В Apache Spark есть 3 структуры данных, каждая из которых имеет собственный API со своими достоинствами и недостатками. Сегодня разберем плюсы и минусы Dataset API, а также рассмотрим особенности JOIN-операций в нем. Почему Dataset API в Apache Spark работает только со Scala и Java Напомним, структура данных Dataset впервые появилась...
Какие проблемы характерны для распределенных очередей сообщений, почему они случаются и как с ними справиться. Разбираемся со сбоями, ошибками и перегрузками на примере Apache Kafka и RabbitMQ. Проблемы с распределенными очередями и главные причины их появления Хотя Apache Kafka — это целая экосистема со множеством компонентов для потоковой передачи событий,...
Как написать пользовательский оператор Apache AirFlow и использовать его в DAG. А также чем хороши функции обратного вызова вместо XCom, и когда их не следует применять. Создаем свой оператор AirFlow и используем его в DAG Однажды мы уже разбирали, как создать свой оператор Apache AirFlow на примере сенсора – оператора...
Сегодня посмотрим на MLOps с точки зрения организационного и технического управления, решив вопрос о подходе к разработке ML-системы, а также рассмотрим метрики ее оценки перед развертыванием в production. Управленческий MLOps: 2 подхода к разработке системы Machine Learning Модели машинного обучения могут показывать высокую точность работы своих алгоритмов даже на производственных...
Недавно мы писали про резидентную графовую СУБД Memgraph, которая хранит данные в оперативной памяти. Сегодня рассмотрим, как выгрузить граф знаний из Memgraph на диск с помощью библиотеки GQLAlchemy, а также поговорим про персистентность другого популярного NoSQL-хранилища Redis, которое также является резидентным, но относится к семейству key-value. Как сохранить данные из...
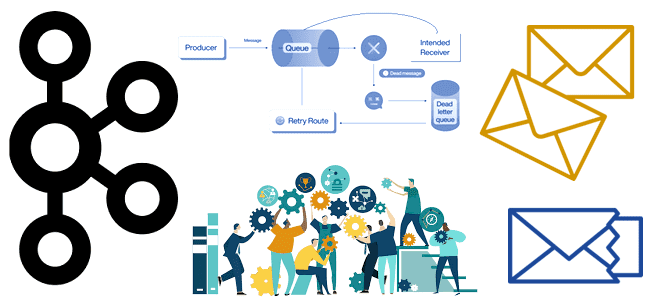
Недавно мы писали про очереди недоставленных сообщений в Apache Kafka и RabbitMQ. Сегодня поговорим про стратегии обработки ошибок, связанные с DLQ-очередями в Kafka, а также рассмотрим, какие сообщения НЕ надо помещать в Dead Letter Queue. 4 стратегии работы с DLQ-топиками в Apache Kafka Напомним, в Apache Kafka в очереди недоставленных...
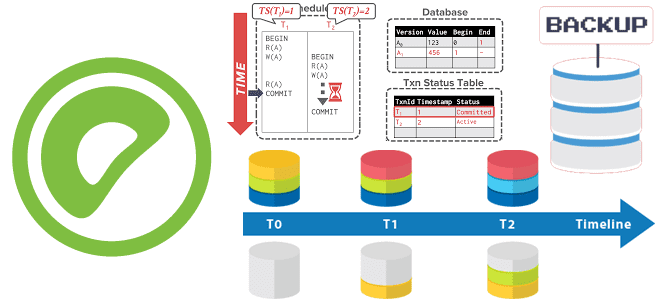
Как Greenplum расширяет MVCC-модель PostgreSQL для управления доступом к данным в многопользовательской среде, обеспечивая согласованность и изоляцию транзакций для нескольких сегментов в большом кластере. Преимущества моментальных снимков перед блокировками и их польза для резервного копирования. MVCC и транзакции в Greenplum с PostgreSQL Будучи основанной на PostgreSQL, о чем мы писали здесь,...

Чтобы сделать наши курсы по Apache NiFi Для дата-инженеров еще более полезными, сегодня поговорим про настройку процессоров. Читайте далее, как распараллелить задачи и потоки, задержать FlowFile, задать обратное давление и настроить другие полезные конфигурации. Как настроить конфигурации процессора Apache NiFi Будучи мощным инструментом дата-инженерии, Apache NiFi содержит множество обработчиков –...

23 марта 2023 года вышел очередной релиз Apache Flink. Разбираемся с главными новинками выпуска 1.17.0: полезные фичи, исправленные ошибки и улучшения для дата-инженера и разработчика распределенных приложений. Новинки пакетной обработки В Apache Flink 1.17 внесено множество изменений в области пакетной и потоковой обработки. В частности, добавлен новый пакетный Streaming Warehouse...
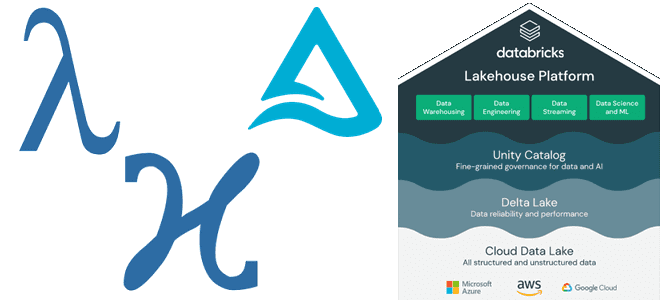
Как Lakehouse объединяет пакетную и потоковую обработку, какие проблемы возникают при реализации этой гибридной архитектуры данных и каким образом они решаются с помощью Delta-подхода и Apache Spark Structured Streaming. Краткая история появления дельта-архитектуры от лямбда- и каппа-моделей Мир больших данных постоянно развивается: появляются новые технологии и архитектурные шаблоны. В частности,...

Что общего у Apache HBase с Google Bigtable, чем они отличаются и какую NoSQL-СУБД выбирать для практического использования. Чем похожи NoSQL-хранилища для больших данных Apache HBase часто называют Google BigTable для Hadoop, поскольку она обеспечивает аналогичные возможности и использует многие концепции этой облачной NoSQL-СУБД. В частности, именно Bigtable был выпущен...
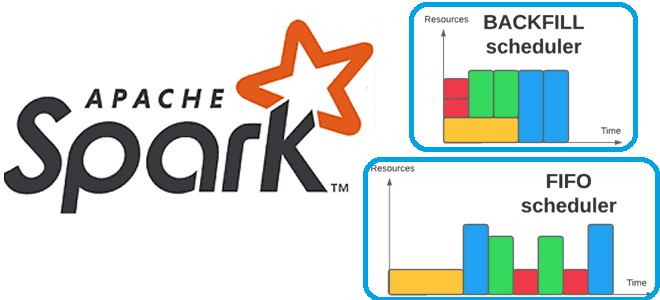
Что такое backfill-операции в конвейерах заданий Apache Spark, чем они отличаются от исторического заполнения датасетов, зачем их автоматизировать и как это сделать. Что такое backfilling для заданий Apache Spark Мы уже писали про понятие backfill на примере модификации DAG при добавлении новых заданий в конвейер Apache AirFlow. Эта функция полезна,...
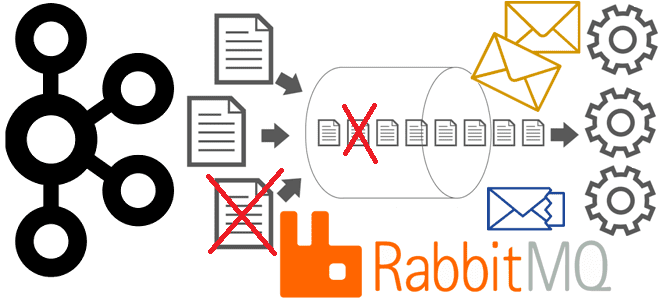
Сегодня рассмотрим, зачем в системах асинхронного обмена данными нужны очереди недоставленных сообщений, как их организовать и обработать. Разбираемся с Dead Letter Queue на примере Apache Kafka и RabbitMQ. Обработка недоставленных сообщений в Apache Kafka Хотя Apache Kafka и RabbitMQ не являются взаимозаменяемыми альтернативами, именно эти системы чаще всего используются для...
Как реализовать условную логику выполнения задач в DAG-конвейере Apache AirFlow, используя оператор ShortCircuitOperator. А также зачем использовать декоратор и при чем здесь правило триггера. Что такое ShortCircuitOperator в Apache AirFlow и как он работает Мы уже писали здесь и здесь, что с помощью операторов, существующих в Apache AirFlow, дата-инженер может...

Сегодня рассмотрим, как развернуть модель машинного обучения в конвейере Apache Kafka, используя потоковый API технологии удаленного вызова процедур от Google под названием gRPC и сервер ML-моделей TensorFlow Serving. Краткий ликбез по gRPC Напомним, gRPC – это технология интеграции систем, включая клиентский и серверный компоненты, основанная на удаленном вызове процедур в...

В рамках продвижения нашего нового курса по графовым алгоритмам в бизнес-приложениях сегодня познакомимся с графовой резидентной СУБД Memgraph и сравним ее с Neo4j, определив достоинства, недостатки и варианты использования в задачах аналитики больших данных. Memgraph vs Neo4j Memgraph — это высокопроизводительная графовая СУБД с открытым исходным кодом, которая хранит и...
Инструменты графовых алгоритмов для аналитики больших данных в PostgreSQL и Greenplum: обзор расширений и возможностей. Знакомимся с Apache AGE и MADlib. Графовая аналитика в PostgreSQL Реляционные СУБД отлично подходят для хранения данных с четкой структурой практически в любой предметной области и предлагают широкие возможности аналитической обработки таких данных. Но иногда реляционная...
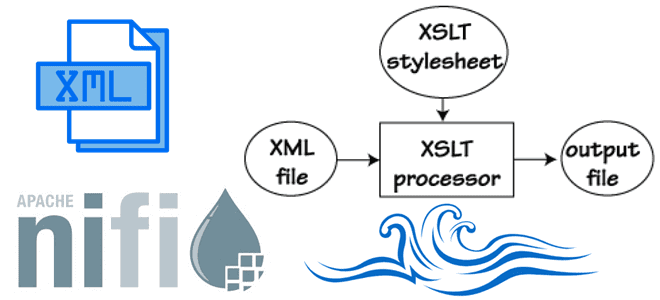
Недавно мы писали про JSON-преобразования в Apache NiFi. Продолжая тему работы с данными различного формата, сегодня рассмотрим, как штатными средствами этого потокового ETL-инструмента преобразовать данные, поступающие в виде XML-документов. Что такое XSLT Хотя сегодня XML-формат нельзя назвать самым модным, он до сих пор активно используется во многих информационных системах, которые...

Мы уже писали, как можно развернуть контейнерные приложения Apache Flink для обработки больших объемов данных в реальном времени. В продолжение этой темы сегодня сравним развертывание Flink-заданий в Kubernetes и в кластере AWS EMR. Flink-приложение в Kubernetes: преимущества и недостатки Apache Flink — это мощный фреймворк с открытым исходным кодом для...
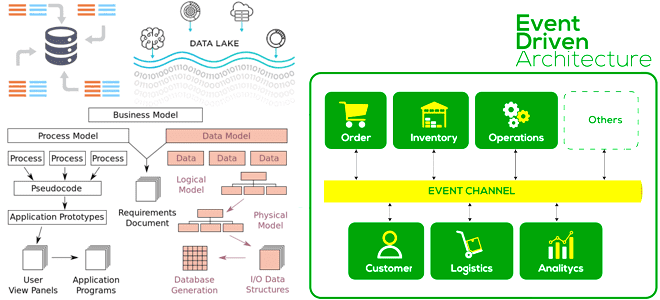
Чем схема, применяемая к данным, при чтении отличается от схемы при записи, почему она вызывает GIGO-проблему в Data Lake, и как применить принципы функциональной дата-инженерии к архитектуре данных, управляемой событиями. Схема при чтении или при записи: главное отличие NoSQL-решений от реляционных СУБД NoSQL-решения и Apache Hadoop реализуют стратегию «схема при...