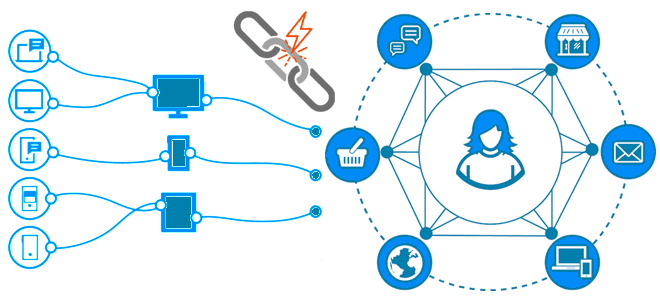
Как качество данных связано с разрешением сущностей, чем entity resolution отличается от identity resolution, зачем нужны графы идентичности, как их построить и где использовать. Борьба за качество данных с entity resolution Результаты аналитической обработки данных напрямую зависят от их качества, о ключевых показателях и задачах обеспечения которого мы писали здесь....
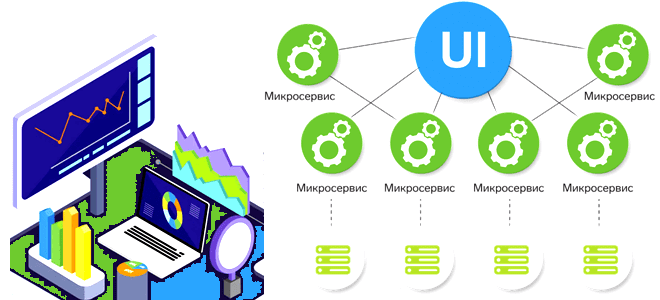
Сегодня разберем проблемы микросервисной архитектуры для платформ данных и способы их решения, а также вспомним 5 популярных шаблонов развертывания, которые могут смягчить риски от внедрения новых версий многокомпонентной системы. Проблемы микросервисной архитектуры для платформы данных и способы их решения При всех плюсах микросервисной архитектуры (автономность, гибкость, масштабируемость, простота развертывания, технологическая...

Что такое потоковая аналитика больших данных, какие бывают СУБД потоковой передачи, когда и зачем их использовать, а также что влияет на выбор этих инструментов хранения и аналитической обработки Big Data. Что такое потоковые базы данных и как они работают Мы уже упоминали, что аналитика данных в реальном времени может быть...
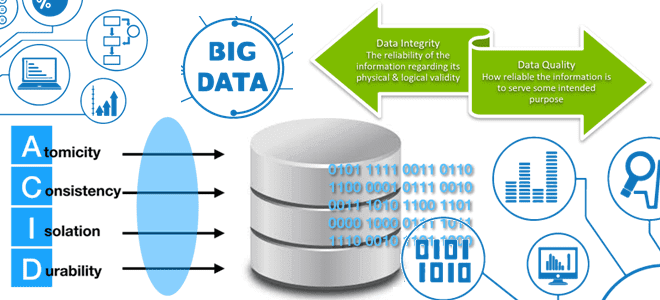
Чем целостность данных отличается от их качества и как реализуются ACID-свойства распределенных транзакций в Big Data системах. Разбираем понятия и технологии, важные для обучения ИТ-архитекторов и дата-инженеров. Целостность и качество данных: versus или вместе? Целостность данных и качество данных — связанные, но разные понятия, важные для дата-инженера. Целостность описывает точность...
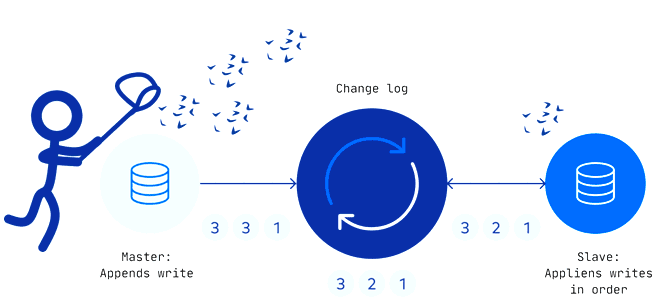
Захват измененных данных считается довольно известным паттерном организации ETL-процессов для корпоративных хранилищ и озер данных. Как реализуется CDC-технология, по каким шаблонам, что их ограничивает и чем опасен дрейф изменений в Change Data Capture. Паттерны и принципы реализации захвата измененных данных Эффективность эксплуатации озера данных зависит от ETL-процессов, поскольку объемы данных...
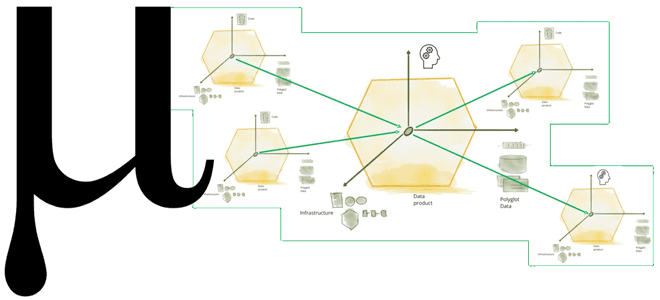
Что не так с конвейерной моделью обработки данных и почему архитектура Data Mesh с потоковой передачей событий не решают всех проблем пакетной парадигмы. Зачем нужна новая архитектура данных под названием Мю, какие инструменты и принципы она использует для устранения технологической неоднородности отдельных технологий Big Data, а также при чем здесь...
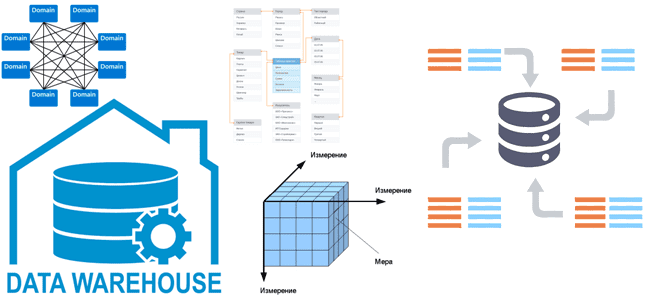
Все архитекторы DWH и многие дата-инженеры знакомы с идеями Ральфа Кимбалла, согласно которым хранилище данных — это сочетание множества различных витрин данных, облегчающих отчетность и анализ важных бизнес-показателей. Читайте далее, как реализовать этот подход при проектировании корпоративного хранилища данных и при чем здесь Data Mesh. КХД по Кимбаллу: доменные витрины...

Чтобы добавить в наши курсы для ИТ-архитекторов и дата-инженеров еще больше полезных материалов, сегодня рассмотрим, как модернизировать аналитические рабочие нагрузки в транзакционных системах с помощью гибридной архитектуры Data Mesh. А также поговорим о том, как реализовать этот подход с организационной и технической точек зрения. Аналитика и транзакции: versus или вместе?...

Сегодня рассмотрим тему анализа и оптимизации бизнес-процессов средствами графовой аналитики больших данных. Как устроены информационные системы класса Process Mining, где еще применяются эти идеи и другие приложения теории графов в бизнесе на примере Python-библиотеки PM4Py. Что такое Process Mining Чтобы понять, как выполняется процесс, бизнес-аналитик строит его схему в виде подробной EPC...

Data Mesh воплощает децентрализованный подход к построению распределенной архитектуры данных. При всех достоинствах этой модели, которая совмещает потоковую и пакетную парадигмы обработки данных, она еще довольно незрелая и имеет ряд недостатков. Одним из них является проблема с информационной безопасностью, что мы и рассмотрим далее для обучения ИТ-архитекторов и дата-инженеров. Безопасность...

Недавно мы рассматривали производительность ETL-конвейеров на Apache Spark с озером данных на MinIO. Сегодня разберем, чем это легковесное объектное хранилище отличается от распределенной файловой системы Apache Hadoop и как перейти на него с HDFS. Зачем переходить на MinIO Хотя HDFS до сих пор активно используется во многих Big Data проектах...
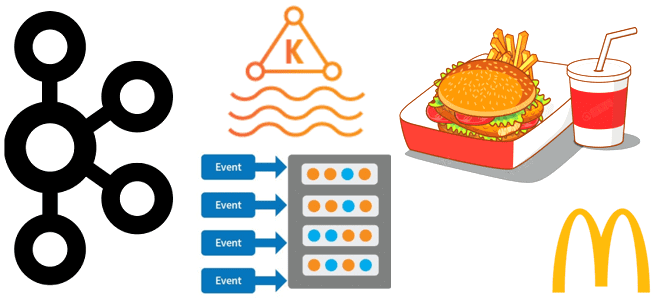
Сегодня заглянем под капот ИТ-инфраструктуры самой знаменитой франшизы быстрого питания. Как устроена унифицированная платформа потоковой обработки событий в McDonald’s на базе облачного полностью управляемого сервиса Apache Kafka в AWS и что гарантирует высокую доступность и надежность решения. Архитектурный дизайн Архитектуры, основанные на событиях, обеспечивают гибкость интеграции, масштабируемость и некоторые возможности...

Чтобы добавить в наши курсы для ИТ-архитекторов и дата-инженеров еще больше практических примеров, сегодня разберем ключевые требования к современному озеру данных и самые последние тренды в аналитике Big Data. Что такое DaaS, зачем это нужно и каковы риски. 7 преимуществ развертывания Data Lake в облаке При том, что Data Lake...
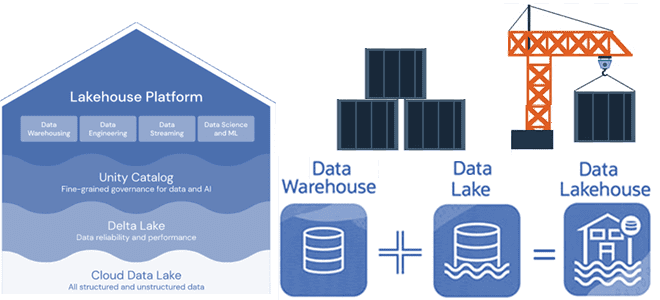
Недавно мы писали про новую гибридную архитектуру Lakehouse, которая объединяет лучше из мира озер и хранилищ данных. Сегодня разберем принципы работы и особенности построения этой архитектуры данных, включая технологии ее реализации с точки зрения дата-инженера и уделим внимание организации конвейеров аналитики больших данных. Архитектурная парадигма Lakehouse Напомним, Lakehouse — это...

В этой статье для обучения дата-инженеров и архитекторов распределенных систем рассмотрим, что такое наблюдаемость, как ее измерить и при чем здесь стандарт OpenTelemetry. А в качестве примера разберем, как французский маркетплейс Cdiscount управляет почти 1000 микросервисов в кластере Kubernetes с Apache Kafka, Jaeger, Elasticsearch и OpenTelemetry. Наблюдаемость распределенной системы: стандарт...
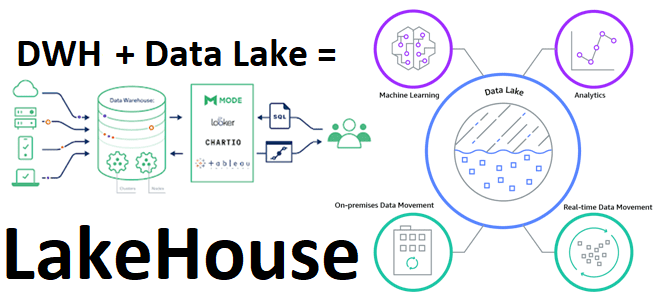
В рамках обучения дата-инженеров и архитекторов корпоративных платформ и приложений аналитики больших данных, сегодня рассмотрим, что такое LakeHouse. Как эта новая гибридная архитектура управления данными объединяет 2 разнонаправленные парадигмы хранения информации, а также чего от нее ожидают бизнес-пользователи, дата-инженеры, аналитики и ML- специалисты. Историческая справка: от DWH к Data Lake...
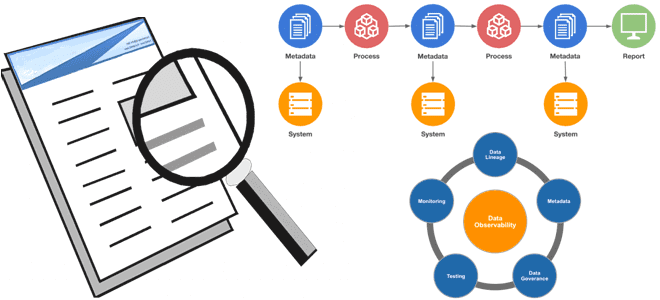
Сегодня рассмотрим, почему наблюдаемость данных так важная для проектов Big Data, какие компоненты обеспечивают ценную информацию о качестве и надежности данных, чем это похоже на DataOps, а также как эти идеи реализовать на практике с использованием популярных инструментов современной дата-инженерии. Почему важна наблюдаемость данных Цифровизация предполагает управление на основе качественных...

В недавней статье про современные архитектуры данных мы упоминали Data Fabric и Data Mesh. Сегодня поговорим про эти стратегии Data Governance более подробно: разберем их главные достоинства и недостатки, основные сходства и принципиальные отличия, ключевые вызовы и технологии реализации, а также возможности совместного применения на практике. Что такое Data Fabric...

Мы уже рассказывали о победителях российского ИТ-конкурса «Проект Года 2020» от профессионального сообщества GlobalCIO в номинации «Аналитика и Big Data», где «Газпром нефть» и банк ВТБ делятся опытом применения российских продуктов Arenadata. Сегодня рассмотрим кейс призера 2021 года - проект «Фабрика данных» в АО «Народный банк Казахстана», в результате которого...

Сегодня разберем кейс компании Renault по масштабированию своей цифровой платформы и снижению затрат с помощью BigQuery и Apache Spark на Google Dataproc. Цифровизация в автомобильной промышленности: конвейер сбора и аналитики больших данных с производства средствами Google сервисов и снижение затрат на облако в 2 раза через изменение конфигурации Spark SQL....