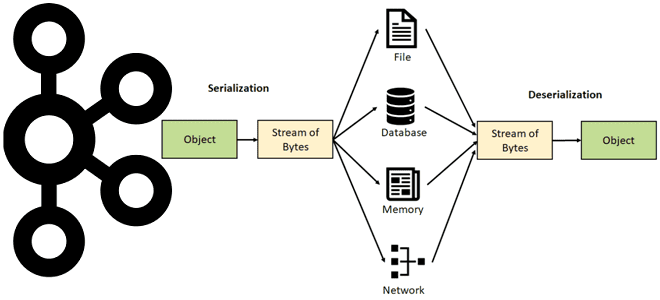
Недавно мы писали про сериализацию и десериализацию данных в Apache Kafka. Продолжая эту важную для обучения дата-инженеров и разработчиков распределенных приложений тему, рассмотрим особенности преобразования и валидации сообщений в JSON-формате, а также поговорим про автоматическую идентификацию формата сообщения. Сериализация и десериализация данных в Apache Kafka Выполняя роль интеграционной платформы, Apache...
В июле 2022 года на конференции Data and AI Summit компания Databricks представила новый проект для экосистемы Apache Spark под названием Spark Connect. Что это такое и как оно пригодится разработчикам распределенных приложений и дата-инженерам, читайте далее. Что не так с Apache Spark и зачем нужен новый проект Databricks Появившись...
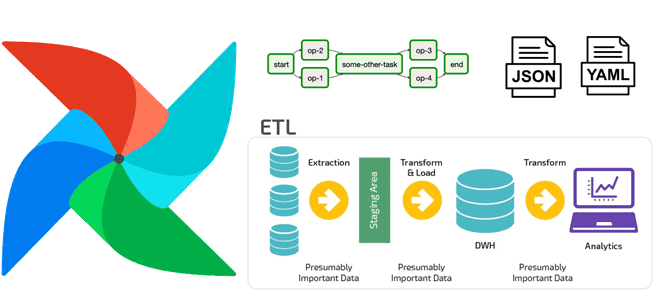
Дата-инженеры часто сталкиваются с изменением структуры конвейера обработки данных в Apache AirFlow, например, когда добавляются новые источники или приемники данных. Однако, менять DAG каждый раз при изменении внешних условий довольно утомительно. Читайте далее, как автоматизировать реорганизацию DAG, используя JSON, YAML-файл или другую плоскую структуру данных для хранения динамической конфигурации рабочего...
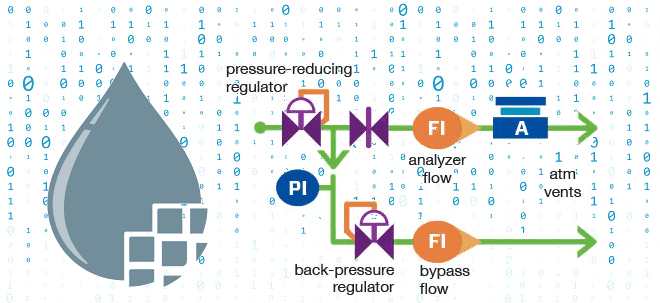
Чтобы сделать наши курсы для дата-инженеров по Apache NiFi еще более полезными, сегодня мы рассмотрим, что такое обратное давление и как этот механизм используется при потоковой обработке данных. Также поговорим про визуализацию back pressure в GUI, математические модели прогнозирования пороговых значения и настройку конфигураций. Что такое обратное давление в потоковой...

9 сентября 2022 года VMware Tanzu выпустили Greenplum 6.22. А спустя месяц, 7 октября вышел апгрейд этого релиза с исправлением ошибок. Разбираем, что нового в этих выпусках: полезные функции, улучшения и исправления ошибок, особенно важные для администратора кластера и дата-инженера. Greenplum 6.22.0 Сентябрьское обновление Greenplum 6.22.0 включает следующие функциональные возможности...
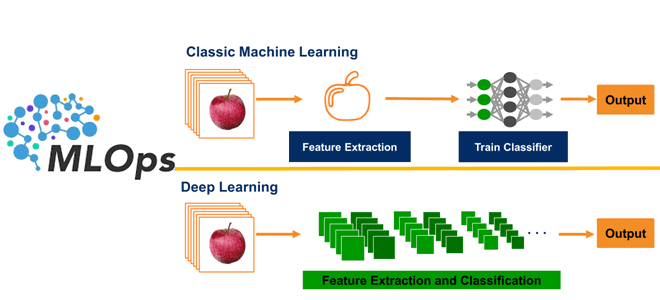
Сегодня разберем, что такое глубокое обучение и почему MLOps очень важен для этих методов Machine Learning. В чем особенности обучающих данных для моделей Deep Learning и зачем дополнять типовые MLOps-инструменты собственными разработками, избегая вредных антипаттернов. Машинное обучение vs Deep Learning: разница для MLOps Создание ML-систем сводится не только к разработке...

Недавно мы рассматривали, как дата-инженеры Airbnb перевели аналитические нагрузки корпоративного озера данных с Apache Hive на Iceberg и Spark. Продолжая разговор про эти фреймворки реализации Data Lake, сегодня разберем стратегии миграции озера данных с Apache Hive на Iceberg. Зачем уходить с Apache Hive на Iceberg и как это сделать Напомним,...

В этой статье для обучения дата-инженеров и разработчиков приложений потоковой аналитики больших данных рассмотрим, на что следует обратить внимание при развертывании Apache Flink в реальных проектах. Обработка опоздавших данных, тонкости сериализации, проблемы неравномерного распределения и большие состояния заданий. Обработка опоздавших данных в Apache Flink В потоковой обработке данных, которую поддерживает...
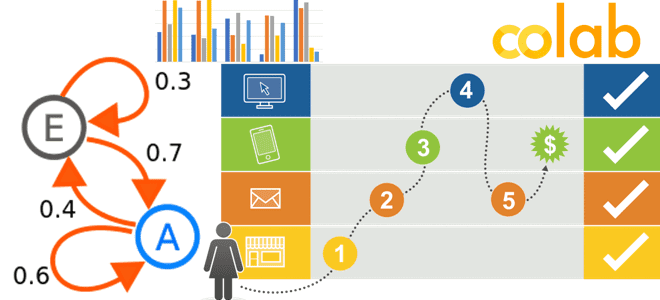
Недавно мы писали, что такое цепь Маркова, как это используется в практических приложениях Data Science и с помощью каких инструментов реализуется этот граф состояний. В продолжение этой полезной для обучения дата-аналитиков темы посмотрим на модели маркетинговой атрибуции как на марковские цепи и разберем пользу этого представления. Практический пример в Google...
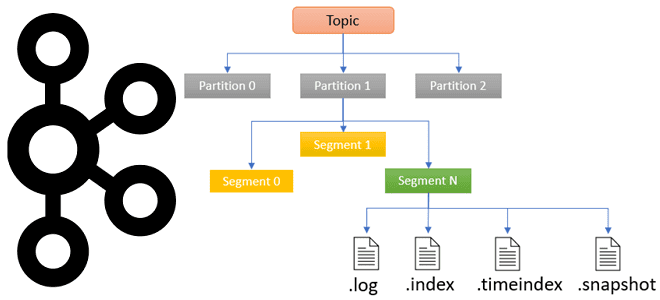
Чтобы сделать наши практические курсы по Apache Kafka еще более полезными, сегодня рассмотрим, в каких файлах хранятся сообщения, смещения и состояния продюсера, а также функции работы с ними для потоковой передачи событий. Средства обработки и хранения данных в Apache Kafka Прежде, чем погружаться в тонкости хранения данных в Apache Kafka,...

Сегодня мы продолжим говорить про Apache Spark Structured Streaming и его применение для обновления данных в таблицах Delta Lake. А также на практических примерах разберем, как выполняются основные операции работы с данными средствами Spark Structured Streaming API. Таблицы в Delta Lake Delta Lake – это уровня хранилища данных с открытым...

В этой статье для обучения дата-инженеров и администраторов кластера Apache AirFlow рассмотрим, как обновить этот ETL-планировщик, используя концепцию сине-зеленого развертывания. Также рассмотрим, с какими ошибками можно столкнуться, выполняя миграцию базы данных метаданных и как их решить. Сине-зеленое развертывание для обновления AirFlow Как и любое программное обеспечение, Apache AirFlow нужно периодически...
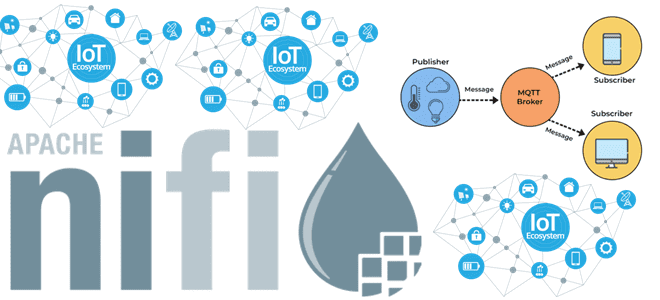
В прошлой статье про обновление Apache NiFi мы писали, что в новой версии 1.18.0 улучшено взаимодействие с протоколом MQTT, который активно используется в системах интернета вещей. Сегодня разберем более подробно, как наладить сбор и публикацию данных в MQTT-топики с помощью процессоров Apache NiFi, а также разберем, что такое брокер HiveMQ....
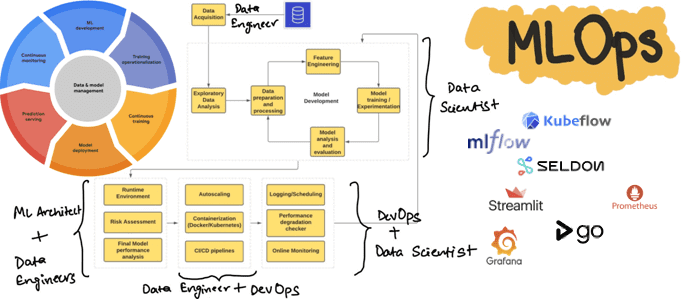
Сегодня рассмотрим, как реализовать полноценный MLOps-цикл, используя свободные инструменты с открытым исходным кодом: MLflow, Kubeflow, Seldon, Streamlit, AirFlow, Git, Prometheus и Grafana. Процессы жизненного цикла ML-систем Концепция MLOps использует проверенные методы DevOps для автоматизации создания, развертывания и мониторинга конвейеров машинного обучения в производственной среде, устраняя рост технического долга в ML-проектах....

Продолжая недавний разговор про Apache Spark Structured Streaming, сегодня рассмотрим, как этот движок потоковой обработки данных помогает дата-инженеру реализовать идемпотентную запись в таблицы Delta Lake, а также выполнить операции слияния и обновления/вставки в помощью метода foreachBatch(). Идемпотентность потоковых приложений Apache Spark Идемпотентность – важное свойство распределенных систем, которое гарантирует, что...

Недавно мы рассматривали тонкости проектирования схем данных в Greenplum. Продолжая разбирать важные для обучения дата-инженеров и архитекторов DWH темы, сегодня поговорим о том, как разделение и распределение данных влияют на скорость выполнения SQL-запросов в этой MPP-СУБД. Распределение данных Напомним, MPP-СУБД Greenplum широко используется в качестве OLAP-системы и корпоративного хранилища данных....

Сегодня рассмотрим, как дата-инженеры маркетплейса Whatnot масштабировали потоковую обработку данных с помощью Apache Kafka, изменив свои ETL-процессы и реализовав на этой распределенной платформе шину событий для анализа пользовательского поведения c ksqlDB и Rockset. Постановка задачи: события пользовательского поведения в Whatnot Whatnot – это маркетплейс, пользователи которого могут покупать и продавать...
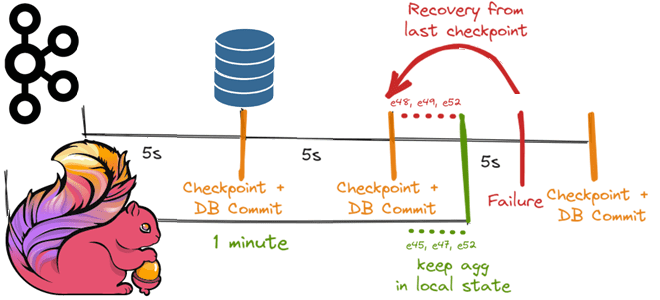
Как Apache Flink реализует строго однократную доставку событий в потовой обработке данных с помощью контрольных точек для записи данных в реляционную базу, используя функцию TwoPhasedCommitSink(), основанную на механизме согласованных snapshot’ов 35-летней давности и Kafka Transaction API. Трудности строго однократной доставки в потоковой обработке данных Распределенная обработка потоков с отслеживанием состояния...

Какова роль каталогов метаданных в корпоративных Data Lake, почему Hive Metastore не отвечает всем потребностям современной дата-инженерии в гибком управлении данными и в чем преимущества формата открытых таблиц Iceberg над таблицами Hive и Delta Lake. Каталоги метаданных в Data Lake Для организации данных в корпоративных озерах используются каталоги метаданных, которые...
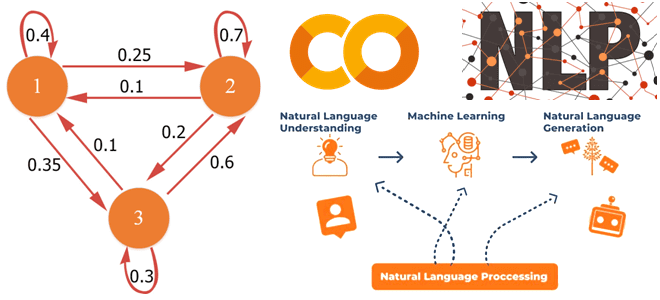
В этой статье для обучения аналитиков данных и специалистов по Data Science рассмотрим, что такое цепь Маркова, где это используется в практических приложениях и с помощью каких инструментов можно реализовать этот граф состояний. В качестве примера рассмотрим генерацию фраз из небольшого текста с помощью методов библиотеки markovify в интерактивном блокноте...