Чтобы добавить в наши курсы для дата-инженеров и специалистов по Machine Learning еще больше практических примеров, сегодня рассмотрим, как построить ETL-конвейер для преобразования речи в текст с использованием Apache Kafka, Airflow и Spark. А также познакомимся с популярными фреймворками и готовыми сервисами распознавания речи. ETL-конвейер распознавания речи: используемые технологии Предположим,...

Сегодня в рамках обучения дата-инженеров разберем, как организовать логическое ветвление рабочего процесса в Apache AirFlow с помощью операторов. Какие операторы позволяют организовать условную логику в DAG, чем BranchPythonOperator отличается от ShortCircuitOperator, как запустить задачу в зависимости от времени и/или дня недели, а также результата выполнения SQL-запроса. Условная логика в DAG:...

В этой статье для обучения дата-инженеров рассмотрим, почему в потоковых конвейерах обработки данных на базе Apache NiFi случаются ошибки, и какие популярные стратегии и инструменты помогут идентифицировать эти проблемы, а также решить их. Проблемы конвейеров обработки данных на Apache NiFi Конвейеры данных помогают консолидировать информацию из разных источников, чтобы получить...
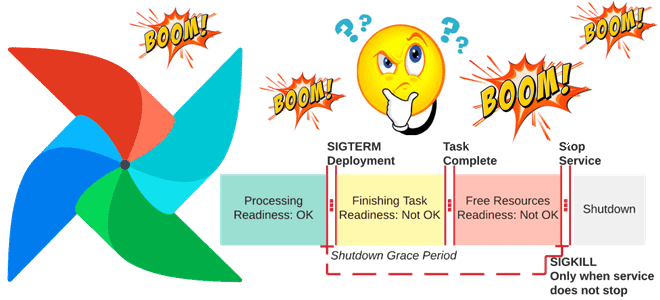
Каждый дата-инженер, который работает с Apache Airflow, сталкивался с сигналом SIGTERM, который отправляется задачам и приводит к сбою DAG. Сегодня рассмотрим, почему случается исключение airflow.exceptions.AirflowException, которое генерирует этот сигнал, и как его избежать. Тайм-аут выполнения DAG Одна из причин, по которой задача получает сигнал SIGTERM, связана с небольшим значением параметра...

Сегодня рассмотрим 2 основные категории технологий обработки данных: пакетную и потоковую. Что общего между batch и stream processing, где они применяются, какими технологиями поддерживаются, можно ли их использовать вместе и как это сделать: ликбез по архитектуре больших данных. Потоковая и пакетная обработка: краткий обзор с примерами Обработки данных в режиме...

15 июня 2022 года вышел новый выпуск Apache NiFi. Разбираем, что нового и полезного в релизе 1.16.3: исправленные ошибки, а также улучшения, важные для дата-инженера и администратора кластера Apache NiFi. 7 исправленных ошибок в релизе 1.16.3 Apache NiFi – один из самых популярных и востребованных инструментов современного дата-инженера. Эта платформа...
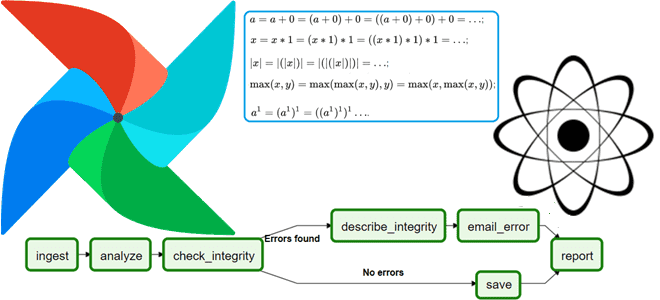
В этой статье для обучения дата-инженеров рассмотрим практическое применение 2-х важных принципов обработки данных: атомарность и идемпотентность задач в Apache Airflow. Читайте далее, как применить их к своим ETL-конвейерам, чтобы получить корректные и согласованные результаты. Все или ничего: атомарность задач Будучи популярным инструментом дата-инженерии, Apache Airflow снижает порог входа в...

В недавней статье про современные архитектуры данных мы упоминали Data Fabric и Data Mesh. Сегодня поговорим про эти стратегии Data Governance более подробно: разберем их главные достоинства и недостатки, основные сходства и принципиальные отличия, ключевые вызовы и технологии реализации, а также возможности совместного применения на практике. Что такое Data Fabric...

Мы уже писали о преимуществах развертывания Apache NiFi на Kubernetes, а также сложностях практической реализации этого процесса. Сегодня поговорим о контейнеризации реестра NiFi с использованием Helm-диаграмм, а также совмещения с Apache Ranger и Kerberos. 7 главных трудностей развертывания Apache NiFi на Kubernetes Apache NiFi активно используется дата-инженерами для организации потоковых...

Недавно мы писали про Apache AirFlow 2.3.0 от 30 апреля 2022 года. Сегодня более подробно разберем одну из главных новинок этого релиза – динамическое сопоставление задач. Что это такое, как работает и зачем нужно дата-инженеру. Что такое динамическое сопоставление задач в ETL-конвейере Напомним, динамическое сопоставление задач (Dynamic Task Mapping) считается...

Что такое архитектура данных, какие модели чаще всего используются в современных Big Data системах, почему традиционные BI-системы не справляются со всем разнообразием текущих бизнес-сценариев, чем Лямбда отличается от Каппа, а Data Fabric от Data Mesh и зачем внедрять MLOps-инструменты в аналитическую платформу. Немного истории: почему архитектуры данных до сих пор...

В этой статье для обучения дата-инженеров и администраторов кластера Apache HBase разберем, почему региональные сервера могут работать некорректно при высокой нагрузке и при чем здесь SCR-конфигурация файловой системы Hadoop. Что такое Short-Circuit Read в HDFS и почему оно может снижать скорость потокового чтения в приложениях Spark Streaming. Постановка задачи: проблема...
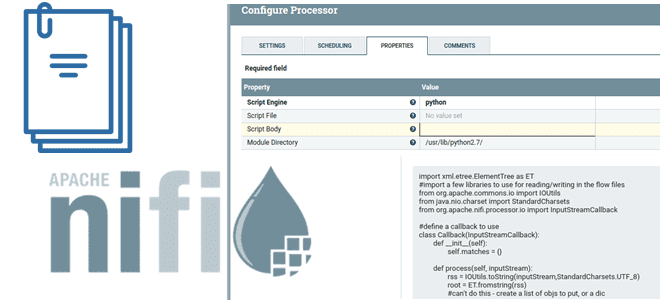
В этой статье для дата-инженеров разберемся, что такое NiFi Scripted Components и как они заполняют пробел между скриптами и пользовательскими компонентами: процессорами, контроллерами, сообщениями и средствами их чтения/записи. Рассмотрим примеры скиптовых процессоров и сервисов, а также определим реальные достоинства и недостатки этих компонентов. Почему просто скриптовых процессоров Apache NiFi недостаточно?...

Сегодня рассмотрим, кому и зачем нужно связывать Apache Hive с Kafka, каким образом реализуется эта интеграция, как получить доступ к данным из платформы потоковой передачи событий средствами SQL-on-Hadoop, при чем здесь режимы Kerberos и механизмы безопасности Ranger. Зачем нужна интеграция Apache Hive с Kafka Необходимость связать Apache Hive с Kafka...

30 апреля 2022 года вышел новый релиз Apache Airflow, который содержит более 700 коммитов с предыдущей версии 2.2.0 и включает 50 новых функций, 99 улучшений, 85 исправлений ошибок и несколько изменений в документации. Разбираемся, что особенно важно для дата-инженера в Apache Airflow 2.3.0. ТОП-7 главных фич Apache AirFlow 2.3.0: краткий...

В этой статье для дата-инженеров рассмотрим пример конвейера анализа потокового видео с Youtube-каналов на Kafka, Spark Streaming и Elasticsearch c Kibana, связанных через процессоры Apache NiFi. Постановка задачи: ETL-конвейер анализа потоковых данных с Youtube Потоковые данные непрерывно генерируются тысячами источников, которые отправляют записи одновременно и в небольших размерах (порядка килобайт)....
Мы уже рассматривали, как загрузить в Greenplum большие объемы данных. В продолжение этой важной для обучения дата-инженеров темы, сегодня разберем еще несколько инструментов, решающих задачу организации ETL-процессов с этой MPP-СУБД. ETL-инструменты PostgreSQL Хотя Greenplum может хранить и обрабатывать огромные наборы данных на уровне петабайт, эта СУБД не генерирует их самостоятельно,...
Интеграция Apache Airflow с инструментами CI/CD является одной из лучших практик современной дата-инженерии, о чем мы недавно писали. Читайте далее, зачем нужно управлять кодом DAG с помощью популярных систем управления версиями и как это сделать на примере GitLab CI/CD. Сложности управления DAG в разных средах AirFlow Apache Airflow считается наиболее...
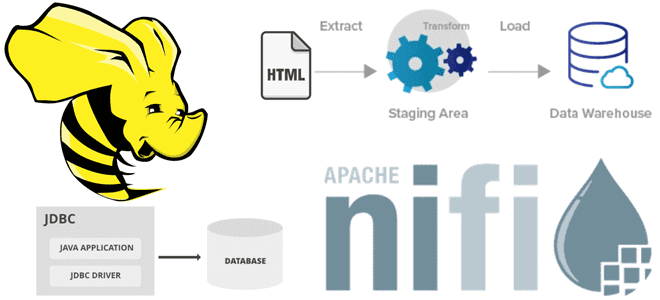
В этой статье для дата-инженеров рассмотрим пример интеграции Apache NiFi c Hive в рамках ETL-конвейера потокового веб-скрейпинга, который будет получать данные с веб-страницы практически без кода, обрабатывать их и загружать в таблицу NoSQL-СУБД в реальном времени. Постановка задачи: ETL-процесс веб-скрейпинга В реальной жизни задача считать данные с веб-сайта для последующей...
Сегодня рассмотрим, что такое процессор ExecuteScript в Apache NiFi, как с его помощью реализовать собственную бизнес-логику обработки потоков данных на мульти-парадигмальном языке программирования TypeScript и чем это будет лучше кода на JavaScript. Краткий ликбез для дата-инженеров. Процессор ExecuteScript в Apache NiFi Напомним, за обработку потоков данных в Apache NiFi отвечают...