
28 октября 2022 года вышел мажорный релиз Apache Flink. Что нового в выпуске 1.16.0, который сегодня имеет официальный статус стабильного: зачем нужен SQL Gateway, как улучшен Changelog State Backend, какие DDL-выражения добавлены и зачем внесена поддержка кэширования результата преобразования в PyFlink. Главные обновления Apache Flink 1.16 В версии 1.16 Flink...
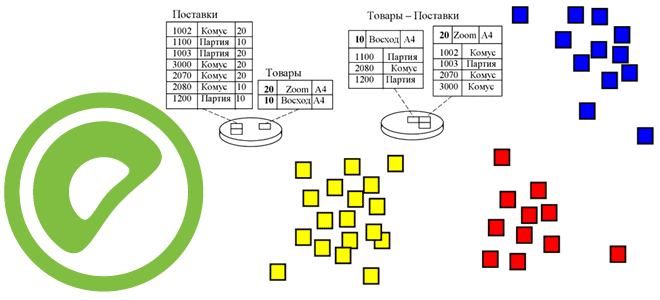
Что означает кластеризация таблиц в PostgreSQL, как это связано с индексацией и очисткой данных, чем полезно применение команды CLUSTER для AO/CO-таблиц в Greenplum 7, а также какой SQL-запрос поможет найти все кластеризованные таблицы в текущей базе данных. Как работает кластеризация таблиц в PostgreSQL Будучи основанной на объектно-реляционной базе данных PostgreSQL,...

Чем задание в Spark-приложениях отличается от задачи, зачем нужны этапы и при чем здесь драйверы с исполнителями. Разбираемся с основами разработки в самом популярном движке для распределенных вычислений: ликбез для дата-инженеров. Основные концепции Spark-приложений Приложение Spark — это программа, созданная с помощью Spark API и работающая в совместимом с этим...

Политики хранения, сжатия и очистки данных в топиках Apache Kafka: какие конфигурации нужно настроить, чтобы работать с файлами распределенных логов наиболее эффективно. Ликбез для администратора кластера Kafka и дата-инженера. Хранение данных в Apache Kafka Мы уже писали, что топик в Apache Kafka представляет собой не физическое, а логическое хранение данных....
Как LinkedIn построила масштабируемую инфраструктуру конвейеров машинного обучения, развернув модели TensorFlow на Apache Kafka, Spark и Hadoop YARN. Что такое платформа TonY, как она работает, почему изначально вычислительная парадигма MapReduce не очень хорошо подходила для глубокого обучения и как это исправить через конфигурацию настроек YARN. MLOps и проблемы глубокого обучения...

Зачем маркировать DAG в Apache AirFlow тегами, как их задать и где это пригодится дата-инженеру. А также еще разберем, какими свойствами должен обладать хорошо спроектированный конвейер обработки данных и как они улучшают их качество. Тегирование DAG в Apache AirFlow Когда дата-инженер работает с несколькими конвейерами данных, помнить все зависимости между...
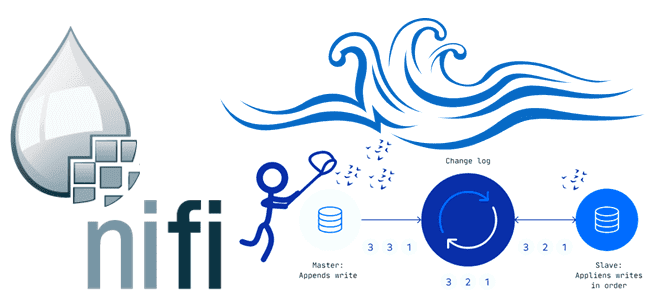
В этой статье для обучения дата-инженеров рассмотрим, как организовать сбор измененных данных из реляционных СУБД, построив CDC-конвейер с помощью Apache NiFi. А также разберем, зачем процессоры этого потокового ETL-маршрутизатора используют технологию веб-хуков. ETL-конвейер для DWH и Data Lake В общем случае сбор данных из реляционных и нереляционных источников и построение...

Интерактивные блокноты Jupyter стали фактически стандартом де-факто для Data Scientist’ов, использующих Python. Многие дата-инженеры и разработчики Spark тоже используют этот легковесный, но очень удобный инструмент. Однако, чтобы применять его для промышленной разработки Big Data приложений, нужно подключить сервер Jupyter к кластеру Spark. Читайте, как это сделать, если кластер Apache Spark...
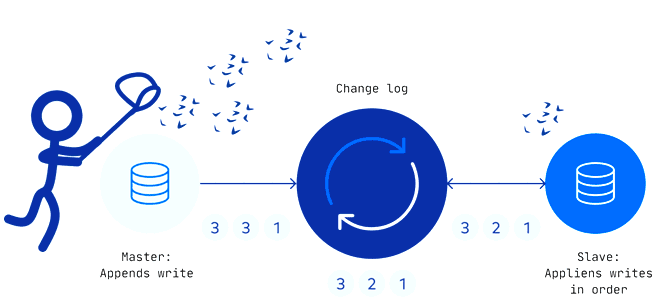
Захват измененных данных считается довольно известным паттерном организации ETL-процессов для корпоративных хранилищ и озер данных. Как реализуется CDC-технология, по каким шаблонам, что их ограничивает и чем опасен дрейф изменений в Change Data Capture. Паттерны и принципы реализации захвата измененных данных Эффективность эксплуатации озера данных зависит от ETL-процессов, поскольку объемы данных...

В этой статье рассмотрим настройку инфраструктуры Kubernetes для потоковой платформы комплексных мобильных приложений на основе Apache Kafka. Что поможет добиться оптимальной масштабируемости приложений-потребителей и высокой доступности всей Big Data системы. Проблемы масштабирования платформы Grab из приложений-потребителей Apache Kafka Grab считается ведущей платформой суперприложений в 8 странах Юго-Восточной Азии, которая предоставляет...

Сегодня рассмотрим, как оптимизировать потребление памяти в приложениях Apache Flink, разобрав основные принципы работы и конфигурации настройки памяти этого вычислительного фреймворка. А также перечислим типовые ошибки, с которыми дата-инженер может столкнуться при разработке и эксплуатации Flink-приложений Компоненты памяти в Apache Flink Apache Flink обеспечивает эффективные рабочие нагрузки поверх JVM, строго...
Мы уже писали о важности резервного копирования данных в Apache HBase на примере ИТ-компании Clairvoyant. Сегодня рассмотрим опыт индийской компании Myntra, которая предложила простую методику создания инкрементных бэкапов для Apache HBase 2.1.4 и Hadoop 2.7.3, а также восстановления нужных данных из этих резервных копий в BLOB-хранилищах по требованию пользователя. 5...

Что такое SQL-оператор VACUUM, зачем эта команда нужна в Greenplum и как она работает. Разбираемся с таблицами системного каталога и тонкостями ускорения SQL-запросов в самой популярной MPP-СУБД. Что такое сборка мусора в Greenplum и PostgreSQL Напомним, в объектно-реляционной базе данных PostgreSQL, на которой основана MPP-СУБД Greenplum, о чем мы писали...

Хотя Apache AirFlow считается достаточно зрелой платформой оркестрации рабочих процессов, при практическом использовании этого фреймворка дата-инженер может столкнуться с некоторыми сложностями. Одной из таких проблем являются так называемые «зомби-задачи». Разбираемся, чем они опасны, и как от них избавиться. Что такое зомби-задачи и чем они опасны В Unix-подобных операционных системах есть...
Помимо популярного MLflow от Databrics, специалисты по машинному обучению часто используют другой MLOps-инструмент – Kubeflow, о чем мы писали здесь. Сегодня разберем, как работает это средство, упрощающее разработку и развертывание конвейеров Machine Learning на платформе контейнерной виртуализации Kubernetes. Что такое конвейеры Kubeflow и как они работают Как мы уже отмечали,...
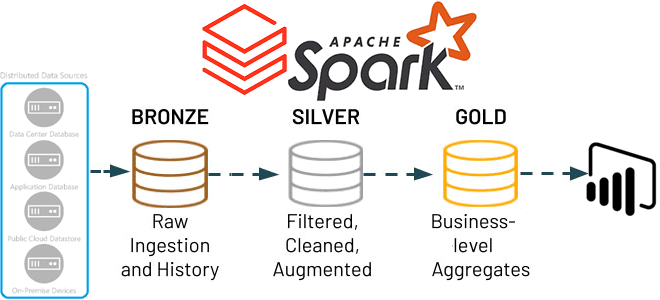
В этой статье для обучения дата-инженеров и ИТ-архитекторов рассмотрим, как Apache Spark Structured Streaming помогает реализовать самообслуживаемый сервис потоковой передачи данных в Delta Lake. А также вспомним каноническую 3-хслойную модель этого уровня хранения от Databricks. Много потоковых сценариев в одном приложении Apache Spark Structured Streaming Мы недавно писали, что архитектуры,...

Сегодня заглянем под капот Apache NiFi, чтобы понять, какие данные хранит этот потоковый ETL-маршрутизатор, зачем и где. Репозитории Apache NiFi для администратора, дата-инженера и проектировщика конвейеров обработки данных: как они устроены и какие практики улучшают их работу. Репозитории Apache NiFi: что это такое и зачем они нужны В Apache NiFi...

Зачем корпорации Confluent, которая продвигает Apache Kafka, понадобился Flink-стартап, чего ожидать от очередного слияния поглощения крупным игроком более мелкого предприятия, и какую пользу это принесет экосистеме потоковой передачи событий. Что Immerok и зачем это Confluent Год только начался, а в мире Big Data уже появились интересные новости. 6 января в...
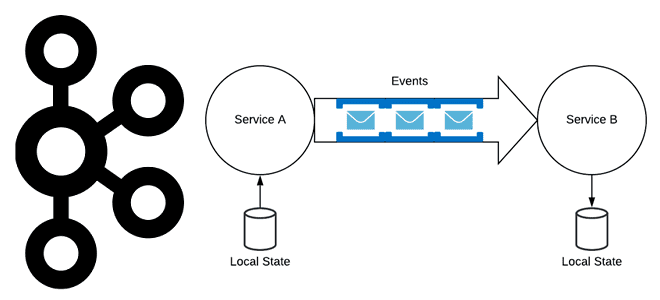
Хотя Apache Kafka часто используется в качестве шины обмена данными в микросервисной архитектуре, о чем мы писали здесь, не стоит воспринимать эту платформу как хранилище событий. В чем разница между событием и сообщением, а также другие тонкости построения микросервисной архитектуры, управляемой событиями. События vs сообщения Событие — это сообщение программной...

Использование СУБД вместо очереди сообщений считается антипаттерном, однако, команда разработки облачной системы организации конвейеров обработки данных Dagster Cloud выбрала PostgreSQL вместо Apache Kafka для регистрации событий. Разбираемся, почему плохой шаблон принес хорошие результаты и что нужно учитывать при выборе технологии. Почему не стоит использовать СУБД вместо очереди сообщений Dagster Cloud...