
Развивая наш новый курс по Apache Kafka для разработчиков, сегодня мы рассмотрим 3 способа о взаимодействии с этой популярной Big Data платформой потоковой обработки событий с помощью языка Python, который считается самым распространенным инструментом в Data Science. Читайте далее, что такое librdkafka, чем PyKafka отличается от Kafka-Python и почему решение...

Интерактивная аналитика больших данных - одно из самых востребованных и коммерциализированных приложений для технологий Big Data. В этой статье мы рассмотрим, как крупный британский ритейлер запустил цифровую трансформацию своей ИТ-архитектуры, уходя от традиционного DWH с пакетной обработкой к событийно-стриминговой облачной платформе на базе Apache Kafka и Snowflake. Зачем модному ритейлеру...

Чтобы добавить в наши курсы для дата-инженеров еще больше реальных примеров и лучших DataOps-практик, сегодня мы расскажем, как специалисты крупной норвежской компании DNB обеспечивают надежный доступ к чистым и точным массивам Big Data, применяя передовые методы проектирования данных и реализации конвейеров их обработки. В этой статье мы собрали для вас...

В этой статье разберем, что такое прикладная аналитика больших данных на примере практического использования Apache Kafka и Druid в Netflix для обработки и визуализации метрик пользовательского поведения. Читайте далее, зачем самой популярной стриминговой компании отслеживать показатели клиентских устройств и как это реализуется с помощью Apache Druid, Kafka и других технологий...

Недавно мы рассказывали про систему онлайн-аналитики Big Data на базе Apache Kafka, Spark Streaming и Druid для площадки рекламных ссылок Outbrain, а затем на этом же кейсе рассматривали, зачем нужен Graceful shutdown в потоковой обработке больших данных. Сегодня в рамках этого примера разберем, как снизить нагрузку при потоковой передаче множества...

Сегодня мы расскажем про наши новые курсы по Apache Kafka для разработчиков Big Data. Читайте далее, зачем мы объединили тренинг по Kafka Streams и обучение интеграции этой платформы потоковой обработки событий с другими системами. Также вы узнаете, насколько новый комплексный курс по Apache Kafka полезен программистам распределенных приложений и выгоден...

Продолжая разбирать, как работает аналитика больших данных на практических примерах, сегодня мы рассмотрим, что такое Graceful shutdown в Apache Spark Streaming. Читайте далее, как устроен этот механизм «плавного» завершения Спарк-заданий и чем он полезен при потоковой обработке больших данных в рамках непрерывных конвейеров на базе Apache Kafka и других технологий...

Современная аналитика больших данных ориентируется на обработку Big Data в реальном времени. Такие вычисления «на лету» позволяют в режиме онлайн узнавать о критически важных производственных показателях и оперативно понимать клиентские потребности. Это существенно ускоряет и автоматизирует цикл принятия управленческих решений в соответствии с требованиями сегодняшнего бизнеса. Обычно для реализации архитектуры...

Чтобы сделать наши курсы по Apache Kafka для разработчиков Big Data систем еще более интересными, а обучение – запоминающимся, сегодня мы рассмотрим еще несколько примеров реализации микросервисной архитектуры на этой стриминговой платформе. А также поговорим про проблемы удаления данных в этой архитектурной модели, разобрав кейс компании Twitter по построению корпоративного...

В этой статье мы рассмотрим комплексный конвейер (pipeline) обработки больших данных с помощью алгоритмов машинного обучения (Machine Learning) для системы речевого анализа Callinter от китайской компании Fano Labs. Apache Kafka играет ключевую роль в этом аналитическом конвейере, ежедневно обеспечивая бесперебойную стабильность и высокую производительность интеллектуальной обработки нескольких тысяч часов звонков....
Продолжая разговор про инженерию больших данных, сегодня рассмотрим, как построить ETL-pipeline на открытых технологиях Big Data. Читайте далее про получение, агрегацию, фильтрацию, маршрутизацию и обработку потоковых данных с помощью Apache NiFi, Kafka и Spark, преобразование JSON, а также обогащение и сохранение данных в Hive, HDFS и Amazon S3. Пример потокового...

Мы уже писали, что такое Kafka Connect и как этот инструмент обеспечивает потоковую передачу данных между Apache Kafka и другими системами на примере интеграции с Elasticsearch. Сегодня рассмотрим новый коннектор, который позволяет загружать данные из топиков Apache Kafka в платформу удаленного мониторинга работоспособности мобильных и веб-приложений New Relic через гибкий REST API....
Продолжая разговор про практическое применение Apache Kafka на примере организации рекомендательной системы Twitter, сегодня мы рассмотрим, как с помощью Kafka Streams был разработан конвейер сбора и агрегации данных для машинного обучения (Machine Learning). Читайте в нашей статье про особенности объединения больших данных через LeftJoin и InnerJoin в Apache Kafka Streams. Архитектура приложения...
Недавно мы рассказывали про преимущества event-streaming архитектуры с помощью Apache Kafka на примере The New York Times. В продолжение этой темы Apache Kafka, сегодня поговорим про использование этой Big Data платформы в Twitter для построения конвейера потоковой регистрации событий в рекомендательной системе на базе алгоритмов машинного обучения (Machine Learning). Как...

Apache NiFi – это простая и мощная система для обработки и распределения больших данных в потоковом режиме, которая отлично справляется с огромными объемами и скоростями, оперируя с сотнями гигабайт и даже терабайтами информации. Однако, на практике при работе с этой Big Data платформой можно столкнуться с проблемой ввода-вывода (IOPS, Input-Output...

Сегодня мы продолжим разговор о событийно-процессной архитектуре Big Data систем на примере использования Apache Kafka в The New York Times. Читайте далее, как одно из самых известных американских СМИ с более чем 160-летней историей хранит в Apache Kafka все свои статьи и с помощью API Kafka Streams публикует контент в...

В этой статье мы поговорим про возможность нехарактерного использования Apache Kafka: не как распределенной стримминговой платформы или брокера сообщений, а в виде базы данных. Читайте далее, как Apache Kafka дополняет другие СУБД, не заменяя их полностью, почему такой вариант использования возможен в Big Data и когда он не совсем корректен....
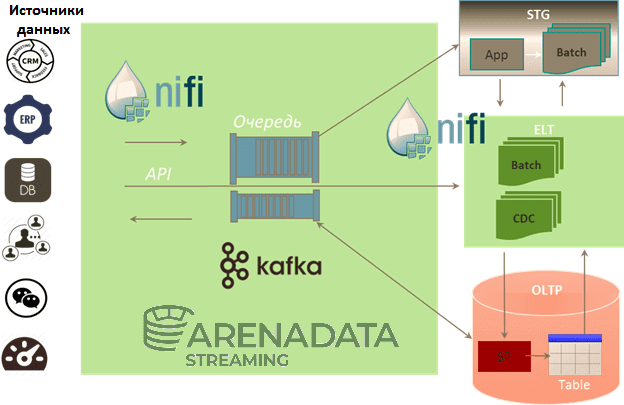
Мы уже рассказывали про преимущества совместного использования Apache Kafka и NiFi. Сегодня рассмотрим, как эти две популярные технологии потоковой обработки больших данных (Big Data) сочетаются в рамках единого решения от отечественного разработчика - Arenadata Streaming. Читайте далее про основные сценарии использования и ключевые достоинства этого современного продукта класса Event Stream...
Завершая цикл статей про MLOps, сегодня мы расскажем про 5 шаблонов практического внедрения моделей Machine Learning в промышленную эксплуатацию (production). Читайте далее, что такое Model-as-Service, чем это отличается от гибридного обслуживания и еще 3-х вариантов интеграции машинного обучения в production-системы аналитики больших данных (Big Data), а также при чем тут...
Есть мнение, что использование Apache Kafka в качестве корпоративной сервисной шины (ESB, Enterprise Service Bus) является антипаттерном. Сегодня мы проясним это категоричное утверждение и рассмотрим, как корректно реализовать ESB с помощью Kafka на практическом примере шины данных в компании Avito.ru. Что такое ESB и чем это отличается от брокера сообщений...