
Мы уже затрагивали тему корпоративных хранилищ данных (КХД), управления мастер-данными и нормативно-справочной информаций (НСИ) в контексте технологий Big Data. В продолжение этого, сегодня рассмотрим, что такое профилирование данных, зачем это нужно, при чем тут озера данных (Data Lake) и ETL-процессы, а также прочие аспекты инженерии и аналитики больших данных. Что...

Сегодня мы расскажем, почему каждый Big Data специалист должен знать этот язык программирования и как «Школа Больших Данных» поможет вам освоить его на профессиональном уровне. Читайте в нашей статье, кому и зачем нужны корпоративные курсы по Python в области Big Data, Machine Learning и других методов Data Science. Чем хорош...

В этой статье поговорим про интеграцию ELK-стека с экосистемой Apache Hadoop: зачем это нужно и с помощью каких средств можно организовать обмен данными между HDFS и Elasticsearch, а также при чем здесь Apache Spark, Hive и Storm. Еще рассмотрим несколько практических примеров, где реализована такая интеграция Big Data систем для...
Вчера мы затрагивали тему управления поставками в ритейле с помощью технологий Big Data и Machine Learning. Теперь разберем подробнее, как большие данные, машинное обучение и интернет вещей меняют складскую логистику и насколько это выгодно бизнесу. Сегодня мы собрали для вас 7 практических примеров: кейсы от отечественных и зарубежных транспортных компаний,...

В этой статье мы продолжим рассказывать про практическое использование отечественных Big Data решений на примере российского дистрибутива Arenadata Hadoop (ADH) и массивно-параллельной СУБД для хранения и анализа больших данных Arenadata DB (ADB). Сегодня мы приготовили для вас еще 3 интересных кейса применения этих решений в проектах цифровизации бизнеса и государственном...

В продолжение темы про корпоративные хранилища данных, сегодня мы рассмотрим облачные варианты Data Warehouse с учетом тренда на расширенную аналитику Big Data на базе машинного обучения. Читайте в нашей статье про синергию классической LSA-архитектуры локального КХД с Лямбда-подходом, MPP-СУБД, а также Apache Hadoop, Spark, Hive и другими технологиями больших данных....
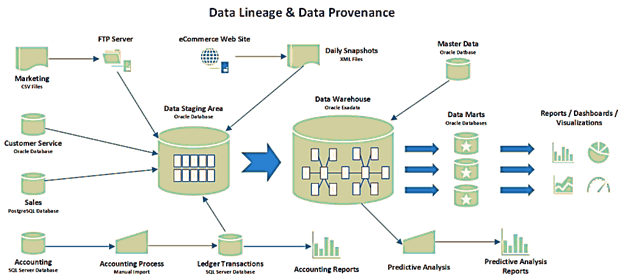
В этой статье мы продолжим разговор про основы управления данными и рассмотрим, что такое data provenance и data lineage, чем похожи и чем отличаются эти понятия. Также разберем, почему эти термины особенно важны для Big Data, какие инструменты помогают работать с ними, а также при чем здесь GDPR. Что такое...
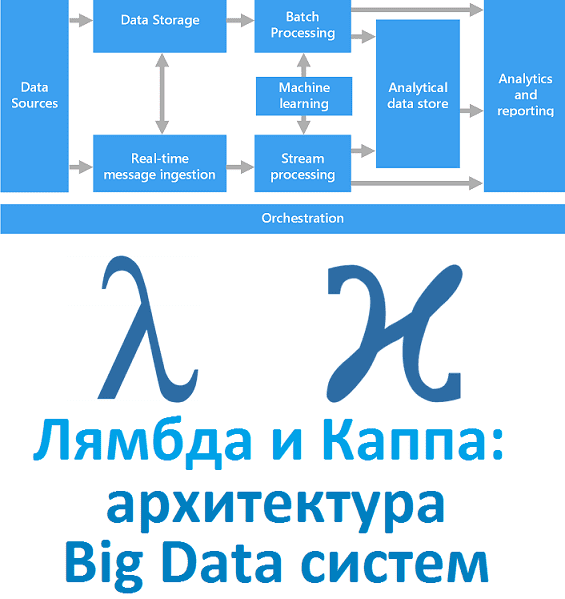
Вчера мы рассказали, что такое лямбда-архитектура. Сегодня рассмотрим Каппа - альтернативный подход к проектированию Big Data систем. Читайте в нашей статье, зачем нужна эта концепция, каковы ее достоинства и недостатки, чем Каппа отличается от Лямбда, где это используется на практике и при чем тут Apache Kafka с Machine Learning. Зачем...
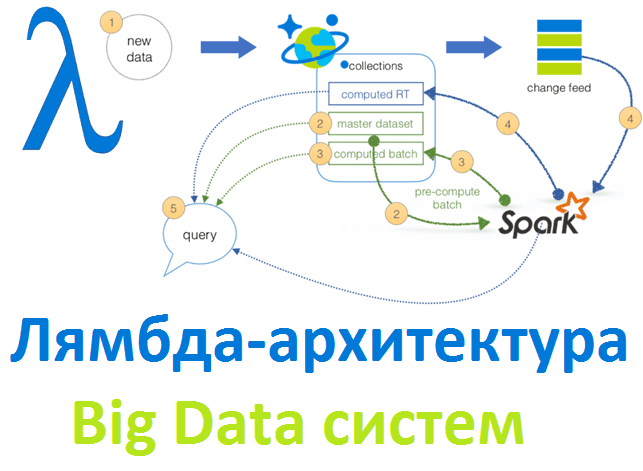
Рассматривая основы больших данных, сегодня мы расскажем лямбда-архитектуру, одну из двух главных подходов к построению Big Data систем. Читайте в нашей статье, зачем нужна эта концепция и как она работает, а также при чем тут машинное обучение, интернет вещей, Apache Spark и Hadoop. Что такое Лямбда-архитектура и зачем она нужна...
Не претендуя на лавры Мэри и Тома Поппендиков, которые впервые освятили применение Lean в разработке ПО, сегодня мы расскажем, как идеи бережливого производства реализуются в области Big Data. Читайте в нашей статье про принцип вытягивания в Apache Kafka, концепцию «точно вовремя» в Apache Spark, SMED в Kubernetes и облачных кластерах...