
В рамках курсов для дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим пример построения системы потоковой передачи для аналитики больших данных на базе Apache Kafka, Spark и Google BigQuery. Читайте далее про Proof of Concept для конвейера продуктовой аналитики, который обрабатывает 50 миллиардов событий каждый день, и какие важные уроки ИТ-архитектор...

Являясь лидером отрасли, IoT-устройства Tesla обрабатывают триллионы событий в день, чтобы повысить эффективность своих электроавтомобилей. Однако, такая производительность была получена не сразу: чтобы достичь ее, инженерам компании пришлось решить множество проблем из области интернета вещей (Internet of Things, IoT). Сегодня рассмотрим, как часть из них была решена с помощью Apache...
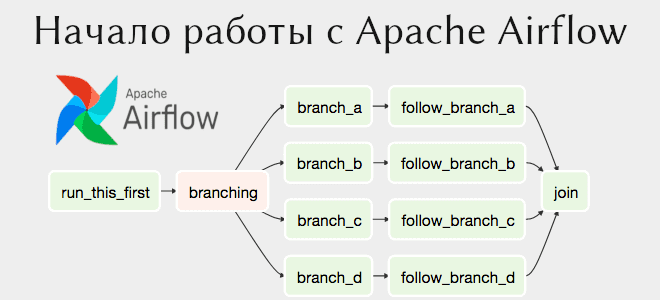
В прошлой статье мы рассмотрели установку Apache Airflow на свой компьютер. Данная платформа предназначена для планирования задач, например, выполнения скриптов Bash и Python в заданное время, в заданной последовательности. Сегодня на примере выполнения двух Bash-команд расскажем, как создать свой первый граф. Читайте в этой статье: связи между задачами, создание графа...

Apache Airflow имеет множество зависимостей, поэтому установка может быть проблематичной. В отличие от 1-й версии, Airflow 2 устанавливается гораздо проще. В этой статье разберем установку Apache Airflow через пакетный менеджер pip и через Docker. Локальная установка Apache Airflow Apache Airflow был протестирован на: Python: 3.6, 3.7, 3.8, 3.9 СУБД (Система...
В рамках программы курсов по Greenplum и Arenadata DB, сегодня рассмотрим важную для разработчиков и администраторов тему об особенностях оптимизатора SQL-запросов GPORCA, который ускоряет аналитику больших данных лучше встроенного PostgreSQL-планировщика. Читайте далее, как выбирать ключ дистрибуции, почему для GPORCA важна унифицированная структура многоуровневой партиционированной таблицы и каким образом оптимизаторы обрабатывают...

YARN считается самым распространенным диспетчером ресурсов в кластерах Apache Hadoop и Spark, отвечая за выделение ресурсам распределенным приложениям. Сегодня в рамках обучения дата-инженеров и администраторов Hadoop рассмотрим достоинства и недостатки 3-х вариантов планирования ресурсов в YARN. Читайте далее, что такое иерархия очереди и как вычисляется ее мгновенная справедливая доля. Планирование...

В прошлый раз мы говорили про особенности работы и создания представлений в Impala. Сегодня поговорим про модифицированный вывод в распределенной SQL-платформе Apache Impala. Читайте далее про особенности модификации вывода записей в Impala, включая базовые операторы, которые применяются для вывода конкретных записей. Базовые SQL-операторы для модификации вывода записей в распределенной СУБД...

Инженерия данных нужна не только большим компаниям с крупными Big Data проектами. Сегодня рассмотрим, как Apache AirFlow повышает эффективность low-code фреймворка Zapier с помощью своего REST API и Amazon SQS. Также читайте далее об интеграции приложений без разработки кода и удаленный запуск Matillion-заданий в AWS с AirFlow. Low Code интеграция...

Apache Storm обычно сравнивают со другими популярными фреймворками потоковой аналитики больших данных: Spark и Flink. Однако для несложной обработки событий дата-инженер может заменить эти платформы более легким инструментом маршрутизации потоковых данных в виде Apache NiFi. Сегодня сравним Apache NiFi co Storm и разберем практический пример, когда предпочтительнее именно его для...

Сегодня в рамках обучения дата-аналитиков и разработчиков Spark-приложений, рассмотрим еще несколько особенностей этого фреймворка. Почему count() работает по-разному для RDD и DataFrame, как отличается уровень хранения при применении метода cache() для этих структур, когда использовать SortWithinPartitions() вместо sort(), а также парочка тонкостей обработки Parquet-таблиц в Spark SQL и кэширование метаданных...

В этой статье для дата-инженеров и администраторов Apache Kafka рассмотрим, зачем Confluent выпустил премиум коннектор Splunk S2S Source и как на базе этих платформ построить эффективную систему потоковой аналитики больших данных. Также читайте далее, что такое универсальный сервер рассылки Splunk и какие конфигурации коннектора позволяют автоматически создавать топик Kafka для сбора...
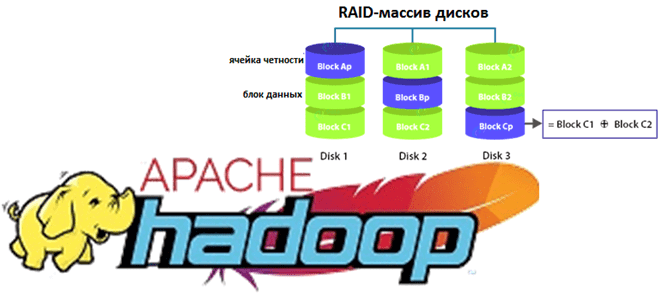
Недавно мы рассказывали про новые функции свежего релиза Apache Hadoop 3.3.1. Сегодня разберем подробнее, что такое Erasure Coding и как эта технология кодирования со стиранием экономит место в распределенной файловой системе HDFS. Также заглянем внутрь EC и рассмотрим, чем алгоритм Рида-Соломона лучше ассоциативной операции XOR для обеспечения отказоустойчивости хранилища больших...
Чтобы добавить в курсы по Apache AirFlow еще больше полезных примеров, сегодня рассмотрим, как избежать дублирования кода при загрузке данных. Этот пример пригодится дата-инженерам в работе с ELT-процессами наполнения информацией корпоративных хранилищ и озер данных. Читайте про фреймворк динамической загрузки данных на базе конфигурационных YAML-файлов, DAG-фабрик и загрузчиков. Проблема дублирования...

Сегодня рассмотрим, что такое Beekeeper и как этот сервис помогает администраторам Hadoop и пользователям Apache Hive очищать метаданные этого NoSQL-хранилища. Читайте далее, зачем удалять устаревшие пути из Metastore и как настроить конфигурацию Hive-таблиц для автоматического прослушивания событий их изменения. Для чего очищать потерянные метаданные в Apache Hive Напомним, Apache Hive...

Поскольку Greenplum и Arenadata DB основаны на популярной open-source СУБД PostgreSQL, сегодня разберем, чем они отличаются от этой объектно-реляционной базы данных. Далее вас ждет краткий и понятный ответ на вопрос Greenplum vs PostgreSQL: сходства и отличия этих систем с учетом аналитики больших данных и практических кейсов дата-инженерии. Что общего между...

Чтобы самостоятельное обучение по Hive стало еще интереснее, сегодня мы предлагаем вам простой тест по основам работы с драйвером-коннектором JDBC в этой распределенной СУБД, включая его особенности работы и взаимодействия с Java-приложениями. Тест по основам работы драйвера JDBC для новичков Для тех, кто начинает самостоятельное обучение по Apache Hive, мы...

В этой статье в поддержку курсов по Apache NiFi заглянем под капот этой платформы маршрутизации потоковых данных и рассмотрим, как дата-инженер может создать собственный процессор. Смотрите далее, как устроены процессоры в Apache NiFi, что общего между отношениями и маршрутами движения потоковых данных, как создать FlowFile, зачем нужен метод onTrigger() и...

Специально для разработчиков распределенных приложений, Data Scientist’ов и аналитиков больших данных, работающих с Apache Spark, в этой статье мы собрали несколько полезных советов по ежедневным операциям в этом фреймворке. Читайте далее, как добавить библиотеку TypeSafe в файл sbt-конфигурации Spark-приложения, получить датафреймы из JSON-массивов и структур, а также обработать CSV-формат с...
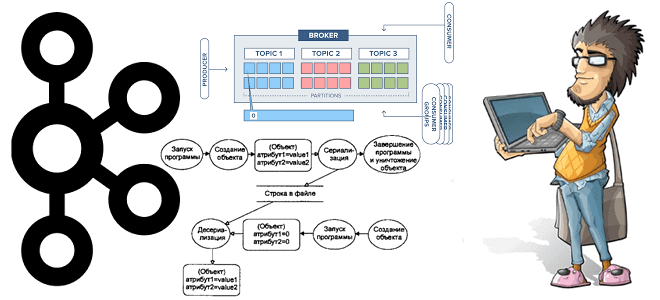
В рамках курсов по Apache Kafka для разработчиков и администраторов кластера, сегодня заглянем под капот AdminClient и на практических примерах разберем, как динамически создавать новый топик и описывать его программным способом через API. Еще рассмотрим, почему метод deleteTopics() нужно применять очень осторожно, а также вспомним основы ООП, говоря про классы...

Обучая разработчиков и администраторов Greenplum, а также в рамках продвижения курсов по Arenadata DB, сегодня рассмотрим, как SQL-оптимизатор ORCA ускоряет аналитику больших данных, позволяя реализовать многостороннее соединение таблиц через JOIN-запросы. Читайте далее, что такое GPORCA, как его использовать, насколько он эффективен по сравнению с другими планировщиками SQL-запросов в этой MPP-СУБД...