Как определить структуру Raw-слоя корпоративного хранилища данных: пример проектирования и DDL-скрипт для кейса электронной коммерции, выбор компонентов решения для архитектуры данных.
Постановка задачи: анализ систем-источников
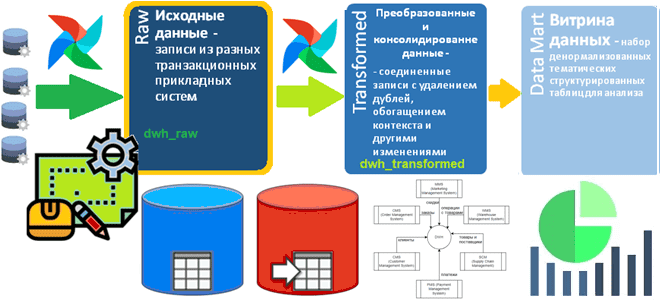
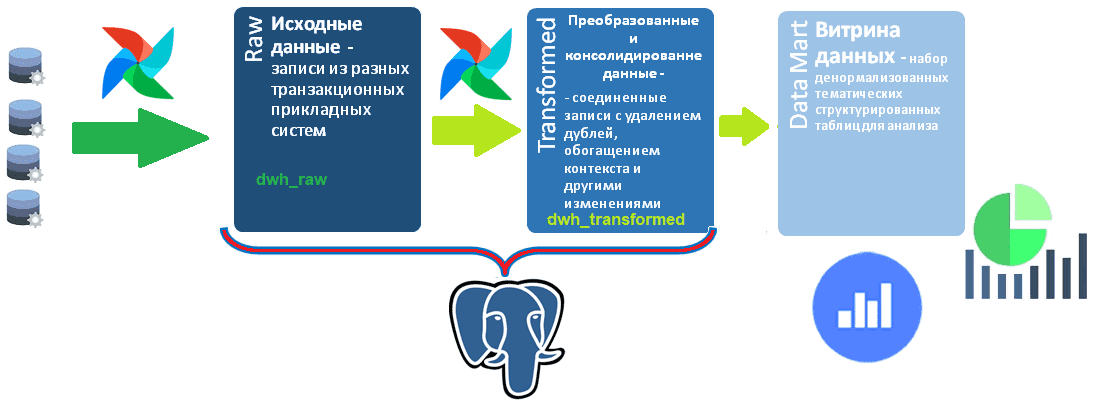
Сегодня корпоративные хранилища данных (DWH, Data Warehouse) обычно реализуются в виде нескольких баз данных, связанных ETL-процессами. Причем каждая из этих гомогенных или гетерогенных, т.е. на одной или разных платформах, баз данных представляет собой слой LSA-архитектуры (Layered Scalable Architecture). К примеру, Raw-слой с исходными данными, загруженными из разных источников, можно реализовать в Greenplum, поскольку эта реляционная СУБД на базе PostgreSQL поддерживает механизм массовой параллельной загрузки данных. Аналогично Transformed-слой с преобразованными, т.е. консолидированными записями тоже отлично реализуется в Greenplum. А для аналитики большого объема уже структурированных и нормализованных данных в реальном времени лучше подойдет витрина данных (Data Mart) в виде Clickhouse или вообще BI-системы: PowerBI, Qlick или облачные сервисы типа Yandex.Datalens.
Недавно я показывала, как спроектировать схему данных для Transformed-слоя DWH с помощью подхода Data Vault. Однако, чтобы наполнить этот слой, консолидировав и преобразовав данные, их сперва надо залить в Raw-слой из исходных систем.
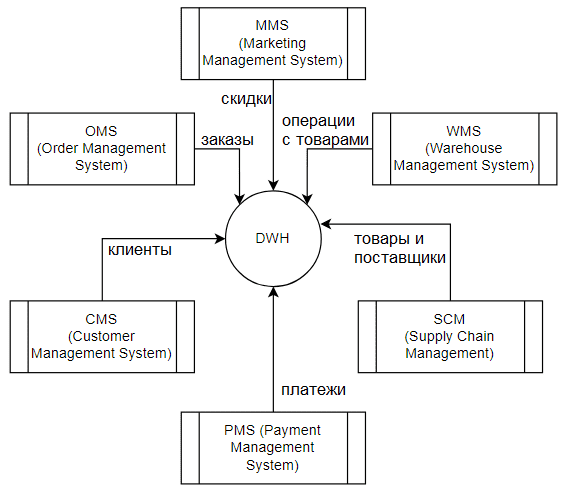
Как обычно, в качестве примера возьмем компанию электронной коммерции, которая использует несколько прикладных систем для своих бизнес-задач:
- MMS (Marketing Management System) – система управления скидками и маркетингом, которая содержит оперативные данные о программах лояльности: название, датах старта и окончания, товары, на которые распространяется скидка по программе лояльности и клиенты, к которым применима программа лояльности;
- OMS (Order Management System) – система управления заказами с данными о заказах (номер, дата и время, товары, сумма, покупатель и адрес доставки Покупатель), а также операции по изменению статуса заказа;
- WMS (Warehouse Management System) – система управления складом с данными о складских операциях с товаром и его локацией на конкретном складе;
- CMS (Customer Management System) – система управления клиентами с данными о клиентах (Email, Телефон, ФИО, дата рождения, статус) и клиентских обращениях (дата, тип, сотрудник, основание, результат);
- SCM (Supply Chain Management) – система управления цепочками поставок с данными по поставщикам (название, Email, Телефон, ИНН, адрес, счет) и товарам (название, единица измерения, категория, стоимость, поставщик, количество, дата поставки, дата годности);
- PMS (Payment Management System) – система управления платежами с данными по платежам: платежная система, тип платежа, счет отправителя, счет получателя, сумма, валюта, статус, назначение платежа.
Информация из всех этих транзакционных систем должна попасть в аналитическое хранилище.
Разумеется, схема данных в Raw-слое DWH будет отличаться от схемы в Transformed-слое, а также от исходной схемы в транзакционной системе. Например, в Raw-слое DWH данные из одного источника могут загружаться в одну или в пару таблиц, хотя в исходной OLTP-системе они сильно нормализованы и разнесены на гораздо большее число таблиц. Поскольку названия таблиц в Raw-слое будут использоваться в качестве значений для атрибута record_source в Transformed-слое хранилища данных, рекомендуется называть их тематически.
Практическая реализация Raw-слоя DWH
Для практического примера вместо Greenplum и Clickhouse возьму PostgreSQL для Raw- и Transformed-слоев проектируемого DWH, разместив их в разных схемах одной базы, а витрины данных сделаю с помощью облачной BI-системы Яндекса – сервиса DataLens.
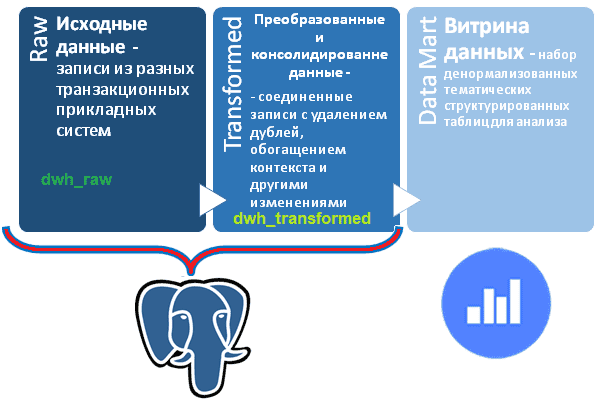
Схема данных для Transformed-слое DWH у меня уже разработана, но, чтобы залить в нее данные, они сперва должны оказаться в Raw-слое. Для Raw-слоя с учетом систем-источников я создала схему данных из нескольких несвязанных между собой таблиц.
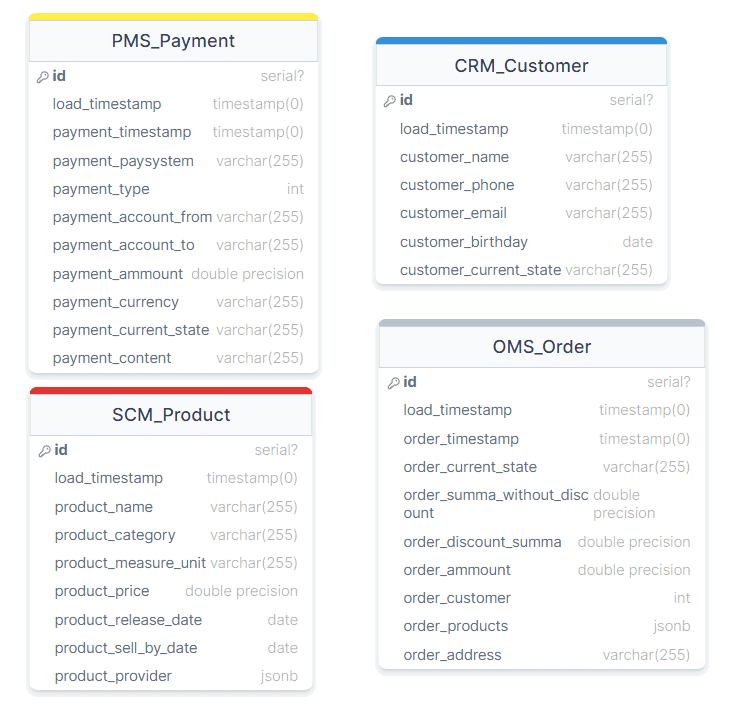
DDL-скрипт для созданных этих таблиц выглядит так:
CREATE SCHEMA IF NOT EXISTS dwh_raw;
CREATE TABLE dwh_raw.PMS_Payment(
id SERIAL PRIMARY KEY,
load_timestamp TIMESTAMP(0) WITHOUT TIME ZONE NOT NULL,
payment_timestamp TIMESTAMP(0) WITHOUT TIME ZONE NOT NULL,
payment_paysystem VARCHAR(255) NOT NULL,
payment_type INTEGER NOT NULL,
payment_account_from VARCHAR(255) NOT NULL,
payment_account_to VARCHAR(255) NOT NULL,
payment_ammount DOUBLE PRECISION NOT NULL,
payment_currency VARCHAR(255) NOT NULL,
payment_current_state VARCHAR(255) NOT NULL,
payment_content VARCHAR(255) NOT NULL
);
CREATE TABLE dwh_raw.CRM_Customer(
id SERIAL PRIMARY KEY,
load_timestamp TIMESTAMP(0) WITHOUT TIME ZONE NOT NULL,
customer_name VARCHAR(255) NOT NULL,
customer_phone VARCHAR(255) NOT NULL,
customer_email VARCHAR(255) NOT NULL,
customer_birthday DATE NOT NULL,
customer_current_state VARCHAR(255) NOT NULL
);
CREATE TABLE dwh_raw.OMS_Order(
id SERIAL PRIMARY KEY,
load_timestamp TIMESTAMP(0) WITHOUT TIME ZONE NOT NULL,
order_timestamp TIMESTAMP(0) WITHOUT TIME ZONE NOT NULL,
order_current_state VARCHAR(255) NOT NULL,
order_summa_wihout_discount DOUBLE PRECISION NOT NULL,
order_discount_summa DOUBLE PRECISION NOT NULL,
order_ammount DOUBLE PRECISION NOT NULL,
order_customer INTEGER NOT NULL,
order_products JSONB NOT NULL,
order_address VARCHAR(255) NOT NULL
);
CREATE TABLE dwh_raw.SCM_Product(
id SERIAL PRIMARY KEY,
load_timestamp TIMESTAMP(0) WITHOUT TIME ZONE NOT NULL,
product_name VARCHAR(255) NOT NULL,
product_category VARCHAR(255) NOT NULL,
product_measure_unit VARCHAR(255) NOT NULL,
product_price DOUBLE PRECISION NOT NULL,
product_release_date DATE NOT NULL,
product_sell_by_date DATE NOT NULL,
product_provider JSONB NOT NULL
);
Для практической работы с созданными таблицами необходимо реализовать ETL-процессы извлечения данных из систем-источников, их преобразования и загрузки в Raw-слой хранилища. Это можно сделать пакетным образом с помощью Apache AirFlow, написав соответствующий DAG с задачами извлечения, преобразования и загрузки данных. Разумеется, при этом надо определиться с периодичностью запуска этих пакетных заданий. Обычно такие ресурсоемкие операции как резервное копирование и выгрузка данных проводятся в периоды минимальной нагрузки, например, глубокой ночью, когда к базе данных обращается минимум пользователей. Для моего примера выгрузка данных будет выполняться 1 раз в час, причем последовательно: сперва в Raw-слой DWH, а затем в Transformed. Преобразованные и консолидированные данные, организованные в Transformed-слое согласно подходу Data Vault отлично подходят для создания тематических витрин данных и их визуализации на дэшбордах Yandex.Datalens. Как это сделать, я покажу в следующий раз.
Узнайте больше про архитектуры современных хранилищ данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, дата-инженеров, администраторов, аналитиков Big Data в Москве и специалистов по Data Science:

