
Продвигая наши курсы по Greenplum и Arenadata DB, сегодня рассмотрим пару полезных лайфхаков, как избежать избыточного потребления памяти, настроив конфигурационные параметры операционной системы хоста. Читайте далее, почему не стоит задавать слишком большой размер страниц виртуальной памяти, зачем администратору контролировать количество spill-файлов и как в этом помогает утилита gp_toolkit. Операционная система...

Недавно мы рассказывали про KafkaJS – клиент Apache Kafka для Node.js, который отличается небольшим размером и простым развертыванием с удобным API. Сегодня рассмотрим еще пару полезных инструментов визуализации данных о Kafka-кластере на базе KafkaJS и Prometheus. Читайте далее, что такое FlowKat и Monokl, а также зачем они нужны дата-инженеру, разработчику...
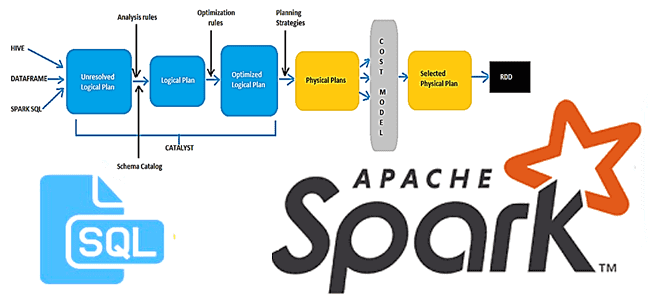
В этой статье для разработчиков Spark-приложений и дата-аналитиков рассмотрим новый оптимизатор этого фреймворка, Radiant. Он основан на SQL-оптимизаторе Catalyst и представляет собой open-source проект от энтузиастов сообщества Apache Spark. Читайте далее, чем хорош Spark-Radiant и как использовать его для оптимизации SQL-запросов при аналитике больших данных. Что такое SQL-оптимизатор Spark-Radiant и...
В рамках обучения дата-инженеров сегодня заглянем под капот системы Cloudera Flow Management, которая является частью платформы Cloudera DataFlow и основана на Apache NiFi. Вас ждет разбор основных концепций жизненного цикла потоковой разработки и их реализация в Apache NiFi с практическими примерами и рекомендациями по применению. Что такое Cloudera Flow Management...

Когда имеются графы (dags), зависимые от других, то лучше всего объединить их в один или использовать TaskGroup, о котором говорили в прошлой статье. Но если по каким-то причинам сделать это не удается, то Apache Airflow предоставляет различные способы запуска графа внутри другого. Одним из таких является TriggerDagRunOperator. В этой статье...
Сегодня рассмотрим, что такое KafkaJS, как это связано с Apache Kafka и JavaScript, в чем преимущества этой технологии и как разработчику распределенных приложений потоковой аналитики больших данных использовать ее на практике. Также вас ждет краткий ликбез по Node.js и примеры разработки KafkaJS-приложения. Краткий ликбез по Node.js Важными достоинствами архитектуры потоковой передачи...

При том, что Apache Airflow сегодня считается главным инструментом дата-инженерии, он далеко не единственное средство оркестрации пакетных заданий и построения конвейеров обработки больших данных. В рамках продвижения наших курсов для инженеров Big Data, сегодня рассмотрим, что такое Apache Hop, чем это отличается от AirFlow и где использовать эту платформу, а...

Хотя наши практические курсы по Greenplum и Arenadata DB больше ориентированы на аналитиков и дата-инженеров, чем на администраторов, в программы обучения также включены важные сведения по настройке этих MPP-СУБД. В этой статье мы собрали лучшие практики системного конфигурирования кластера Greenplum, которые помогут повысить эффективность аналитики больших данных в этой Big...

Реклама является одним из наиболее крупных сегментов практического применения технологий Big Data. Поэтому сегодня рассмотрим, как Flink SQL реализует потоковую аналитику больших данных в AdTech-кейсах. Разбираем пример JOIN-соединения двух потоков событий - показов и кликов, чтобы вычислить конверсию рекламной кампании средствами Apache Flink или Spark. Потоки Big Data за фасадом...
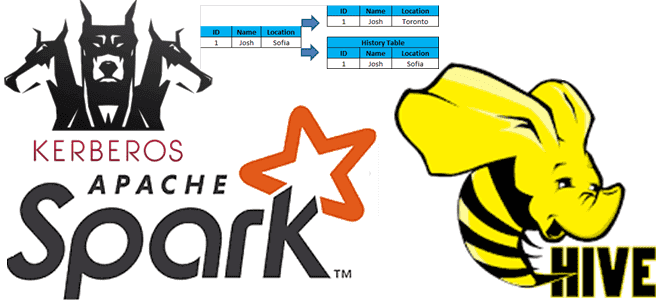
В этой статье для разработчиков распределенных приложений Apache Spark, администраторов SQL-on-Hadoop и дата-аналитиков рассмотрим особенности аутентификации удаленного пользователя, а также отслеживание измененных данных в таблицах Apache Hive. Читайте далее, зачем ограничивать доступ к keytab-файлу в кластерах с поддержкой защищенного протокола Kerberos, а также как реализовать отслеживание медленно меняющихся измерений в...
В поддержку курсов по администрированию Apache Kafka, сегодня рассмотрим особенности масштабирования кластера и связанное с этим переназначение разделов. Читайте далее, чем горизонтальное масштабирование лучше вертикального, как переназначить разделы между брокерами Kafka с целью перебалансировки нагрузки и зачем ограничивать полосу пропускания для перемещения реплик между узлами кластера. Проблемы масштабирования кластера Apache...

В этой статье мы поговорим про функции группировки и сортировки в распределенной СУБД Apache Impala. Читайте далее про особенности работы механизма группировки и сортировки Big Data, которые позволяют Impala-разработчику обрабатывать большие массивы данных любых типов с минимальными временными затратами. Как работает механизм группировки и сортировки данных: особенности обработки Big Data...

В рамках обучения разработчиков Spark-приложений, сегодня рассмотрим, как сохранить датафрейм в памяти вне кучи исполнителя и зачем это нужно. Вас ждет краткий ликбез по управлению памятью в Apache Spark с описанием настраиваемых конфигураций. Также на простом практическом примере разберем, как это сделать и где в пользовательском веб-интерфейсе фреймворка посмотреть результаты...

Сегодня рассмотрим, как построить конвейер потоковой обработки событий на Apache Kafka, Flink и SQL Stream Builder с визуализацией результатов в Grafana. Далее вас ждет практический кейс применения технологий Big Data в реальном производстве на примере телеметрии процессов ферментации продуктов в небольшой частной пивоварне. Постановка задачи: бизнес-контекст и используемые технологии В...
Завершая серию статей по IoT-платформе компании Tesla на базе Apache Kafka, сегодня рассмотрим проблемы пиковой загрузки системы и особенности обработки высокоприоритетных событий. Читайте далее, как оптимально определить ключ раздела, чтобы снизить затраты на передачу данных, избежать перегрузки в пиковые моменты и отделить пользователей данных от разработчиков и дата-инженеров. Тонкости обработки...

В этой статье для дата-инженеров мы собрали лучшие практики построения масштабируемых конвейеров обработки данных, а также популярные рекомендации по проектированию ETL/ELT-процессов с Apache Spark, AirFlow и другими технологиями Big Data. Читайте далее, когда ELT лучше ETL и наоборот, чем хорош Apache Spark в конвейерах обработки Big Data, зачем нужен AirFlow,...
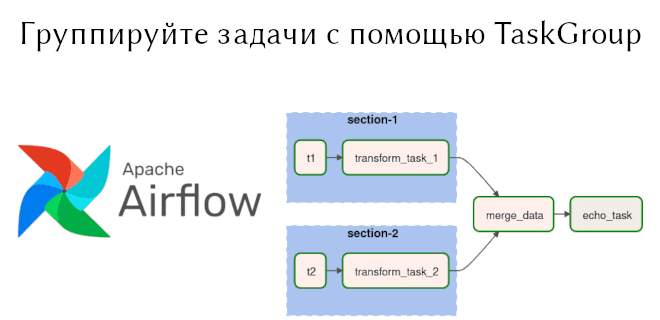
В предыдущей статье мы рассмотрели TaskFlow API, появившийся в Apache Airflow 2.0. Сегодня поговорим о способах задания операторов, отличных от PythonOperator, а также о способе группировки задач TaskGroup. Читайте далее: как сформировать BashOperator, используя TaskFlow API, когда следует использовать TaskGroup, в чем преимущества TaskGroup перед SubDag. Используем Bash Operator в...
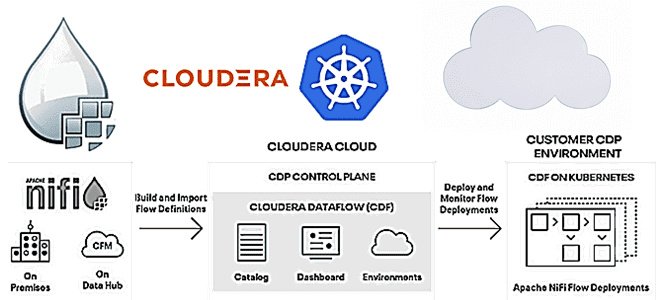
Чтобы сделать наши курсы по Apache NiFi для дата-инженеров еще более полезными, сегодня рассмотрим новые возможности последнего релиза Cloudera Flow Management 2.1.1 на базе этого фреймворка. Выпущенная в апреле 2021 года, платформа Cloudera Flow Management в составе публичного и частного облака предоставляет Apache NiFi версии 1.13.2, включая дополнительные компоненты, а...

В рамках курсов по Apache Hadoop для дата-аналитиков и инженеров данных сегодня рассмотрим пару практических примеров работы с популярным SQL-on-Hadoop инструментом этой экосистемы. Читайте далее, как настроить соединение удаленного сервера Apache Hive к Spark-приложению через JDBC и решить проблему запроса таблицы HBase в Hive вместо повторной репликации данных. Подключение удаленного...

Мы уже упоминали, что Apache Kafka не слишком хорошо обрабатывает сообщения чрезмерно большого размера. Сегодня рассмотрим, как эта проблема решается в конвейерах потоковой обработки IoT-инфраструктуры Tesla. Читайте далее про модификацию синтаксического анализатора данных от множества устройств интернета вещей с поиском компромисса между скоростью и надежностью с помощью коннектора Alpakka к...