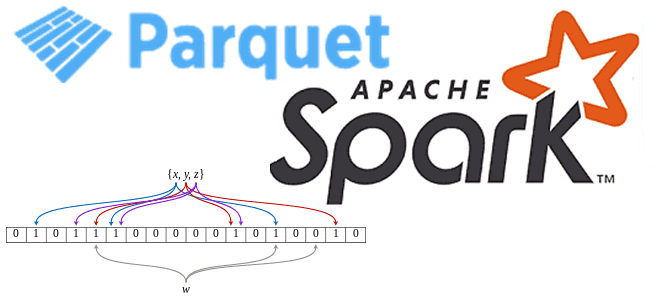
Сегодня рассмотрим, что такое фильтр Блума и как эта структура данных используется в Apache Spark для чтения Parquet-файлов. Про хеширование, UUID, достоинства и недостатки Bloom-фильтра для бинарного колоночного формата хранения больших данных в распределенных системах. Что такое фильтр Блума Фильтр Блума активно используется во многих информационных системах для быстрого поиска...
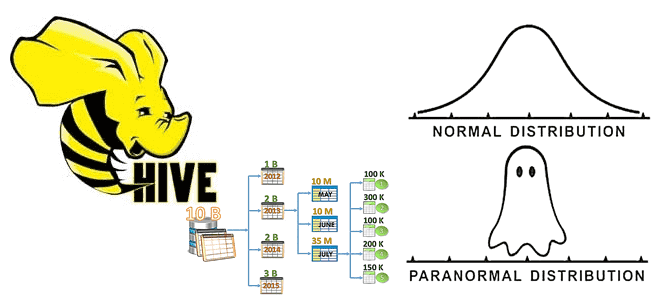
Мы уже писали, зачем нужна статистика таблиц при оптимизации SQL-запросов на примере Greenplum. Сегодня рассмотрим, как собрать статистические данные в таблицах Apache Hive, каким образом это поможет оптимизатору запросов и какие есть способы сбора статистики в этом популярном инструменте стека SQL-on-Hadoop. Еще раз о пользе статистики для оптимизации запросов в...
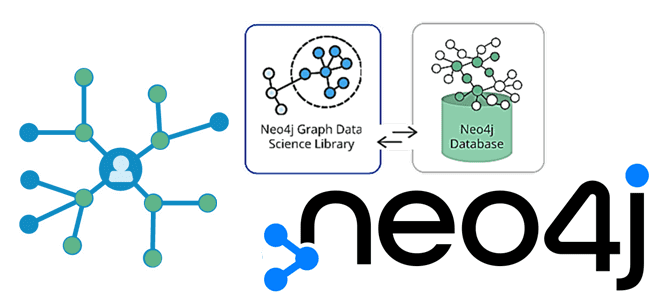
Продвигая наши курсы по прикладной Data Science и графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим специальную DS-библиотеку в Neo4j и ее возможности для фильтрации подграфов. А также разберем, чем версия сообщества отличается от Enterprise Edition, как запустить анализ слабо связанных компонент и алгоритм определения центральности на проекции графа в памяти. Graph...

Сегодня разберем пример европейской логистической компании Sixfold, которая смогла увеличить пропускную способность своей системы мониторинга транспортных отгрузок на базе Apache Kafka и Kubernetes. Также рассмотрим, как дата-инженеры Sixfold справились с проблемами изоляции при последовательной обработке сообщений и транзакционной записи в топики Kafka с базами данных отдельных микросервисов на подах Kubernetes....
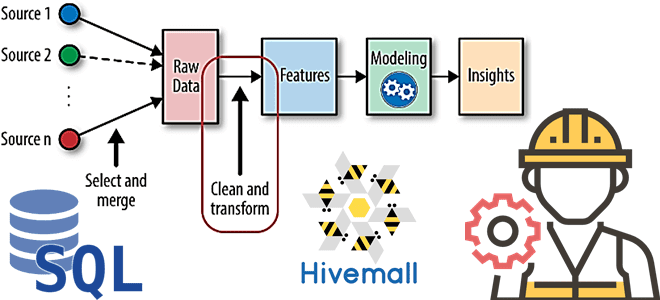
В рамках наших курсов для дата-инженеров и специалистов в области Data Science, сегодня рассмотрим, как реализовать один из важнейших этапов машинного обучения – Feature Engineering. Читайте далее, как генерировать признаки для ML-модели с помощью SQL, напрямую обращаясь к источникам данных и хранилищам фич, а также что такое Apache Hivemall и...

Развивая наши курсы для дата-инженеров по Apache AirFlow, сегодня рассмотрим, как автоматизировать развертывание сложных DAG’ов с помощью Docker и Kubernetes на примере управления конвейерами обработки данных. Лучшие практики и советы от инженеров данных DataOps-компании Databand. 4 вопроса дата-инженера к production-развертыванию конвейеров Apache Airflow Apache AirFlow считается одним из самых популярных...

В этой статье для разработчиков распределенных приложений разберем проблему с производительностью Apache Spark из-за неоптимальной стратегии переброса данных между оперативной и постоянной памятью. Что такое spill-эффект, почему он случается, как его идентифицировать и устранить. Что такое spill и почему он случается: под капотом Spark-приложений При том, что spill можно рассматривать...

7 ноября 2021 года вышел очередной релиз Apache NiFi с новыми фичами, улучшениями и исправлениями ошибок. Краткий обзор самых важных новинок: от постоянного хранилища для stateless-потоков и настроек облачных провайдеров до интеграции процессоров с пользователями Kerberos и улучшения работы с GitHub. Новинки и улучшения Apache NiFi 1.15.0 Свежий выпуск Apache...

Сегодня рассмотрим, как индийская ИТ-компания Razorpay с помощью Apache Flink и Kafka свела к минимуму время простоя своего главного продукта - платежного шлюза для интернет-магазинов. Как всего 2 задания Flink могут быстро обнаруживать простои более 50 когорт событий на уровне платежного шлюза и 200+ когорт разных интернет-магазинов. Работать нельзя остановиться:...

Недавно мы рассказывали про оптимизацию SQL-запросов в PXF – интеграционном фреймворке Greenplum. Сегодня рассмотрим, как этот способ обращения к внешним источникам данных можно применить к задачам машинного обучения на примере распознавания изображений. Platform Extension Framework как инструмент извлечения и преобразования изображений из облачных объектных хранилищ для обучений глубоких нейросетей с...
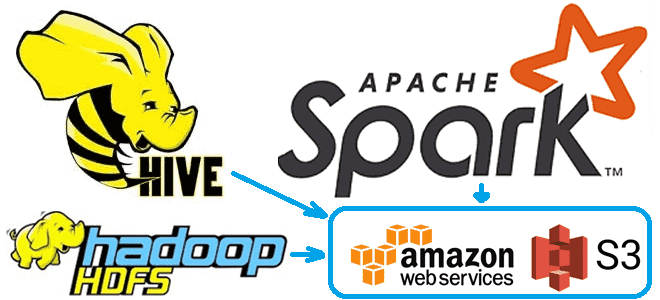
Чтобы сделать наши курсы по Apache Hadoop и компонентам этой экосистемы хранения и эффективной аналитики больших данных еще более полезными, сегодня рассмотрим, как получить данные из облачного объектного хранилища AWS S3 с помощью заданий Hive и Spark. А также заглянем внутрь конфигурационных xml-файлов Hadoop и Hive. Еще раз о разнице...

В прошлый раз мы говорили про особенности работы механизмов группировки и сортировки в распределенной среде Impala. Сегодня поговорим про метаданные таблиц в Impala и про то, как их извлекать и выводить на экран. Читайте далее про табличные метаданные в Impala, благодаря которым становится доступным и весьма удобным legacy-проектирование. Что из...
Мы уже писали о сложностях развертывания Apache Kafka на платформе управления контейнерами Kubernetes. Некоторые из этих проблем отлично решает KubeMQ – брокер очередей сообщений на Kubernetes. Зачем нужна очередная служба обмена данными, как она устроена и при чем здесь Kafka. Проблемы Kafka на Kubernetes и не только Сложная архитектура современных...
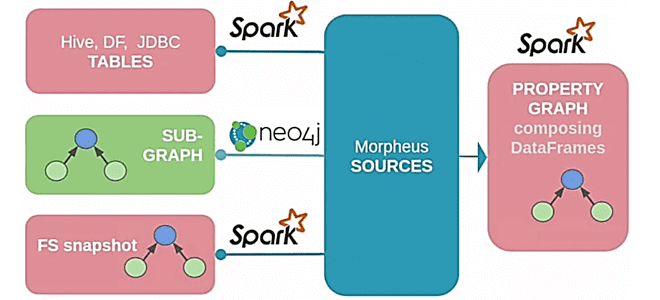
В рамках нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, как язык запросов Cypher должен был появиться в Apache Spark 3.0, зачем это нужно и почему до сих пор не реализовано. Краткая история проекта Morpheus, его связь с Neo4j, а также модулями Spark GraphX и GraphFrames. Что такое Morpheus...
Добавляя в наши курсы для дата-инженеров еще больше полезных примеров, сегодня рассмотрим, как Airbnb развивает Apache AirFlow и на практике используют эту платформу для создания, планирования и мониторинга конвейеров данных. Что такое Smart Sensor и как умные датчики экономят ресурсы на выполнение долгосрочных легковесных задач. Легкие, долгие и ресурсоемкие: проблемы...

Сегодня рассмотрим, как организовать полностью сохраняемый сервис Apache NiFi с помощью Docker, чтобы обеспечить безопасность конвейеров и потоков данных при изменении конфигураций и перезапуске служб. А также разберем, как дата-инженеру и администратору кластера NiFi запустить его на Kubernetes. Проблемы масштабирования и отказоустойчивости Apache NiFi Благодаря наличию веб-GUI, множеству готовых процессоров...
В статье для дата-инженеров и администраторов Apache Hadoop разберем, как реализовать инкрементное резервное копирование таблиц HBase из кластеров CDH/CDP в облачное объектное хранилище AWS S3. Практический пример от международной ИТ-компании Clairvoyant. 5 способов резервного копирования в Apache HBase Apache HBase - это популярная колоночная NoSQL-СУБД, которая работает поверх распределенной файловой...

Вчера мы рассматривали коннектор Neo4j к Apache Spark, который позволяет строить конвейеры аналитики больших данных с применением графовых алгоритмов. Продолжая эту тему, сегодня разберем варианты интеграции Neo4j с Apache Kafka с помощью шаблонных запросов Cypher в плагине и коннектора от Confluent, а также от каких конфигурационных параметров зависит пропускная способность...

Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня заглянем под капот коннектора Neo4j к Apache Spark. Сценарии использования, принципы работы, поддержка потоковой передачи Spark и другие новинки версии 4.1 для построения эффективных аналитических коннекторов с помощью алгоритмов на графах. Как работает коннектор Neo4j к Apache Spark: краткий обзор Осенью...
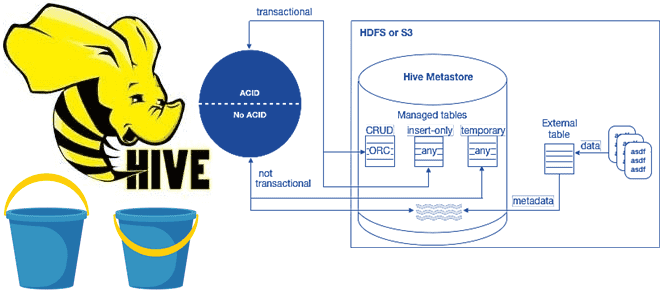
В рамках обучения аналитиков данных и дата-инженеров тонкостям работы с Apache Hive, сегодня разберем особенности ACID-транзакций в этом популярном инструменте класса SQL-on-Hadoop. Зачем и когда нужны ACID-транзакции в Apache Hive, какие параметры нужно настроить для их выполнения, при чем здесь блокировки, каковы ограничения и особенности уплотнения дельта-каталогов. Еще раз про...