
Сегодня разберем опыт австралийской ИТ-компании hipages по построению самообслуживаемого ETL-конвейера с Apache Airflow и Amazon Athena, призванного обеспечить высокое качество данных и облегчить дата-инженерам управление информационными активами. Изящное решение сложных проблем управления данными с примерами SQL-запросов к корпоративному Data Lake на AWS S3. Что не так с монолитной архитектурой платформы данных...

Недавно мы писали про сложности разработки и развертывания ML-систем и способы их решения с помощью концепции MLOps. Продолжая эту тему, важную для обучения специалистов по Data Science, аналитиков и инженеров данных, сегодня рассмотрим основные некоторые преимущества фреймворка MLFlow для создания надежных конвейеров CI/CD в системах машинного обучения. CI/CD в MLOps...

Продвигая наши курсы для дата-инженеров и администраторов кластера Apache NiFi, сегодня рассмотрим, что такое Flow Design System, чем полезен этот подпроект фреймворка потокового сбора и маршрутизации больших данных и как его использовать на практике. Что такое NiFi Flow Design System NiFi Flow Design System (FDS) – это подпроект Apache NiFi,...

В свете импортозамещения сегодня рассмотрим российские альтернативы облачных управляемых сервисов для развертывания Apache Kafka. Сравнение отечественных Yandex Managed Service for Apache Kafka и VK Cloud Solutions Big Data с зарубежным Confluent Cloud. Облачная Apache Kafka от Confluent и не только Пожалуй, самым популярным облачным сервисом Apache Kafka во всем мире...

В рамках обучения разработчиков Spark-приложений и дата-инженеров, сегодня рассмотрим, как повысить эффективность выполнения Python-кода с помощью кросс-языковой платформы Apache Arrow. Что такое PyArrow и как это улучшает производительность PySpark-программ. Почему Spark Java быстрее PySpark и как это исправить с Apache Arrow Будучи популярным вычислительным движком в области Big Data, Apache...

Apache Airflow – мощный инструмент современной дата-инженерии. Этот оркестровщик batch-процессов позволяет запускать цепочки задач в виде направленного ациклического графа (DAG) по расписанию. Однако, планировщик Airflow имеет некоторые специфические особенности, которые необходимо знать каждому разработчику Data Flow. Об этом мы сегодня поговорим. Планирование запуска DAG в Apache AirFlow: краткий ликбез Запуски DAG...

15 марта 2022 года вышло очередное обновление MPP-СУБД VMware Tanzu Greenplum, в основе которой лежит одноименный open-source проект. Читайте далее, какие новые фичи добавлены в выпуск 6.20 и что за проблемы устранены в этом минорном релизе. Самое главное: краткий обзор новых фич Greenplum 6.20 Greenplum 6.20.0 включает следующие новые и...
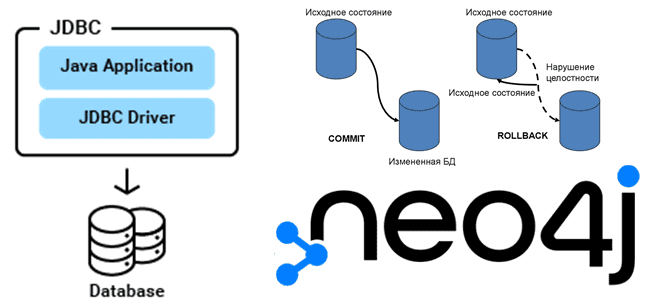
Зачем проверять подключение к Neo4j, какую URI-схему выбрать, чем плохи транзакции с автофиксацией и как передавать переменные в Cypher-запросы: рекомендации по использованию драйверов графовой СУБД в реальных приложениях аналитики больших данных. Драйверы и особенности подключения к базе данных Напомним, драйвер – это сущность, которая реализует определённые API-интерфейсы для взаимодействия с...

Мы уже рассказывали о победителях российского ИТ-конкурса «Проект Года 2020» от профессионального сообщества GlobalCIO в номинации «Аналитика и Big Data», где «Газпром нефть» и банк ВТБ делятся опытом применения российских продуктов Arenadata. Сегодня рассмотрим кейс призера 2021 года - проект «Фабрика данных» в АО «Народный банк Казахстана», в результате которого...

В этой статье для инженеров данных и разработчиков Hadoop-приложений рассмотрим опыт индийской компании Wynk по применению Apache Flink в качестве средства потоковой аналитики больших данных пользовательского поведения в мобильных приложениях прослушивания музыки. Особое внимание уделим вопросу формирования и обработки пользовательских сессий. Постановка задачи и выбор решения Wynk Music является одним...
Сегодня рассмотрим, можно ли построить на Apache Kafka быстрый и надежный блокчейн для криптовалюты, NFT или других проектов, где нужны технологии распределенного реестра. Что общего у топика Apache Kafka с blockchain-цепочкой, чем они отличаются, возможно ли совместить их и для каких случаях. А в качестве примеров перечислим несколько реальных проектов....

Сообщество разработчиков Apache NiFi регулярно радует новыми выпусками. Не успели мы полностью освоить январский релиз 2022, в начале марта появилась еще более свежая версия этого потокового маршрутизатора. Самое главное в Apache NiFi 1.16.0 для дата-инженера и администратора кластера. Главные новинки Apache NiFi 1.16.0 Apache NiFi 1.16.0 включает несколько десятков улучшений,...

Постоянно добавляя в наши курсы по Apache Spark и машинному обучению практические примеры для эффективного повышения квалификации Data Scientist’ов и инженеров данных, сегодня рассмотрим задачу пакетного прогнозирования и планирование ее запуска по расписанию без применения масштабных MLOps-решений. Apache Spark для пакетного прогнозирования Есть много готовых решений и инструментов для пакетного...
Обучая специалистов по Data Science, аналитиков и инженеров данных лучшим практикам MLOps, сегодня поговорим про переносимость моделей машинного обучения между разными этапами жизненного цикла ML-систем, от разработки до развертывания в production. А в качестве примера разберем, как использовать обученную ML-модель из Apache Spark за пределами кластера, упаковав ее в ONNX...

11 марта 2022 года вышла новая версия Apache Airflow Helm Сhart. Рассмотрим главные новинки релиза 1.5.0 и их практическую ценность с точки зрения прикладной дата-инженерии. А также разберем ключевые понятия этого менеджера пакетов Kubernetes. Что такое Helm chart в Kubernetes и причем здесь Apache AirFlow Напомним, Helm – это менеджер пакетов...
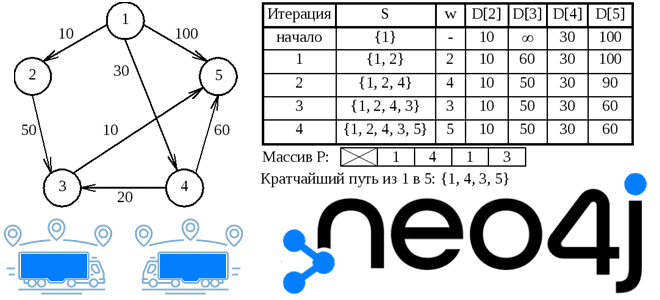
Вопрос перестройки логистических цепочек сегодня стал очень остро перед множеством предприятий, от малого до очень крупного бизнеса. Рассмотрим, как методы Data Science и аналитики больших данных помогают бизнесу справиться с современными вызовами на примере реализации алгоритма Дейкстры в библиотеке Graph Data Science графовой СУБД Neo4j. Постановка задачи: поиск кратчайшего пути...
Иногда в распределенных системах требуется строгий порядок событий, т.е. сообщений или записей с полезными данными и состоянием, который должен поддерживаться между продюсерами и потребителями в конвейере их обработки. Например, чтобы сохранить корректный порядок транзакций для правильного расчета остатков по счетам. Читайте далее, как это реализовать в Apache Kafka. Настройка продюсера...
Недавно мы писали про обновление хранилища метаданных Apache Hive с помощью команды MSCK REPAIR TABLE, операторов AirFlow и Spark-заданий. В продолжение этой темы про работу с партиционированными Parquet-файлами сегодня рассмотрим применение Spark SQL для этого случая, чтобы использовать таблицу Hive вместо временного представления Spark. Временные таблицы Hive/Spark и разделы в Parquet-файлах...

Как снизить затраты на AWS EMR, сохранив эффективность Spark-конвейеров обработки данных на спотовых инстансах и других типах узлов облачного кластера. Также рассмотрим, что такое прерываемые виртуальные машины в Яндекс.Облаке и каким образом настроить такую облачную инфраструктуру, чтобы сократить затраты на выполнение Spark-приложений, одновременно повысив их отказоустойчивость. Блеск и нищета спотовых...

В рамках обучения дата-инженеров и разработчиков Spark-приложений сегодня рассмотрим, как повысить эффективность обработки данных, используя всю мощь этого распределенного движка. Проблемы производительности и эффективности конвейера обработки данных с учетом разницы между действиями и преобразованиями в Apache Spark. Снова про разницу между действиями и преобразованиями в Apache Spark Основное преимущество Apache...