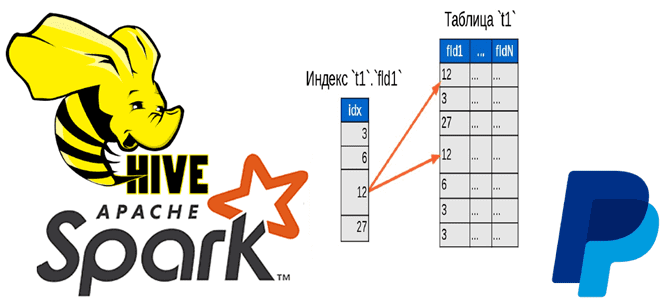
Чтобы добавить в наши курсы по Apache Hadoop и Spark еще больше интересных примеров, сегодня рассмотрим кейс компании PayPal, которой удалось ускорить работу Hive с помощью open-source библиотеки Dione. Зачем индексировать данные в HDFS и как это сделать быстро. Трудности бакетирования в Hive и Spark Вычислительный движок Apache Spark отлично...

Совсем недавно, в самом конце августа 2022 года вышел очередной минорный выпуск Greenplum. Специально для обучения дата-инженеров, ИТ-архитекторов и разработчиков распределенных OLAP-приложений мы подготовили краткий обзор самых важных обновлений и изменений версии 6.21.1. 15 исправлений на сервере Greenplum В отличие от июньского релиза, новинок в этом выпуске немного: добавлено новое...

Зачем переходить с cron на AirFlow и как это сделать наиболее эффективно: практические тонкости планирования и оркестрации пакетных процессов для дата-инженера с примерами и лайфхаками. Что такое cron и почему его недостаточно для инженерии данных Дата-инженеры часто работают с утилитой cron (Command Run ON), чтобы автоматически запускать на выполнение скрипты...

Хотя Apache HBase обладает массой достоинств, такими как строгая согласованность на уровне строк при больших объемах запросов, гибкая схема, доступ к данным с малой задержкой и интеграция с Hadoop, эта NoSQL-СУБД имеет ряд недостатков: чрезмерная сложность и дороговизна эксплуатации, отсутствие вторичных индексов и ACID-транзакций. Поэтому инженеры фотохостинга Pinterest приняли решение...

Мы уже писали, что технологии Big Data ориентированы на работу с большими данными, а не множеством маленьких. Сегодня рассмотрим подробнее, почему Apache Hadoop, Spark и основанные на HDFS NoSQL-СУБД Hive и HBase плохо работают с большим количеством маленьких файлов, а также как это исправить. Почему HDFS плохо работает со множеством...

Мы регулярно добавляем в наши курсы по Apache Flink и Spark для дата-инженеров полезные материалы и инструменты, которые помогают повысить эффективность разработки и эксплуатации приложений аналитики больших данных. Читайте далее, что такое SeaTunnel и как эта высокопроизводительная платформа интеграции распределенных данных упрощает их потоковую синхронизацию средствами SQL-заданий Apache Flink и...

1 августа 2022 года вышел очередной выпуск самого популярного потокового ETL-маршрутизатора. Что нового в Apache NiFi 1.17 для дата-инженера и администратора кластера: новые фичи, исправления ошибок и главные улучшения. Главные новинки Apache NiFi 1.17 Свежий выпуск Apache NiFi 1.17.0 включает сотни исправлений ошибок, улучшений и обновлений зависимостей для повышения стабильности...

Чтобы добавить в наши курсы для ИТ-архитекторов и дата-инженеров еще больше практических примеров, сегодня разберем ключевые требования к современному озеру данных и самые последние тренды в аналитике Big Data. Что такое DaaS, зачем это нужно и каковы риски. 7 преимуществ развертывания Data Lake в облаке При том, что Data Lake...

Специально для обучения дата-инженеров и администраторов кластера Apache Kafka, сегодня разберем, как обеспечить безопасность клиента этой распределенной платформы потоковой передачи событий по REST API с помощью возможностей открытого ПО. Что такое PEM-файлы и при чем здесь SSL-сертификаты, а также другие криптографические средства защиты данных: кейс инженеров Expedia Group. Инструменты обеспечения...

В этой статье для дата-инженеров и разработчиков распределенных приложений рассмотрим, что такое динамическое партиционирование таблиц в Apache Spark, зачем это нужно и как реализовать такие вставки разделов. Разбираем на практическом примере. Что такое динамическое партиционирование в Apache Spark Партиционирование – это разделение данных на основе значения столбца и их сохранение...

В отличие от каменных зданий, архитектуры данных постоянно меняются. Сегодня рассмотрим новую архитектурную модель под названием BigLake, выпущенную Google весной 2022 года. Что это такое, как устроено, чем похоже на Lakehouse, озеро данных и Data Mesh, а также чем от них отличается и какую пользу несет для конвейеров аналитики Big...

Недавно мы писали, от каких факторов зависит выбор подходящего MLOps-инструмента. В продолжение этой темы сегодня специально для ML-инженеров разберем сходства и различия двух самых популярных MLOps-решений: что общего у MLflow и Kubeflow, чем они отличаются и в каких случаях выбирать тот или иной инструмент. Краткий обзор 2-х самых популярных MLOps-решений...
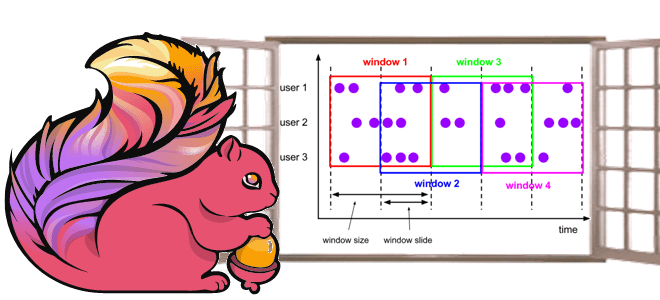
Чтобы сделать наши курсы по Apache Flink для дата-инженеров и разработчиков распределенных приложений еще более полезными, сегодня рассмотрим, как этот фреймворк потоковой аналитики больших данных реализует концепцию оконных функций. Жизненный цикл окна, ключевые понятия и оконные операции Apache Flink, управляемые данными и временем. Что такое окно в потоковой обработке данных...
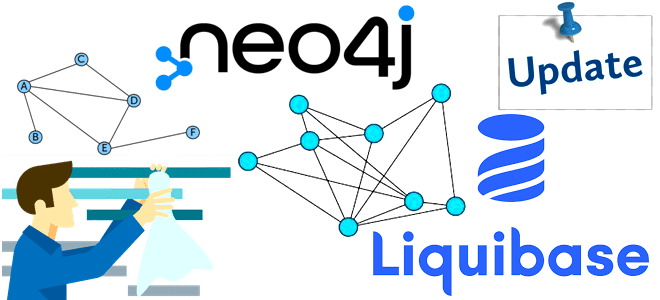
В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня разберем сложности рефакторинга графовых моделей в Neo4j и способы их обхода с помощью библиотеки APOC и плагина Liquibase. Что такое Liquibase и как Data Scientist и аналитик данных могут использовать его совместно с Neo4j. Гибкость модели данных и трудности...

Специально для обучения дата-инженеров и администраторов кластера тонкостям работы с современными инструментальными средствами оркестрации конвейеров обработки данных, сегодня рассмотрим, почему в Apache AirFlow уходит много времени на парсинг большого количества DAG-файлов и как этого избежать. Потери времени при парсинге множества DAG-файлов в Apache AirFlow Apache AirFlow часто используется в проектах...

Как найти компромисс между задержкой, пропускной способностью, долговечностью и доступностью в Apache Kafka: проблемы CAP-теоремы и поиски оптимальной стороны PACELC-ромба. Архитектурные ограничения распределенных систем и лучшие практики для настройки конфигурационных параметров для администратора кластера Apache Kafka и дата-инженера потоковых приложений аналитики больших данных. CAP-теорема и распределенные системы На производительность Apache...

Сегодня рассмотрим особенности использования оператора LIMIT в Spark SQL: как он выполняется и почему вместо него лучше использовать оператор TABLESAMPLE. Для этого в рамках обучения дата-инженеров, разработчиков распределенных приложений и аналитиков данных заглянем под капот оптимизатора Catalyst в Apache Spark и сравним физические планы выполнения SQL-запросов. Недостатки оператора LIMIT в...

В рамках обучения аналитиков данных, дата-инженеров и разработчиков распределенных приложений, сегодня поговорим про материализованные представления в Apache Hive. Что это такое, зачем нужно и как реализуется в самом популярном NoSQL-хранилище стека SQL-on-Hadoop. Что такое материализованное представление и зачем это надо в аналитике больших данных: краткий ликбез Аналитика данных включает в...

В этой статье для обучения дата-инженеров и администраторов кластера Apache NiFi разберем лучшие практики настройки этого популярного маршрутизатора потоковых данных. Какие настройки задать в операционной системе Linux и что исправить в конфигурациях самого Apache NiFi, чтобы ускорить обработку потоковых данных. Что настроить в Linux: 6 конфигураций Как и большинство серверных...

Специально для обучения администраторов кластера Apache Hadoop сегодня рассмотрим, как улучшить производительность распределенной файловой системы. Зачем перемещать файлы на последний узел в кластере, как оптимизировать управление дисками, а также чем полезно централизованное кэширование в HDFS. Оптимизация операций ввода-вывода на жестком диске Преимущества HDFS – распределенной файловой системы Apache Hadoop по...