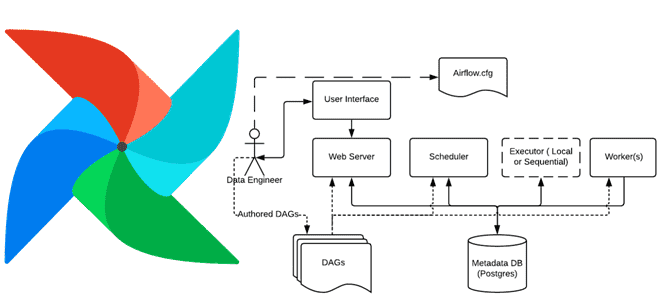
Сегодня рассмотрим, как в Apache AirFlow реализуется обмен данными между задачами с использованием технологии XCom. Чем хорош XCom и почему его не стоит использовать для передачи больших объемов данных: практика организации ETL-конвейеров для дата-инженера. Что такое XCom и зачем это в Apache AirFlow Apache AirFlow не зря является одним из...
В этой статье для обучения дата-инженеров и администраторов кластера разберем способы организации совместного использования DAG-файлов при развертывании Apache AirFlow в Kubernetes. Чем хорош вариант с общими томами и почему от него лучше отказаться в пользу Git. Как организовать обмен DAG-файлами в Apache AirFlow на Kubernetes Развертывание Apache AirFlow в кластере...

Недавно мы писали, от каких факторов зависит выбор подходящего MLOps-инструмента. В продолжение этой темы сегодня специально для ML-инженеров разберем сходства и различия двух самых популярных MLOps-решений: что общего у MLflow и Kubeflow, чем они отличаются и в каких случаях выбирать тот или иной инструмент. Краткий обзор 2-х самых популярных MLOps-решений...

Специально для обучения дата-инженеров и администраторов кластера тонкостям работы с современными инструментальными средствами оркестрации конвейеров обработки данных, сегодня рассмотрим, почему в Apache AirFlow уходит много времени на парсинг большого количества DAG-файлов и как этого избежать. Потери времени при парсинге множества DAG-файлов в Apache AirFlow Apache AirFlow часто используется в проектах...
Недавно мы писали про проблемы приложений Apache Flink в кластере Kubernetes. Сегодня рассмотрим, каким образом можно развернуть и запустить задания этого фреймворка распределенной обработки данных на самой популярной DevOps-платформе контейнерной виртуализации. Обзор операторов от Lyft, Google Cloud Platform, нативного расширения и возможностей платформы Ververica. Зачем и как выполнить развертывание Apache...

Сегодня рассмотрим, с какими нетиповыми ошибками может столкнуться дата-инженер при работе с Apache Flink, а также как решить эти проблемы. Где и что править, когда сервер BLOB-объектов завис из-за слишком большого количества подключений, почему не хватает памяти при развертывании Flink-приложений в кластере Kubernetes и как ускорить инициализацию заданий. Особенности работы...

В этой статье для обучения дата-инженеров и архитекторов распределенных систем рассмотрим, что такое наблюдаемость, как ее измерить и при чем здесь стандарт OpenTelemetry. А в качестве примера разберем, как французский маркетплейс Cdiscount управляет почти 1000 микросервисов в кластере Kubernetes с Apache Kafka, Jaeger, Elasticsearch и OpenTelemetry. Наблюдаемость распределенной системы: стандарт...
Мы уже рассматривали важность мониторинга приложений Apache Flink и говорили про метрики отслеживания задержки обработки данных в потоковых заданиях. Сегодня заглянем под капот этого фреймворка и разберем, какие показатели работы JVM, а также RocksDB особенно важны для дата-инженера и разработчика распределенных приложений. Метрики JVM во Flink-приложениях Напомним, основным языком разработки...

16 июня 2022 года вышла новая версия Apache Spark – 3.3.0. Разбираем главные фичи этого минорного релиза, особенно важные для дата-инженера и разработчика распределенных приложений: от расширения поддержки ANSI SQL до профилирования UDF на Python. Главные изменения Apache Spark 3.3.0 Apache Spark 3.3.0 — это четвертый релиз линейки 3.x, в...
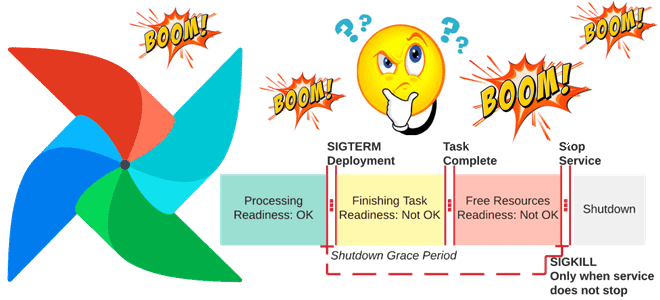
Каждый дата-инженер, который работает с Apache Airflow, сталкивался с сигналом SIGTERM, который отправляется задачам и приводит к сбою DAG. Сегодня рассмотрим, почему случается исключение airflow.exceptions.AirflowException, которое генерирует этот сигнал, и как его избежать. Тайм-аут выполнения DAG Одна из причин, по которой задача получает сигнал SIGTERM, связана с небольшим значением параметра...

В свежем релизе Apache Kafka 3.2.0, который вышел 17 мая 2022 года, о чем мы писали здесь, есть много интересных улучшений для повышения устойчивости потоковых приложений. Почему важна новая фича назначения резервных задач с учетом стоек и как разработчик с дата-инженером могут использовать в помощь администратору кластера: разбор rack awareness...

Мы уже писали о преимуществах развертывания Apache NiFi на Kubernetes, а также сложностях практической реализации этого процесса. Сегодня поговорим о контейнеризации реестра NiFi с использованием Helm-диаграмм, а также совмещения с Apache Ranger и Kerberos. 7 главных трудностей развертывания Apache NiFi на Kubernetes Apache NiFi активно используется дата-инженерами для организации потоковых...
Что не так с традиционными методами и инструментами разработки ПО для систем машинного обучения и как MLOps решает эти инженерные проблемы ML. Почему не стоит размещать файлы моделей Machine Learnig и датасеты в Git, а также зачем MLOps-инженеру решать вопросы архитектуры и управляться с Kubernetes. MLOps вместо Git-репозиториев Традиционные рабочие...
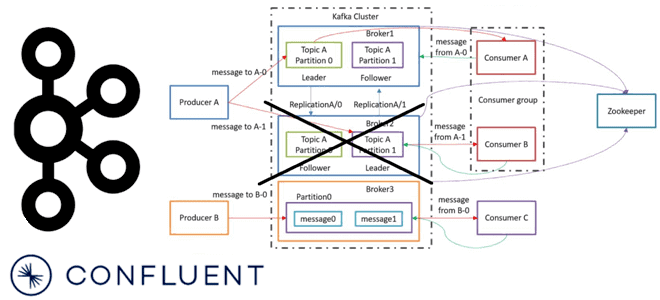
Сегодня рассмотрим важную для обучения администраторов кластера Apache Kafka тему про удаление брокеров. Что происходит, когда администратор удаляет брокер Kafka из кластера, какие сложности при этом могут возникнуть и как с ними справляется решение на базе платформы Confluent. Как вручную удалить брокер Kafka из кластера: краткий guide администратора На первый...
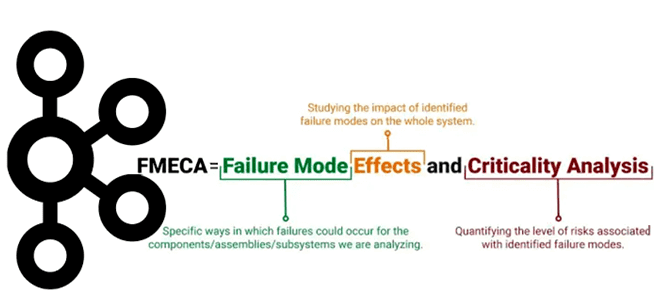
Хотя Apache Kafka является надежной платформой потоковой обработки событий, что особенно важно для распределенных приложений, отказы случаются и в ней. Сегодня разберем важную для обучения разработчиков и дата-инженеров тему про идентификацию и обработку отказов в Kafka-приложениях с помощью простого, но эффективного метода теории надежности. Что такое FMECA-анализ, как его проводить...

Сегодня рассмотрим несколько рекомендаций по построению масштабной и устойчивой экосистемы интеграции корпоративных данных на базе Apache AirFlow от компании Astronomer, которая активно способствует продвижению и коммерциализации этого популярного инструмента дата-инженерии. Как организовать эффективную маршрутизацию рабочих процессов с пакетным ETL-оркестратором: 3 лучших практики. Стандартизация сред разработки и промышленной эксплуатации с Kubernetes...
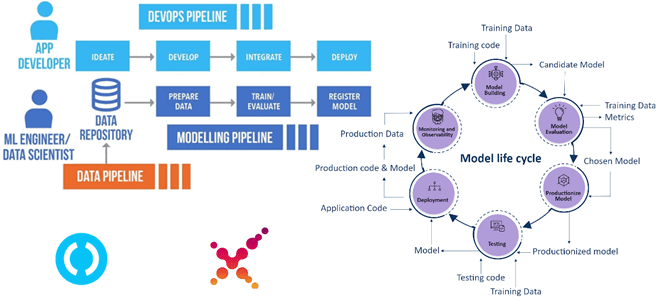
Чтобы сделать наши курсы для специалистов в области Data Science и ML-инженеров еще более полезными, сегодня рассмотрим, как организовать сквозной CI/CD-конвейер разработки и развертывания системы машинного обучения в соответствии с MLOps-концепцией на 4-х популярных Python-инструментах: MLflow, DVC, Airflow, ClearML. А в качестве примера практической реализации этой идеи разберем кейс банка...

Почему следует избегать PythonOperator в конвейере обработки пакетных данных на Apache Airflow и что использовать вместо этого оператора для описания задач DAG. Когда лаконичный CLI лучше наглядного GUI, где и как применять библиотеку Python Fire для оркестрации, а также планирования запуска batch-заданий. Зачем нам CLI или что не так с PythonOperator...

Запуск Apache Airflow с Kubernetes сегодня стал стандартом де-факто. Однако, при практическом развертывании Airflow с помощью исполнителя Kubernetes и оператора пода в кластере этой платформы оркестрации контейнерных приложений возникает множество препятствий и трудностей. Сегодня рассмотрим, как обойти их с помощью service-mesh проекта с открытым исходным кодом Istio, какие проблемы могут при...

11 марта 2022 года вышла новая версия Apache Airflow Helm Сhart. Рассмотрим главные новинки релиза 1.5.0 и их практическую ценность с точки зрения прикладной дата-инженерии. А также разберем ключевые понятия этого менеджера пакетов Kubernetes. Что такое Helm chart в Kubernetes и причем здесь Apache AirFlow Напомним, Helm – это менеджер пакетов...