
24 февраля в 19:30 (мск) Школа Больших Данных проводит открытую встречу по нашему новому курсу "Графовые алгоритмы. Бизнес-приложения". За пару часов вы узнаете, как повысить эффективность предприятия с помощью Data Science, дискретной математики и прикладных средств реализации графовых алгоритмов в современных базах данных и вычислительных движках. Автор курса и ведущий...
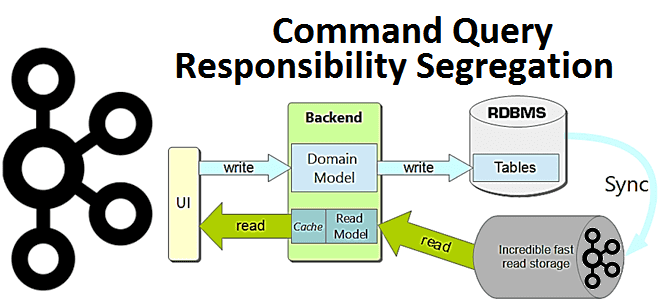
В этой статье для разработчиков распределенных приложений и ИТ-архитекторов разберем достоинства и недостатки паттерна проектирования CQRS, а также рассмотрим пример его реализации на Apache Kafka, Spring Cloud Stream и MongoDB. Что такое CQRS: основы проектирования архитектуры приложений Спрос на приложения, управляемые событиями, постоянно растет как для решения новых бизнес-задач, так...

Продвигая наш новый курс по графовым алгоритмам в бизнес-приложениях, сегодня рассмотрим применение теории графов к задаче анализа социальных связей на практическом примере возможностей библиотеки Graph Data Science СУБД Neo4j и ее языка запросов Cypher. А также разберем сопутствующую теорию: что такое центральность графа, почему эта мера не подходит для сетей...

Добавляя в наши курсы для дата-инженеров интересные кейсы, сегодня рассмотрим, как реализовать Лямбда-архитектуру для комплексной аналитики больших данных с помощью Apache Flink, Kafka и Cassandra на примере системы интернета вещей. Объединение пакетной и потоковой обработки данных средствами Flink API и библиотек этого фреймворка. Постановка задачи на примере IoT-системы Несмотря на...

В Apache HBase индексация таблиц возможна только по одному полю. Обойти это ограничение позволяет Apache Phoenix - инструмент обращения к NoSQL-хранилищу средствами SQL-запросов. В этой статье для дата-инженеров, архитекторов ИТ-решений и аналитиков данных рассмотрим типы вторичной индексации таблиц HBase в Phoenix и проблемы согласованности вторичных индексов, с которыми столкнулись специалисты...

Недавно мы писали про сложности обработки вложенных структур данных в JSON-файлах при работе с Apache Hive и Spark. В продолжении этой темы про парсинг, сегодня поговорим, как быстро преобразовать данные формата JSON в простой читаемый файл CSV или плоскую таблицу, чтобы анализировать их с помощью типовых методов DataFrame API или...

Мы уже рассказывали про связь Greenplum с другими источниками и приемниками данных с помощью PXF-фреймворка, а также отдельных коннекторов к некоторым системам. Сегодня рассмотрим, какие вообще есть коннекторы данных в этой MPP-СУБД и что такое Tanzu Greenplum Text. Коннекторы и фреймворки для интеграции GP и Arenadata DB с внешними системами...

В этой статье для дата-инженеров и администраторов кластеров разберем, как автоматически масштабировать поды Kubernetes с Apache AirFlow в зависимости от метрик рабочей нагрузки из внешней платформы Datadog с помощью демона StatsD, а также ресурса и контроллера HorizontalPodAutoscaler. Автоматическое горизонтальное масштабирование в Kubernetes Одна из сильных сторон Kubernetes заключается в его...

Недавно мы писали про развертывание Apache Kafka на Kubernetes с помощью open-source проекта Strimzi. Сегодня рассмотрим, как обеспечить безопасный доступ к данным на таком кластере, применив различные методы аутентификации и авторизации. Лучшие практики cybersecurity на практическом примере. Постановка задачи: пример приложения с безопасным доступом к данным Напомним, Strimzi – это...

Сегодня поговорим про совместное использование Apache NiFi с его легковесным агентом – MiNiFi. Преимущества для ETL-процессов в IoT-системах и не только, ограничения практического применения, а также пример контейнеризации и выполнения Docker-образа на Raspberry PI4 ARM64. Internet of Things и Apache NiFi на периферии Интернет вещей (Internet of Things, IoT) приводит...

В этой статье для дата-инженеров и администраторов SQL-on-Hadoop, рассмотрим, что такое Trino и как это работает с Apache Hive. А также при чем здесь Presto и зачем коннектор со своей средой выполнения использует Hive Metastore. Что такое Trino и при чем здесь Presto SQL Trino – это механизм запросов для...

Дополняя наши курсы по аналитике больших данных в бизнес-приложениях новыми полезными примерами, сегодня рассмотрим, как Apache Arrow помогает повысить производительность извлечения данных из Neo4j с помощью их колоночного представления и обработки в памяти, а не на диске. Чем neo4j-arrow лучше драйверов Java и Python, а также собственной Neo4j библиотеки Graph...

Чтобы сделать наши курсы для дата-инженеров еще более интересными, сегодня рассмотрим практический пример построения инфраструктуры для автоматической диагностики и исправления ошибок пакетной и потоковой обработки данных в Netflix. Комплексная система на базе Apache Spark, Kafka, Flink, Druid, сервисов AWS и других технологий Big Data. Предыстория: зачем Netflix разработал Pensive Обработка...

Для дата-инженеров и аналитиков про манипулирование данными в Apache Hadoop HDFS средствами SQL-запросов с помощью удобных инструментов. Apache Phoenix для обращения к таблицам NoSQL-хранилища HBase через SQL-запросы из графического интерфейса Hue. Как обратиться к таблицам HBase через SQL-запросы с Phoenix Apache HBase как хранилище данных над Hadoop HDFS предоставляет множество...

В рамках обучения разработчиков распределенных Spark-приложений, сегодня рассмотрим, как добавить функции из пользовательских JAR-файлов в кластер AWS EMR. Достоинства и недостатки действия начальной загрузки EMR с переопределением конфигурации Spark, а также расширенное управление зависимостями через spark-submit. Трудности обращения к пользовательским JAR в Amazon EMR с Apache Spark и Livy На...

Сегодня рассмотрим пару важных тем для администратора Greenplum: требования к программно-аппаратному окружению, а также особенности установки и настройки этой MPP-СУБД. Еще разберем, как Arenadata Cluster Manager облегчает и автоматизирует эти процессы в Arenadata DB. Программное окружение Greenplum: операционные системы и Java Greenplum 6 работает на следующих платформах операционных систем: Red...

В этой статье для разработчиков Data Flow, инженеров данных и администраторов Apache AirFlow рассмотрим, как организовать мониторинг этого batch-оркестратора через популярный корпоративный мессенджер Slack. Хотя по умолчанию Airflow имеет встроенную возможность отправлять оповещения по электронной почте, это не самый оперативный способ сообщить о критичной проблеме, к примеру, когда DAG с...

При том, что развертывание и эксплуатация Apache Kafka на Kubernetes требуют от администратора кластера много сил и времени, эта идея имеет массу достоинств, о чем мы писали здесь. Поэтому появляются новые инструменты, которые облегчают эти процессы, например, KubeMQ или Strimzi, который мы рассмотрим в этой статье. Что такое Strimzi и при...

В этой статье для дата-инженеров и разработчиков распределенных приложений разберем кейс американской ИТ-компании FiscalNote, которая использует Apache Flink в качестве движка потоковой обработки информации со сторонних веб-сайтов. Трудности сериализации сообщений из очередей RabbitMQ с разной скоростью поступления Big Data и способы их обхода. Постановка задачи: требования для Flink-приложения FiscalNote специализируется...
Обучая дата-аналитиков и разработчиков Neo4j, сегодня разберем, что такое Aspen, как этот язык разметки переводит текст в запрос Cypher с помощью одной командной строки и каким образом это пригодится для графовой аналитики больших данных в бизнес-приложениях. Что такое Aspen, а также как он связан с Neo4j и Cypher Будучи написанным на Ruby...