и MLFlow в облаке AWS Ранее...

Развивая наши курсы по Apache Spark и AirFlow для дата-инженеров и администраторов кластеров, сегодня рассмотрим кейс крупного маркетплейса Joom по переходу от 2-ой версии фреймворка на облачной платформе EMR к развертыванию сотен распределенных заданий на 3-ей версии в Amazon Elastic Kubernetes Service. Про сокращение расходов, повышение производительности и апдейт вычислительных движков. Постановка...
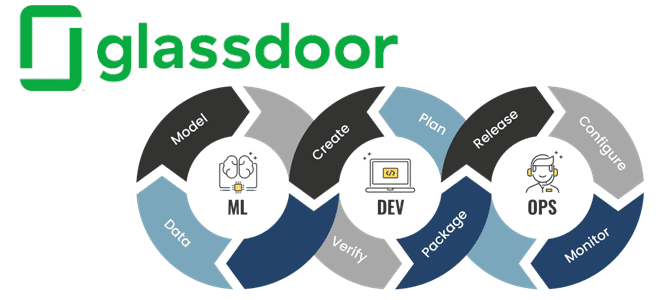
Практическая реализация MLOps-концепции на примере международной рекрутинговой компании Glassdoor. Как построить самоуправляемую автоматизированную систему разработки и сопровождения ML-моделей с MLFlow, Apache Spark и AirFlow, Kubernetes, GitLab, SageMaker Feature Store, Whylogs, Jenkins, Spinnaker и Prometheus с Grafana. Предыстория: зачем MLOps в Glassdoor Glassdoor с 2008 года помогает соискателям по всему миру...

В этой статье для дата-инженеров и администраторов кластеров разберем, как автоматически масштабировать поды Kubernetes с Apache AirFlow в зависимости от метрик рабочей нагрузки из внешней платформы Datadog с помощью демона StatsD, а также ресурса и контроллера HorizontalPodAutoscaler. Автоматическое горизонтальное масштабирование в Kubernetes Одна из сильных сторон Kubernetes заключается в его...

Недавно мы писали про развертывание Apache Kafka на Kubernetes с помощью open-source проекта Strimzi. Сегодня рассмотрим, как обеспечить безопасный доступ к данным на таком кластере, применив различные методы аутентификации и авторизации. Лучшие практики cybersecurity на практическом примере. Постановка задачи: пример приложения с безопасным доступом к данным Напомним, Strimzi – это...

При том, что развертывание и эксплуатация Apache Kafka на Kubernetes требуют от администратора кластера много сил и времени, эта идея имеет массу достоинств, о чем мы писали здесь. Поэтому появляются новые инструменты, которые облегчают эти процессы, например, KubeMQ или Strimzi, который мы рассмотрим в этой статье. Что такое Strimzi и при...
Сегодня разберемся с serverless-технологиями и рассмотрим, как самостоятельно создать и интегрировать бессерверный парсер Selenium с Apache Nifi. Краткий ликбез по OpenFaaS, Selenium и Chromium, а также преимущества serverless-технологий и пример вызова функции сбора данных с веб-страницы на Python. Введение: serverless, OpenFaaS и Selenium с Chromium Serverless-стратегия организации платформенных облачных услуг,...

Недавно мы рассказывали про KubeMQ – stateless-сервис обмена сообщениями для Kubernetes, который может заменить собой сложное развертывание Apache Kafka на этой платформе управления контейнерами. Сегодня разберем, как устроен KubeMQ и сравним его с Apache Kafka по нескольким параметрам, наиболее интересным для разработчиков распределенных приложений и администраторов. Операторы и пользовательские ресурсы...

Сегодня разберем пример европейской логистической компании Sixfold, которая смогла увеличить пропускную способность своей системы мониторинга транспортных отгрузок на базе Apache Kafka и Kubernetes. Также рассмотрим, как дата-инженеры Sixfold справились с проблемами изоляции при последовательной обработке сообщений и транзакционной записи в топики Kafka с базами данных отдельных микросервисов на подах Kubernetes....

Развивая наши курсы для дата-инженеров по Apache AirFlow, сегодня рассмотрим, как автоматизировать развертывание сложных DAG’ов с помощью Docker и Kubernetes на примере управления конвейерами обработки данных. Лучшие практики и советы от инженеров данных DataOps-компании Databand. 4 вопроса дата-инженера к production-развертыванию конвейеров Apache Airflow Apache AirFlow считается одним из самых популярных...

7 ноября 2021 года вышел очередной релиз Apache NiFi с новыми фичами, улучшениями и исправлениями ошибок. Краткий обзор самых важных новинок: от постоянного хранилища для stateless-потоков и настроек облачных провайдеров до интеграции процессоров с пользователями Kerberos и улучшения работы с GitHub. Новинки и улучшения Apache NiFi 1.15.0 Свежий выпуск Apache...
Мы уже писали о сложностях развертывания Apache Kafka на платформе управления контейнерами Kubernetes. Некоторые из этих проблем отлично решает KubeMQ – брокер очередей сообщений на Kubernetes. Зачем нужна очередная служба обмена данными, как она устроена и при чем здесь Kafka. Проблемы Kafka на Kubernetes и не только Сложная архитектура современных...

Сегодня рассмотрим, как организовать полностью сохраняемый сервис Apache NiFi с помощью Docker, чтобы обеспечить безопасность конвейеров и потоков данных при изменении конфигураций и перезапуске служб. А также разберем, как дата-инженеру и администратору кластера NiFi запустить его на Kubernetes. Проблемы масштабирования и отказоустойчивости Apache NiFi Благодаря наличию веб-GUI, множеству готовых процессоров...

Сегодня разберем кейс платформы онлайн-обучения Udemy по разработке собственной системы потоковой аналитики больших данных о событиях пользовательского поведения на Apache Kafka, Hive и сервисах Amazon. Про требования к инфраструктуре отслеживания событий и их реализацию с помощью Apache Kafka, Hive, Kubernetes, AWS S3 и EMR, а также чем AVRO лучше Protobuf....
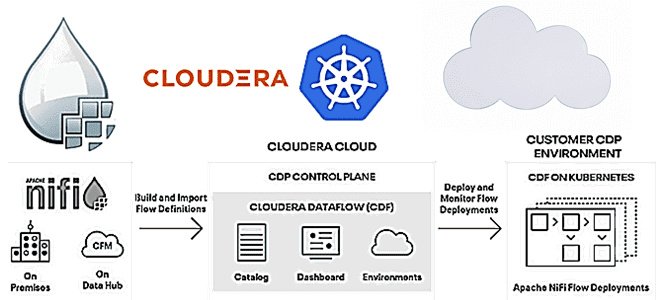
Чтобы сделать наши курсы по Apache NiFi для дата-инженеров еще более полезными, сегодня рассмотрим новые возможности последнего релиза Cloudera Flow Management 2.1.1 на базе этого фреймворка. Выпущенная в апреле 2021 года, платформа Cloudera Flow Management в составе публичного и частного облака предоставляет Apache NiFi версии 1.13.2, включая дополнительные компоненты, а...

В рамках нового курса Эксплуатация Apache NIFI, сегодня разберем особенности развертывания этого маршрутизатора потоков Big Data на платформе управления контейнерными приложениями Kubernetes. Советы дата-инженерам, как сократить расходы на AWS, избежать сбоев узлов и потерь данных, обеспечить безопасность и автоматическое масштабирование облачного кластера Apache NiFi в Amazon EKS, а также зачем...

Продолжая разбирать особенности разработки потоковых приложений Apache Flink, сегодня рассмотрим проблему падения пропускной способности задания из-за встроенного хранилища состояний RocksDB и ее зависимость от производительности дисков. Вас ждет настоящая детективная история о том, как важно заглядывать под капот облачных кластеров и настраивать конфигурации своих stateful-приложений потоковой аналитики больших данных с...

Продолжая сравнивать Apache AirFlow с Dagster, сегодня рассмотрим особенности развертывания и эксплуатации этих оркестраторов ETL-процессов и конвейеров обработки данных. Читайте далее о плюсах изоляции процессов, отделения системных служб от пользовательского кода, сложностях планирования и запуска задач, а также способах их решения с помощью современных инструментов дата-инженера. В изолятор: как развернуть...
Совмещение Airflow с Kubernetes уже становится стандартом де-факто для дата-инженеров. Недавно мы рассказывали про 3 популярные среды развертывания и сопровождения этого ETL-фреймворка в Kubernetes. Продолжая эту тему, сегодня рассмотрим, какие операторы использовать для контейнерного запуска batch-задач, а также поговорим о том, как Docker-образы помогут решить проблему изменения версий Python и...