
Мы уже писали про тестирование приложений Apache Flink, используя SQL-клиентов, Table API, тестовые наборы операторов и режим локального мини-кластера. Сегодня рассмотрим, как с помощью тестовых наборов тестировать UDF-функции, использующих состояние и таймеры. Модульное тестирование UDF-функций Flink-приложения с помощью тестовых наборов При работе с Apache Flink разработчики часто сталкиваются с проблемами при...
Обогащение потока данных информацией из внешнего API без остановки вычислений: 3 способа реализовать это средствами Apache Flink на примере сервиса геолокации. Зачем обогащать потоковые данные через внешний API и как это сделать для Flink-приложения? Иногда необходимо обогатить потоки данных, т.е. дополнить потоковые данные в реальном времени, т.е. на лету, не...
Мы уже писали о важности отслеживания системных метрик приложений Apache Flink и RocksDB, используемой этим фреймворком для хранения состояния stateful-заданий. Сегодня рассмотрим, как отследить потребление ресурсов ЦП средствами встроенной визуализации Flame Graphs. Что такое Flame Graph и зачем это нужно? Помимо мониторинга длительности выполнения задач и заданий, дата-инженерам и разработчикам...
Что не так с механизмом контрольных точек в Apache Flink, и как журнал изменений состояния справляется с ростом сквозной задержки в потоковой обработке данных средствами этого фреймворка. Проблемы контрольных точек в Apache Flink Одной из наиболее важных характеристик систем потоковой обработки данных является сквозная задержка, которая в Apache Flink зависит...

Как использовать DataStream API в Apache Flink: пишем потребителя из Kafka и запускаем скрипт в Google Colab. StreamExecutionEnvironment и методы коллекций потока данных в PyFlink. DataStream API в Apache Flink: PyFlink в Google Colab для работы с Kafka Apache Flink предоставляет множество возможностей разработчикам на Scala и Java, а также...

Как не запутаться в многообразии коннекторов к Kafka, доступных во Flink Table API, и выбрать наиболее подходящий для своего сценария применения. Разница между Append Mode и Upsert-режимом коннектора Flink SQL к Kafka. 2 режима работы коннектора Kafka в Apache Flink Apache Flink поставляется с универсальным соединителем Kafka, который поддерживает последнюю...

23 марта 2023 года вышел очередной релиз Apache Flink. Разбираемся с главными новинками выпуска 1.17.0: полезные фичи, исправленные ошибки и улучшения для дата-инженера и разработчика распределенных приложений. Новинки пакетной обработки В Apache Flink 1.17 внесено множество изменений в области пакетной и потоковой обработки. В частности, добавлен новый пакетный Streaming Warehouse...

Мы уже писали, как можно развернуть контейнерные приложения Apache Flink для обработки больших объемов данных в реальном времени. В продолжение этой темы сегодня сравним развертывание Flink-заданий в Kubernetes и в кластере AWS EMR. Flink-приложение в Kubernetes: преимущества и недостатки Apache Flink — это мощный фреймворк с открытым исходным кодом для...

Недавно мы писали про использование AirFlow для оркестрации dbt-конвейеров. Сегодня познакомимся с адаптером dbt-flink, который позволяет запускать SQL-конвейеры в проекте dbt на Apache Flink. Зачем нужен адаптер dbt к Apache Flink и как он работает В аналитике данных огромную роль играет эффективный, стабильный и надежный ETL-процесс, реализовать который можно с...
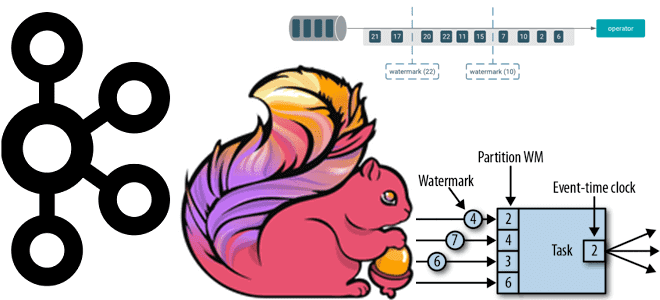
Почему вместо автоматической фиксации топиков Kafka приложению-потребителю Apache Flink лучше использовать контрольные точки, как создаются и обрабатываются водяные знаки и при чем тут оконные операторы потоковой обработки данных. Смещение в топиках Kafka для потоковых приложений Apache Flink Благодаря мощному API пакетной и потоковой обработки, Apache Flink часто используется для разработки...
Как протестировать работу приложения Apache Flink, используя SQL-клиентов, Table API, тестовые наборы операторов и режим локального мини-кластера. Разбираем особенности ручного и автоматизированного тестирования Flink SQL на уровне отдельных функций, модулей и их интеграционного взаимодействия. Модульное и интеграционное тестирование приложений Apache Flink SQL Тестирование является неотъемлемой частью любого процесса разработки ПО,...
Чем опасны дубли данных при их потоковой обработке и как реализовать дедупликацию в Apache Flink SQL. Смотрим на практическом примере для обучения дата-инженеров и разработчиков распределенных приложений. Потоковая дедупликация данных в Apache Flink SQL Apache Flink можно назвать уникальный фреймворком для разработки распределенных приложений в области Big Data, который унифицирует...

28 октября 2022 года вышел мажорный релиз Apache Flink. Что нового в выпуске 1.16.0, который сегодня имеет официальный статус стабильного: зачем нужен SQL Gateway, как улучшен Changelog State Backend, какие DDL-выражения добавлены и зачем внесена поддержка кэширования результата преобразования в PyFlink. Главные обновления Apache Flink 1.16 В версии 1.16 Flink...

Сегодня рассмотрим, как оптимизировать потребление памяти в приложениях Apache Flink, разобрав основные принципы работы и конфигурации настройки памяти этого вычислительного фреймворка. А также перечислим типовые ошибки, с которыми дата-инженер может столкнуться при разработке и эксплуатации Flink-приложений Компоненты памяти в Apache Flink Apache Flink обеспечивает эффективные рабочие нагрузки поверх JVM, строго...

Зачем корпорации Confluent, которая продвигает Apache Kafka, понадобился Flink-стартап, чего ожидать от очередного слияния поглощения крупным игроком более мелкого предприятия, и какую пользу это принесет экосистеме потоковой передачи событий. Что Immerok и зачем это Confluent Год только начался, а в мире Big Data уже появились интересные новости. 6 января в...

Мы уже рассказывали, что Apache Flink использует Calcite для оптимизации SQL-запросов. Продолжая разбирать эту тему, важную для обучения разработчиков Flink-приложений и дата-инженеров, сегодня рассмотрим, как отследить происхождение отношения на уровне поля, используя методы класса RelMetadataQuery в Calcite. Что такое Apache Calcite и при чем здесь Flink SQL Напомним, Apache Flink...

Как оптимизатор Calcite в Apache Flink переводит SQL-команды в задания потоковой и пакетной обработки и какие приемы могут ускорить их выполнение. Разбираемся, чем полезны интерфейсы пользовательских коннекторов источника и подсказки запросов. Flink SQL в пакетной и потоковой обработке данных Apache Flink позволяет разрабатывать распределенные приложения потоковой обработки больших данных, предоставляя...
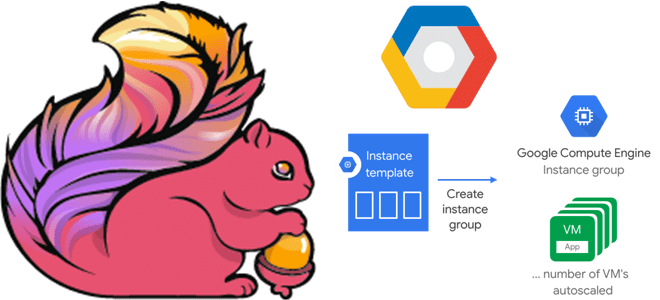
В этой статье для дата-инженеров и разработчиков Flink-приложений рассмотрим, как связаны диспетчеры задач и заданий, зачем настраивать автоматическое масштабирование кластера и как это сделать с помощью Google Auto Scaler в облачной инфраструктуре этого провайдера. Роль диспетчера заданий в Apache Flink и механизмы отказоустойчивости Apache Flink — отличный фреймворк создания приложений...

Чтобы добавить в наши курсы по аналитики больших данных еще больше практически примеров, сегодня рассмотрим, как современные технологий Big Data помогают в реальном времени выявлять телекоммуникационные мошенничества. Почему для антифрод-задач особенно подходит Apache Flink с его потоковом движком обработки данных и за счет чего этот фреймворк такой быстрый. Антифрод в...

Мы уже разбирали некоторые советы оптимизации Flink-приложений, связанные с неравномерным распределением данных по вычислительным узлам. Сегодня рассмотрим, как при этом пригодится паттерн MapReduce Combiner, который часто используется в экосистеме Apache Hadoop и вместо него лучше применить Bundle оператор, доступный с версии Flink 1.15. Проблема неравномерного распределения в Big Data вообще...