Однажды мы уже разбирали, способна ли Apache Kafka заменить собой базы данных в мире Big Data. Сегодня рассмотрим обратную постановку этой задачи: можно ли реализовать постоянный обмен сообщениями в стиле Kafka с помощью СУБД. Читайте далее, что общего у Kafka с базой данных, чем они отличаются и почему попытки заменить...

В этой статье поговорим про практическое обучение Apache Kafka и рассмотрим, как сделать продюсеров еще более отказоустойчивыми, чтобы улучшить общую надежность всей Big Data системы. Читайте далее про наиболее важные конфигурации продюсеров Kafka и эффективные рекомендации по их настройке. 10 самых важных параметров продюсера Apache Kafka Из множества конфигурационных параметров...

Практическое обучение дата-инженеров – это не просто курсы по основам Big Data, а полезные рекомендации с реальными примерами. Поэтому сегодня рассмотрим, как работать с DAG в Apache AirFlow еще эффективнее с помощью параметров конфигурации, плагинов, меток, шаблонов, переменных и еще 10 различных инструментов. 15 лучших практики для DAG в Apache...

В рамках обучения дата-инженеров, сегодня рассмотрим проблему роста числа операций ввода-вывода в секунду (IOPS) при обработке большого количества данных в потоках Apache NiFi и способы ее решения. Читайте далее, как перемещение репозиториев NiFi с жесткого диска в оперативную память снижает IOPS, а также зачем при этом в Big Data систему...

Сегодня рассмотрим, что такое Data Build Tool, как этот ETL-инструмент связан с корпоративным хранилищем и озером данных, а также чем полезен дата-инженеру. В качестве практического примера разберем кейс подключения DBT к Apache Spark, чтобы преобразовать данные в таблице Spark SQL на Amazon Glue со схемой поверх набора файлов в AWS...

Поскольку наши курсы по Apache Spark предполагают практическое обучение с глубоким погружением в особенности разработки и настройки распределенных приложений, сегодня рассмотрим, как именно выполняются кластерные вычисления в рамках этого Big Data фреймворка. Читайте далее, из чего состоит архитектура Spark-приложения, как связаны SparkContext и SparkConf, а также зачем ограничивать размер драйвера...

Чтобы добавить в наши обновленные авторские курсы для дата-инженеров по Apache AirFlow еще больше интересного, сегодня продолжим разбирать полезные дополнения релиза 2.0 и поговорим, почему разделение фреймворка на пакеты делает его еще удобнее. Также рассмотрим практический пример создания общедоступного провайдера из локального Python-пакета с собственными операторами, хуками и прочими компонентами....
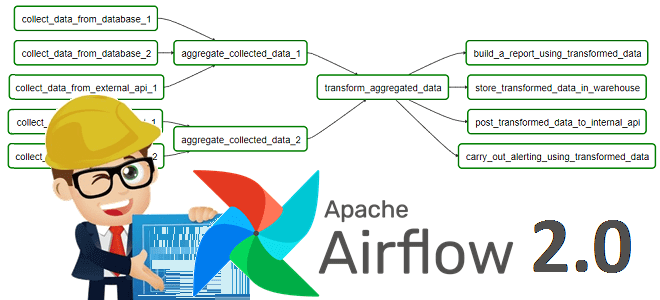
В поддержку наших полностью обновленных авторских курсов для инженеров данных по Apache AirFlow, сегодня рассмотрим новые способы определения DAG, которые были добавлены в релизе 2.0. Читайте далее, что под капотом TaskFlow API, как поместить задачи в TaskGroup, чем dag_policy отличается от task_policy и почему все это упрощает работу инженера Big...

Продолжая вчерашний разговор про потоковую аналитику больших данных на Apache Kafka и Pinot, сегодня рассмотрим особенности интеграции этих систем. Читайте далее, как входные данные Kafka разделяются, реплицируются и индексируются в Pinot, каким образом выполняется обработка данных через распределенные SQL-запросы. Также разберем, почему управление памятью серверов Pinot, потребляющих данные из Kafka,...

В этой статье разберем несколько популярных сценариев потоковой аналитики больших данных на Kafka, CDC-платформе Debezium и быстром OLAP-хранилище Apache Pinot. Читайте далее, почему все эти Big Data технологии отлично подходят для консолидации и интеграции данных из разных источников в реальном времени, включая аналитический аудит изменений, отслеживание событий в распределенном домене...
Вчера мы упоминали, как долгожданный KIP-500, реализованный в марте 2021 года, позволяет не только отказаться от Zookeeper в кластере Apache Kafka, но и снимает ограничение числа разделов, чтобы масштабировать брокеры практически до бесконечности. Однако, не все так просто: читайте далее, какие важные функции еще не поддерживаются в этом экспериментальном режиме...
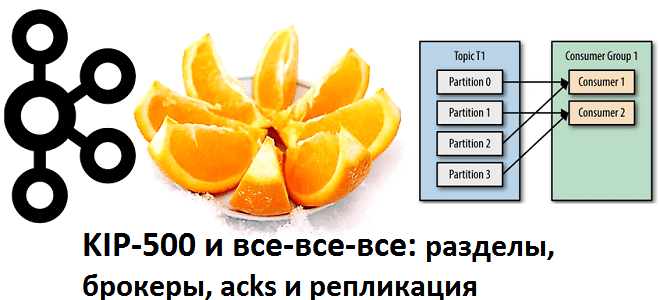
Сегодня рассмотрим важную практическую задачу из курсов Kafka для разработчиков и администраторов кластера – разделение топиков по брокерам. Читайте далее, как пропускная способность всей Big Data системы зависит от числа разделов, коэффициента репликации и ответного ack-параметра, а также при чем здесь KIP-500, позволяющий отказаться от Zookeeper. Что такое партиционирование в...

В поддержку курса Hadoop для инженеров данных сегодня разберем, в чем проблема безопасной отправки заданий и файлов в облачное хранилище Amazon S3 и как ее решить. Читайте далее, почему AWS S3 не дает гарантий согласованности как HDFS, из-за чего S3Guard не обеспечивает транзакционность и как настроить коммиттеры S3A для Spark...

Чтобы сделать курсы Hadoop и Spark для инженеров данных еще более интересными, сегодня мы рассмотрим кейс фудтех-компании iFood - лидера рынка доставки еды в странах Латинской Америки. Читайте далее, в чем проблема быстрых операций со множеством файлов в облачном хранилище Amazon S3 и как ее решить с помощью префиксов корзины...

Продолжая разговор про оптимизацию приложений Apache Spark в Kubernetes, сегодня разберем, как сократить расходы на облачный кластер с помощью спотовых узлов. А в качестве практического примера рассмотрим кейс компании Weather2020, дата-инженеры которой смогли всего за 3 недели развернуть террабайтные ETL-конвейеры в AWS с AirFlow и Spark на Kubernetes без глубокой...

Недавно мы рассказывали об особенностях запуска приложений Apache Spark в кластере Kubernetes с учетом новшеств релиза 3.1.1, где с этого варианта развертывания снят экспериментальный режим. В дополнение к ранее рассмотренным способам оптимизации Спарк-приложений, сегодня разберем, как инженеру Big Data ускорить их при запуске на платформе K8s. Как ускорить Spark-приложения на...

Сегодня рассмотрим особенности ухода с коммерческого дистрибутива Hadoop к версии сообщества на примере американской рекламной платформы Outbrain. Читайте далее, зачем дата-инженеры компании приняли такое решение, почему им не подошли альтернативы от MapR, Cloudera и Google Cloud Platform (DataProc), как проходила миграция на Apache Hadoop и что получилось в итоге. Предыстория:...
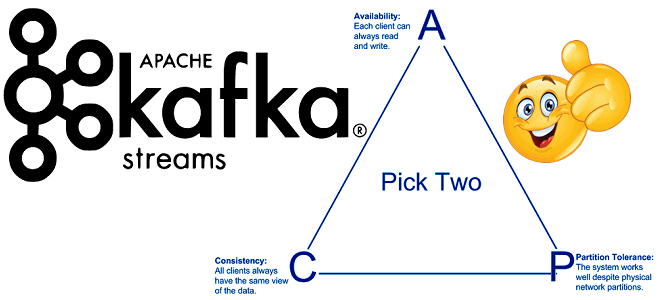
Продолжая включать интересные практические примеры в наши курсы Apache Kafka для разработчиков, сегодня поговорим о согласованности в распределенных системах с высокой доступностью. Читайте далее, что такое eventual consistency, почему это важно для микросервисной архитектуры, при чем здесь ограничения CAP-теоремы и как решить проблемы обеспечения конечной согласованности с Kafka Streams. ...
Чтобы сделать наши курсы по Apache Kafka еще более полезными, сегодня мы поговорим про базовые и расширенные возможности обеспечения информационной безопасности этой Big Data платформы. А в качестве практического примера разберем кейс международной финтех-компании BlackRock, которая разработала собственное security-решение для Kafka на базе протокола OAuth и серверов единого доступа KeyCloak....

В феврале 2021 года разработчики корпоративной версии Apache Kafka с коммерческой поддержкой, компания Confluent, выпустили премиум-коннектор к Oracle – одной из главных реляционных баз данных мира enterprise. Разбираемся, кому и зачем это нужно, а также как устроена такая интеграция SQL-СУБД и потоковой аналитики Big Data с применением CDC-подхода. Реляционный монолит...