
Сегодня рассмотрим, какие улучшения Apache Spark опубликованы в 2023 году и как подать свое предложение по улучшению самого популярного вычислительного движка в стеке Big Data. Что такое SPIP и как подать свое предложение по улучшению фреймворка В любом продукте помимо ошибок есть также предложения по улучшению. В Apache Spark они...

Чем отличается оркестрация ETL-процессов в Databricks и Apache AirFlow: принципы работы, достоинства и недостатки, а также что выбирать дата-инженеру для решения практических задач. Apache AirFlow vs Spark в Databricks: сходства и отличия Облачная платформа Databricks, основанная на Apache Spark, предлагает пользователям единую среду для создания, запуска и управления различными рабочими...

Как получать результаты обработки данных с помощью Apache Spark, адресуя ИИ бизнес-запросы на английском языке: знакомимся с English SDK от Databricks. Настоящий Low Code с PySpark-AI. English SDK for Apache Spark и PySpark-AI: как это работает Большие языковые модели (LLM, Large Language Model), основанные на генеративных нейросетях, применимы не только...
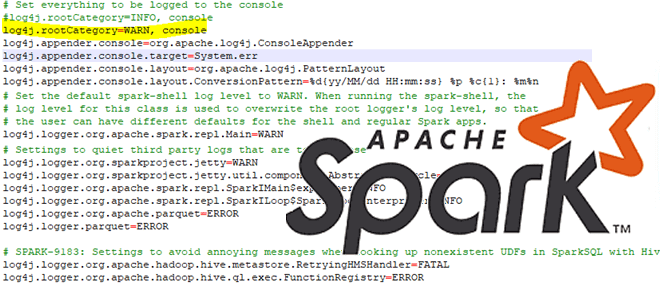
Сегодня рассмотрим особенности отладки PySpark-приложений: как Python-код исполняется в JVM, какие сложности возникают у разработчика при тестировании и исправлении ошибок в программе, написанной локально и запускаемой в кластере, а также как настроить вывод событий в лог-файл. Запуск и выполнение PySpark-кода Хотя Apache Spark и имеет Python API, позволяя писать код...
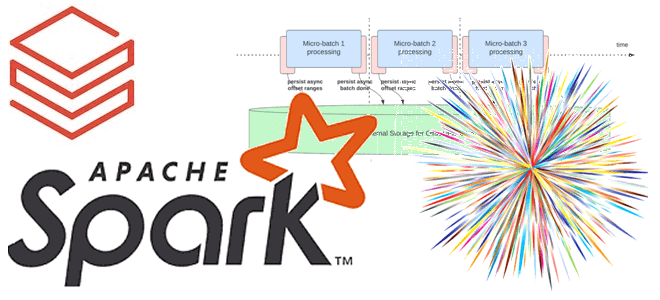
В прошлом году Databricks выпустили новый проект для ускорения потоковой передачи в Apache Spark. Сегодня рассмотрим, как именно Lightspeed сокращает задержку в операционных рабочих нагрузках Structured Streaming с помощью асинхронного управления смещением. Операционные рабочие нагрузки и что их тормозит в Apache Spark Structured Streaming Рабочие нагрузки потоковой передачи можно разделить...
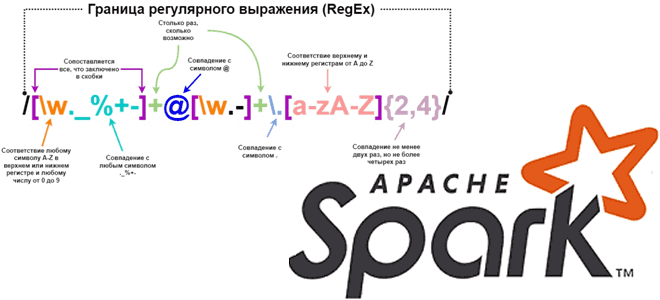
Каждый дата-инженер и аналитик данных активно использует регулярные выражения для поиска значений в тексте по заданному шаблону. Сегодня рассмотрим, как это сделать с функциями regexp_replace(), rlike() и regexp_extract в Apache Spark на примере небольшого PySpark-приложения. Как работает функция regexp_replace() Регулярным выражением называется последовательность символов, задающая шаблон соответствия в тексте. Например,...
Чем полезны новые фичи Apache Spark SQL, выпущенные в релизе 3.4. Разбираемся с псевдонимами столбцов и параметризованными SQL-запросами на простых примерах, запуская Spark-приложение в Google Colab. Псевдонимы столбцов Хотя с момента выхода Apache Spark 3.4 в апреле 2023 года, о чем мы писали здесь, прошло почти полгода, возможность ссылаться на...

От межсайтового скриптинга до внедрения вредоносного кода: какие проблемы информационной безопасности были обнаружены и исправлены в Apache Spark в 2023, 2022 и 2021 годах. Последние известные и исправленные проблемы информационной безопасности Apache Spark Недавно мы писали о механизмах обеспечения информационной безопасности в Apache Spark. Однако, несмотря на наличие этих средств,...

23 июня 2023 года опубликован очередной релиз Apache Spark 3.4.1, который считается отладочным выпуском для предыдущего, содержащий исправления стабильности. Помимо исправления ошибок, в нем также 16 новых фичей и более 20 улучшений, самые главные из которых мы рассмотрим далее. Исправления ошибок и новые фичи Apache Spark 3.4.1 Поскольку выпуск считается...
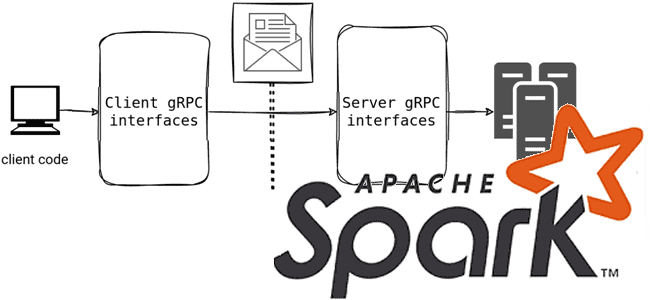
Мы уже писали, что в выпуске 3.4.0 от апреля 2023 года Spark Connect представил несвязанную архитектуру клиент-сервер, которая обеспечивает удаленное подключение к кластерам Spark из любого приложения, работающего в любом месте. Сегодня рассмотрим подробнее, как это работает и каковы плюсы для практического использования. Что такое Spark Connect и зачем это...
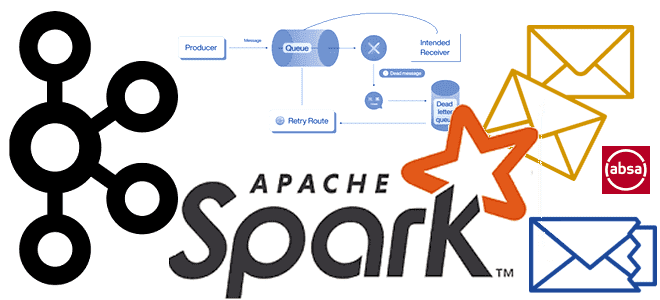
Недавно мы писали про лучшие практики работы с очередями недоставленных сообщений в Apache Kafka. Сегодня рассмотрим, как реализовать DLQ для AVRO-сообщений в приложении Spark Streaming c библиотекой ABRiS. DLQ для Apache Kafka в Spark-приложении Ситуация, когда приложение-продюсер вдруг изменяет формат или схему данных, публикуемых в Apache Kafka, на практике случается....
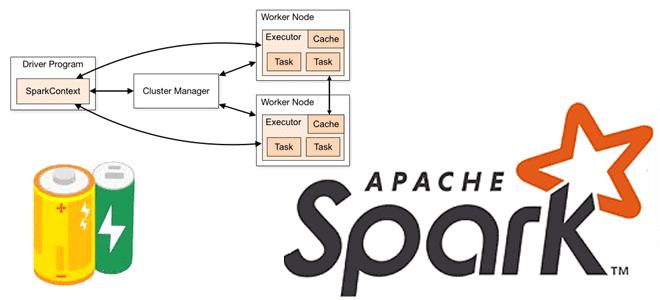
Что такое аккумуляторы в Apache Spark, чем они отличаются от широковещательных переменных и какова польза от этих концепций при разработке распределенных приложений и их использовании в кластере. Широковещательные переменные vs аккумуляторы В любой распределенной среде возникает задача сведения локальных результатов вместе. На практике, ее решение не всегда является простым. Например,...

Как Spark-приложение может прочитать данные из топиков Kafka: обзор вариантов и способов их использования. А также рассмотрим, почему Spark Structured Streaming заменила прямой поток и подход на основе приемника. Прямой поток и подход на основе приемника Будучи мощным фреймворком разработки распределенных приложений, Apache Spark позволяет считывать данные в потоковом режиме...

Сегодня посмотрим, как запустить Spark-приложение в Google Colab и увидеть сведения о его выполнении в веб-интерфейсе на удаленной машине, тунеллированной с помощью утилиты ngrok. Проброска туннеля в Google Colab с ngrok для Spark-приложения Хотя назвать Google Colab удобной средой для разработки приложений или исследования данных, нельзя, им часто пользуются аналитики...
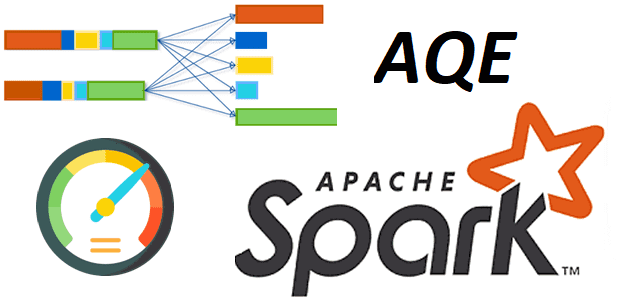
Недавно мы рассматривали практический пример разделения большого датафрейма Apache Spark на несколько разделов. Сегодня поговорим о том, как их объединить с помощью механизм AQE и динамической настройки конфигурации spark.sql.shuffle.partitions. Разделы и оптимизация распределенных вычислений в Spark-приложениях Распределение данных по разделам сильно влияет на скорость работы Spark-приложений. Распределенное приложение выполняется наиболее...

В этой статье для дата-инженеров и разработчиков распределенных приложений рассмотрим, какие механизмы обеспечения информационной безопасности поддерживает Apache Spark и как организовать безопасное взаимодействие Spark-приложения с хранилищами данных в экосистеме Hadoop. Безопасная работа Spark-приложений с сервисами Hadoop Многие технологии Big Data изначально оптимизированы для хранения и аналитики больших объемов данных с...
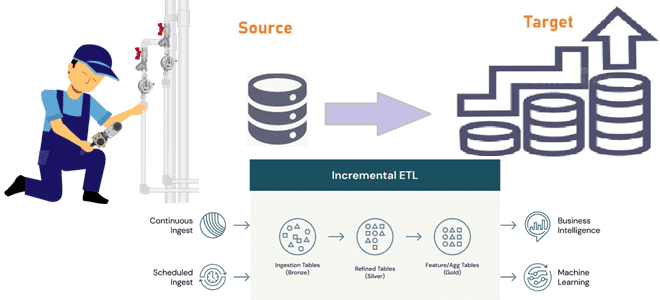
Инкрементные конвейеры загрузки больших объемов данных в корпоративное хранилище или озеро как самый экономичный способ масштабирования архитектуры данных. Разбираемся, как дата-инженеру эффективно организовать такие ETL-конвейеры. 2 способа организации конвейеров инкрементной загрузки данных Инкрементный ETL (Extract, Transform and Load) для классического DWH стал обычным явлением с источниками CDC (сбор данных об...
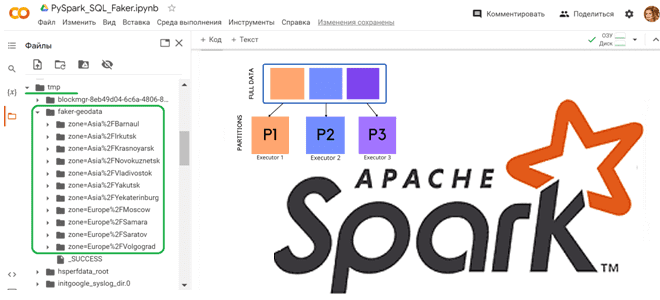
Как сгенерировать набор тестовых данных с Python-библиотекой Faker и разделить данные по разделам, используя функцию partitionBy() в PySpark. Работаем с Apache Spark в Google Colab. Как работает partitionBy() в Apache Spark Чтобы записать на диск один большой датафрейм, разделив его на несколько более мелких файлов, в Python API фреймворка Apache...

12 апреля 2023 года вышел очередной релиз Apache Spark. Разбираемся с самыми главными новинками этого выпуска, которые порадуют аналитиков, разработчиков, инженеров данных и специалистов по Data Science. Расширенная поддержка Python, улучшения Spark SQL и Structured Streaming. Обновления Spark SQL и новинки для пользователей Python Apache Spark 3.4.0 — это пятый...
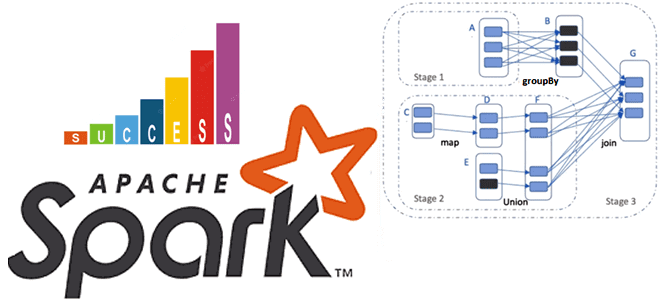
Почему на самом деле нельзя избежать shuffle-операций в Spark SQL, в чем разница перетасовки RDD и датафреймов, а также как сократить негативное влияние перемешивания данных по узлам кластера, настроив конфигурации распределенного приложения. Что такое shuffle-операции в Apache Spark SQL и зачем они нужны Распределенный характер вычислительного движка Apache Spark позволяет...