
В линейке продуктов Databricks не только облачная платформа аналитики больших данных на базе Apache Spark. В портфолио компании также присутствует популярный MLOps-инструмент под названием MLflow, последний релиз которого (1.27.0) вышел 1 июля 2022 года. Однако, разработчики уже анонсировали в мажорный выпуск новой версии MLOps-фреймворка с открытым исходным кодом. Читайте далее,...

Как Cluster Autotuner от Sync для автонастройки кластера Spark в AWS EMR помог edtech-компании Duolingo снизить затраты на 55%. Полезный сервис для дата-инженера и администратора кластера, чтобы устранить неэффективную ручную настройку, обеспечив оптимальную стоимость, производительность и надежность распределенных вычислений без изменения кода. Дорогой Apache Spark на AWS EMR Duolingo –...
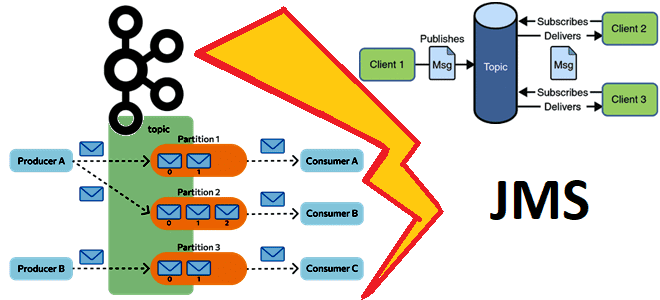
В этой статье для обучения дата-инженеров и разработчиков распределенных систем сравним Apache Kafka с популярными реализациями Java-стандартов обмена сообщениями, к которым относится Apache ActiveMQ, IBM MQ, Rabbit MQ и другие JMS-брокеры. Чем распределенная платформа потоковой передачи событий отличается от JMS-брокеров и что между ними общего. Что такое JMS-брокер Прежде чем...

Сегодня разберем тему, особенно полезную для обучения разработчиков распределенных приложений и дата-инженеров масштабных платформ аналитики больших данных на Apache Flink: обнаружение сложных цепочек связанных событий в потоковой обработке. Как создать свой шаблон поиска сложных событий с библиотекой FlinkCEP. Комплексная обработка событий или зачем вам CEP Современный data-driven бизнес хочет принимать...

В этой статье для обучения дата-инженеров и аналитиков данных заглянем под капот Apache Hive, чтобы разобраться с механизмов LLAP. Как этот движок повышает производительность популярного SQL-on-Hadoop инструмента, поддерживая длительные процессы на одних и тех же ресурсах для кэширования и аналитической обработки больших данных. Что такое LLAP в Apache Hive и...
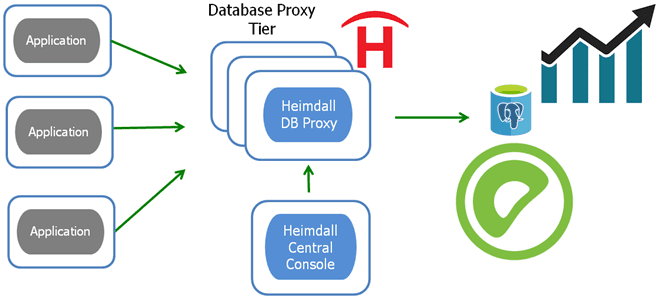
Сегодня рассмотрим, что такое Heimdall Database Proxy и как это пригодится администратору кластера Greenplum и разработчику распределенных приложений, взаимодействующих с этой MPP-СУБД. А также разберем, с какими проблемами администратор кластера может столкнуться при настройке совместного использования этих систем, и как их решить. Что такое Heimdall Database Proxy Хотя Greenplum работает...

В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня разберем, как Airbnb использует графовые нейросети для улучшения машинного обучения. А также рассмотрим, как устроены GCN-нейросети и что определяет выбор между потоковым и пакетным ML-конвейером. Анализ графов для обогащения ML-моделей Многие проблемы машинного обучения могут быть...

Сегодня рассмотрим серьезную уязвимость CVE-2022-33140, связанную с авторизациями и обнаруженную в последнем выпуска Apache NiFi 1.16.3, о котором мы писали здесь. Почему проблема с ShellUserGroupProvider оказалась так значительна и что сделано для ее устранения. Уязвимость CVE-2022-33140 в Apache NiFi 1.16.3 В свежем релизе Apache NiFi 1.16.3, который вышел 15 июня...
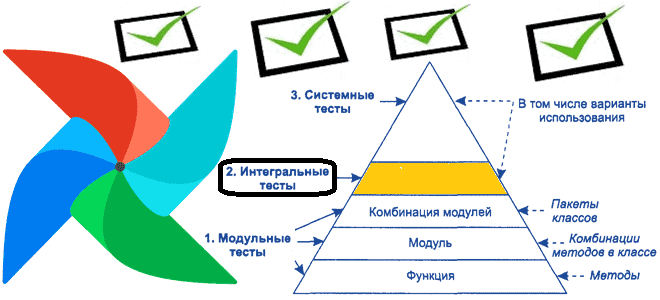
Продолжая тему тестирования DAG в Apache Airflow, сегодня рассмотрим следующий этап проверки качества ПО – разработку интеграционных тестов. Разберемся, как при этом дата-инженер может использовать Docker Compose и Pytest, а также познакомимся с возможностями REST API самого популярного в Big Data batch-оркестратора. Идеи и инструменты интеграционного тестирования DAG в Apache...

Недавно мы сравнивали разные форматы сериализации данных, поддерживаемые Apache Kafka. Однако, AVRO и JSON не могут похвастаться таким высоким коэффициентом сжатия, как колоночный бинарный формат Parquet. Читайте далее, как хранить больше потоковых данных на тех же ресурсах с помощью движка Deephaven и других open-source решений. Apache Kafka и Parquet Apache...

Постоянно добавляя в наши курсы по Apache Spark полезные материалы, сегодня мы рассмотрим, что происходит под капотом этого вычислительного движка, чтобы помочь разработчикам распределенных приложений и дата-инженерам повысить его эффективность. Тонкости сериализации данных, компиляции SQL-запросов в JavaBytecode и сборка мусора. 2 библиотеки сериализации данных в Apache Spark В распределенных системах...
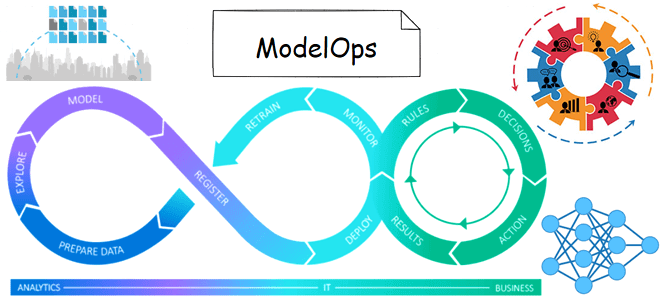
Пока инженеры данных и специалисты по Data Science привыкали к MLOps, начав понимать важность и необходимость этой концепции непрерывной разработки и эксплуатации систем машинного обучения, в Data Science появился новый термин с модным –Ops окончанием. Разбираемся, что такое ModelOps, чем это отличается от MLOps и как применить его на практике....
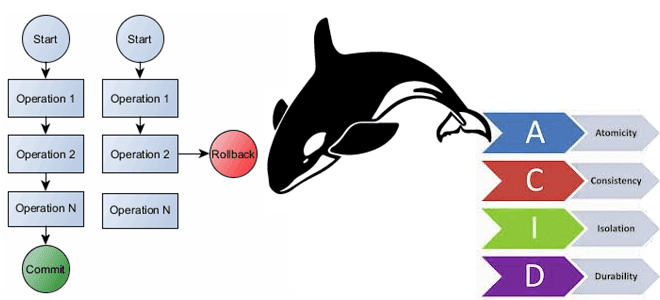
В этой статье для обучения архитекторов, дата-инженеров и аналитиков данных рассмотрим, как поддерживаются транзакции в Apache HBase и почему к ACID-свойствам также добавляется характеристика видимости обновлений. Насколько атомарны и консистентны мутации данных внутри строки HBase, почему сканирование не полностью согласовано и как разрешить устаревшие чтения или путешествия во времени в...

Сегодня рассмотрим несколько полезных приемов по работе с Apache Hive, которые пригодятся инженеру данных и специалисту по Data Science в проектах аналитики больших данных. Как разделить и сегментировать таблицы, зачем изменять значение конфигурации памяти этапов MapReduce, чем полезна автоматическая обработка асимметрии данных и еще пара лайфхаков для ускорения выполнения SQL-запросов...
Мы уже писали про важность модульного тестирования DAG Apache Airflow, а также лучшие практики и инструменты реализации этого процесса. Как протестировать структуру DAG со сложной условной логикой, сделав тест детерминированным с помощью простой сортировки идентификаторов задач, а также каким образом дата-инженеру помогут шаблоны Jinja. Проверка структуры DAG в AirFlow С...
Недавно мы писали про проблемы приложений Apache Flink в кластере Kubernetes. Сегодня рассмотрим, каким образом можно развернуть и запустить задания этого фреймворка распределенной обработки данных на самой популярной DevOps-платформе контейнерной виртуализации. Обзор операторов от Lyft, Google Cloud Platform, нативного расширения и возможностей платформы Ververica. Зачем и как выполнить развертывание Apache...

Хотя распределенные системы с микросервисной архитектурой дают множество преимуществ, процесс их проектирования достаточно сложен. В частности, нужно учитывать возможность возникновения неопределенности параллелизма или состояния гонки, и заранее предусмотреть способы решения этих проблем. Одним из них является Apache Kafka, которая гарантирует упорядоченность событий. Рассмотрим на практическом примере, как это работает. Что...

28 июня 2022 года в сотрудничестве с сообществом разработчиков Apache Spark компания Databricks анонсировала проект Lightspeed, новое поколение этого потокового движка. Читайте далее, что это такое и чем оно отличается от классического Apache Spark Structured Streaming. Потоковая обработка данных с Apache Spark Structured Streaming Потоковая передача событий весьма востребована современным...
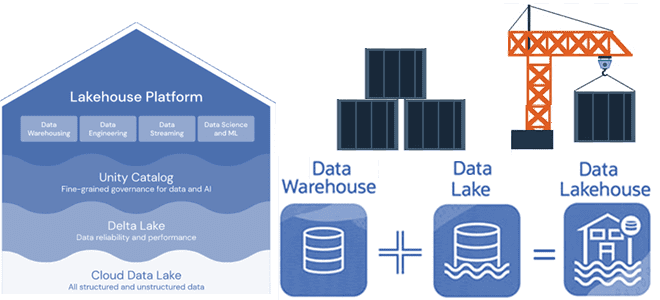
Недавно мы писали про новую гибридную архитектуру Lakehouse, которая объединяет лучше из мира озер и хранилищ данных. Сегодня разберем принципы работы и особенности построения этой архитектуры данных, включая технологии ее реализации с точки зрения дата-инженера и уделим внимание организации конвейеров аналитики больших данных. Архитектурная парадигма Lakehouse Напомним, Lakehouse — это...
Недавно мы рассказывали про стратегии обработки ошибок в потоковых конвейерах данных на Apache NiFi. В продолжении этой темы, сегодня более детально разберем, с какими исключениями может столкнуться дата-инженер, о чем они говорят и как их обойти. Виды исключений Apache NiFi При разработке собственного процессора может возникнуть несколько различных неожиданных ситуаций....