
Сегодня познакомимся с расширением PostGIS, которое позволяет PostgreSQL и Greenplum обрабатывать пространственные данные в геолокационных и логистических задачах. Как оно устроено и каковы ограничения его практического использования в MPP-СУБД. Что такое PostGIS и как это работает Как и PostgreSQL, Greenplum поддерживает геометрические типы данных, с помощью которых можно строить статичные...
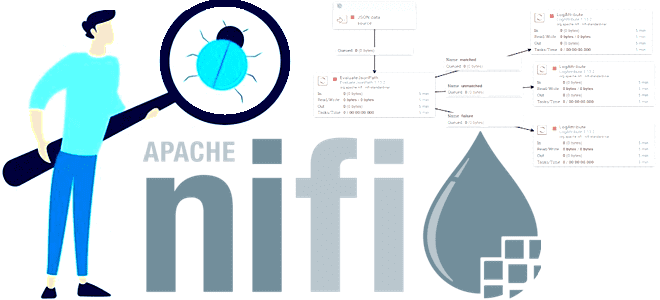
В этой статье для обучения дата-инженеров поговорим про тестирование потоковых конвейеров обработки данных в Apache NiFi. Утилиты, классы и сервисы для проверки правильной работы процессоров, контроллеров и потоков. Модульное тестирование процессоров Apache NiFi Обычно тестирование компонентов крупной инфраструктуры не самая простая задача. В Apache NiFi проверка корректности обработки потоков данных...

Недавно мы писали про использование AirFlow для оркестрации dbt-конвейеров. Сегодня познакомимся с адаптером dbt-flink, который позволяет запускать SQL-конвейеры в проекте dbt на Apache Flink. Зачем нужен адаптер dbt к Apache Flink и как он работает В аналитике данных огромную роль играет эффективный, стабильный и надежный ETL-процесс, реализовать который можно с...

Зачем биотехнологической платформе Polly от Elucidata понадобился API SQL-запросов в облачном сервисе Elasticsearch и как дата-инженеры реализовали его, развернув Delta Lake с AWS Atnena и S3. Что не так с SQL-запросами в облачном Elasticsearch на AWS Ежедневно биотехнологическая платформа Polly от Elucidata обрабатывает гигабайты биомолекулярных данных для биологов по всему...

Метод ближайших соседей активно используется в машинном обучении для решения задач классификации в различных бизнес-приложениях. Познакомимся поближе с этим алгоритмом Machine Learning, а также разберем, почему NoSQL-хранилище Apache HBase отлично подходит для работы с ним. Что такое метод ближайших соседей: ликбез по Machine Learning В проектах Machine Learning и приложениях...

Чтобы сделать наши курсы для дата-инженеров и разработчиков распределенных приложений еще более полезными, сегодня мы расскажем про новый бесплатный сервис от маркетплейса Joom для поиска проблем с производительностью Spark-заданий. Разбираемся, как он работает и чем полезен дата-инженеру. 4 главных проблемы Spark-приложений, их последствия и трудности обнаружения Если количество Spark-приложений невелико,...
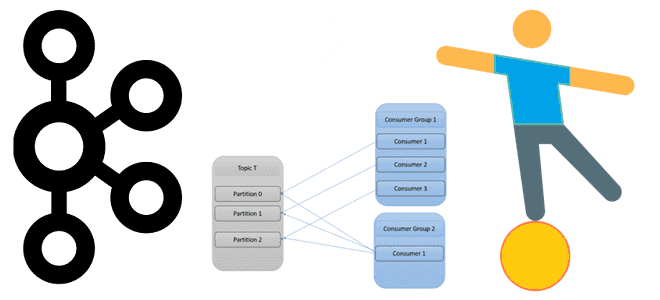
Для параллельной обработки сообщений из своих топиков Kafka использует механизм группы приложений-потребителей, о чем мы писали здесь. Читайте далее, что происходит при изменении состава группы потребителей, чем опасна частая перебалансировка и как ее избежать. Что такое перебалансировка потребителей и почему она случается? Выполняя роль интеграционного звена между приложениями-продюсерами и приложениями-потребителями...

Что такое dbt, чем полезен этот инструмент для анализа и инженерии данных, зачем переносить в него бизнес-логику обработки данных и представлять эти задачи в DAG-конвейере Apache AirFlow. Python и SQL для анализа данных и дата-инженерии: versus или вместе? Распил крупных монолитных систем на множество автономных взаимодействующих друг с другом приложений...

Как MLOps-инженеры платформы онлайн-курсов Udemy ускорили цикл разработки и внедрения проектов машинного обучения, используя возможности Amazon SageMaker для создания и отладки Spark-приложений в удаленном облачном кластере. MLOps на AWS Чтобы воспользоваться преимуществами бесшовной интеграции процессов разработки и развертывания машинного обучения согласно концепции MLOps, совсем не обязательно выстраивать собственную платформу из...

Сегодня в рамках продвижения нашего нового курса по графовым алгоритмам в бизнес-приложениях, решим классическую задачу логистики в графовой базе данных Neo4j без использования методов ее специальной библиотеки Graph Data Science, а средствами Cypher-запросов. Постановка задачи: критерии оценки для поиска кратчайшего пути Поиск кратчайшего пути – это классическая задача на графах,...
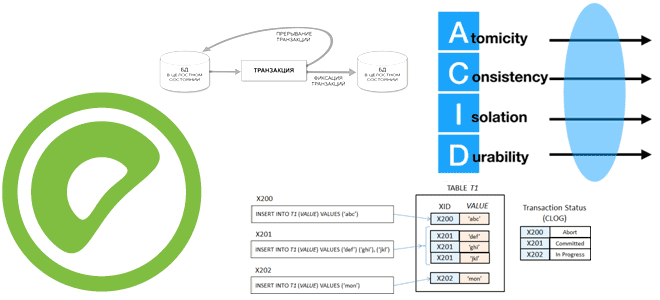
Недавно мы писали про трудности реализации ACID-требований к транзакциям в распределенных базах данных и способах их решения. Сегодня рассмотрим, как это работает в Greenplum с Arenadata DB: уровни изоляции, идентификаторы транзакций, моментальные снимки и MVCC-модель управления параллелизмом. Как GP и Arenadata DB реализуют распределенные транзакции Будучи основанной на PostgreSQL, Greenplum...

В этой статье для обучения дата-инженеров и разработчиков ETL-конвейеров на Apache NiFi рассмотрим, как преобразовать JSON-документы с помощью реализации JOLT-библиотеки в процессорах JOLTTransformJSON и JOLTTransformRecord. Что такое JOLT и как это работает Человекочитаемый формат JSON активно используется для представления пакетных и потоковых данных. Он легковеснее XML и прост для понимания,...
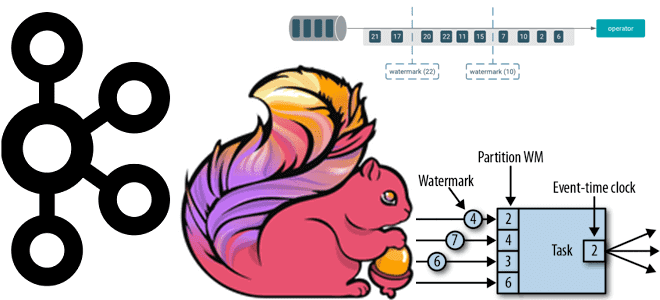
Почему вместо автоматической фиксации топиков Kafka приложению-потребителю Apache Flink лучше использовать контрольные точки, как создаются и обрабатываются водяные знаки и при чем тут оконные операторы потоковой обработки данных. Смещение в топиках Kafka для потоковых приложений Apache Flink Благодаря мощному API пакетной и потоковой обработки, Apache Flink часто используется для разработки...
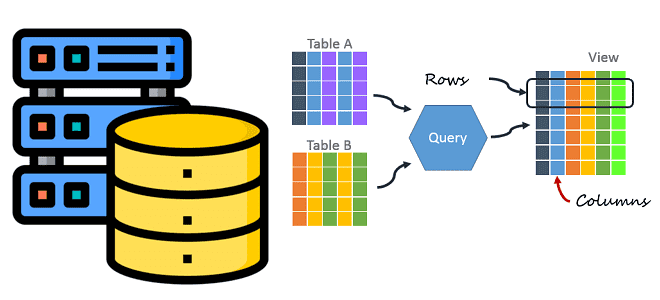
Как данные хранятся на диске при разной ориентации хранилища в СУБД: чем отличаются колоночные базы от строковых с точки зрения практического использования в дата-инженерии. Сравнительная таблица с примерами и выводами. Как данные хранятся на диске и при чем здесь ориентация СУБД Способы хранения данных в СУБД можно разделить на 2...

Что общего у FastAPI с BentoML, чем они отличаются и почему только один из них является полноценным MLOps-инструментом. Смотрим на примере операций разработки и развертывания API сервисов машинного обучения. Что общего у FastAPI с BentoML и при чем здесь MLOps С точки зрения промышленной эксплуатации, в проектах машинного обучения следует...
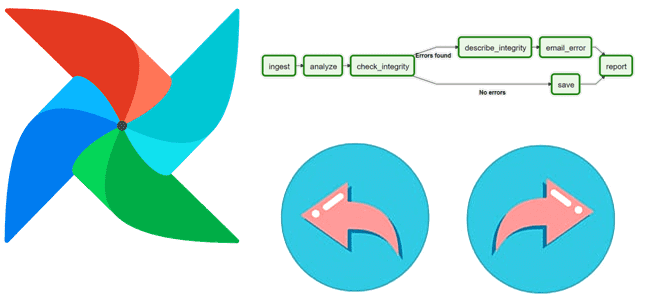
Что такое backfill в Apache AirFlow и зачем дата-инженеру запускать эту команду CLI-интерфейса при управлении DAG. Разбираемся с параметрами, возможностями и исключениями. Что такое backfill в Apache AirFlow и чем это полезно при управлении DAG Иногда при управлении конвейерами обработки данных в Apache AirFlow дата-инженеру необходимо вернуться в прошлое, чтобы...

Как использовать преимущества графических процессоров для Spark-приложений аналитики больших данных и машинного обучения с помощью библиотек RAPIDS. Знакомимся с ускорителем Spark RAPIDS и его возможностями сделать популярный вычислительный движок еще быстрее. Что такое RAPIDS Accelerator для Apache Spark и как он работает Системы Machine Learning, особенно проекты глубокого обучения, уже...
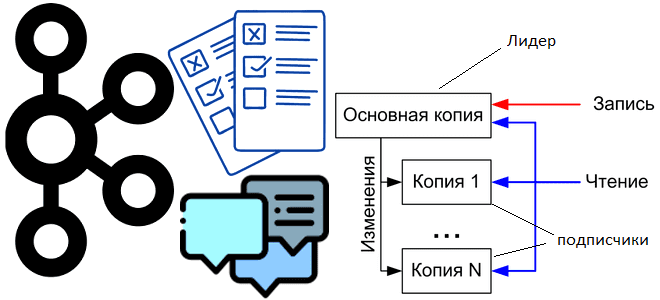
Сегодня рассмотрим, как внутренние механизмы Apache Kafka обеспечивают отказоустойчивость это потоковой платформы передачи событий, а также разберем, почему до сих пор приходится выбирать между доступностью и надежностью. Выборы нового лидера при сбое прежнего и ожидание подтверждений об успешной репликации. Поиск компромисса между надежностью и доступностью в Apache Kafka Для обеспечения...

9 февраля 2023 года опубликован очередной выпуск Apache NiFi. Разбираемся, что нового в релизе 1.20, какие появились процессоры для потокового приема и обработки данных, как устранена уязвимость CVE-2023-22832 и зачем нужны очередные изменения в функциях внутренних языков NiFi. Исправленные ошибки в Apache NiFi 1.20 В свежем выпуске Apache NiFi 1.20...

Что такое Delta Sharing, зачем нужен и как устроен этот открытый стандарт, а также как его использовать для централизованного управления доступом к данным в архитектуре Data Mesh. Что такое Delta Sharing и при чем здесь Data Lake Чтобы упростить обмен большими данными между разными компаниями в режиме реального времени и...