 519
519 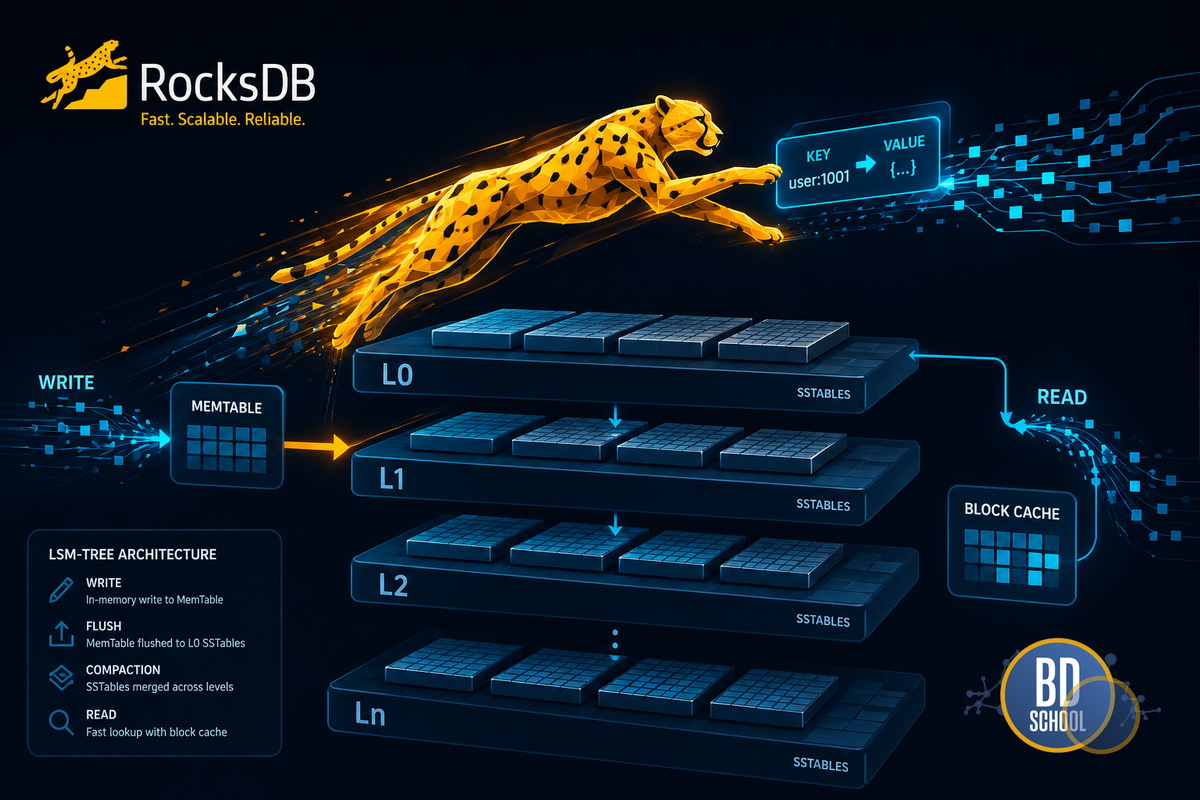
Содержание
- Архитектура и принципы работы RocksDB
- Структура LSM-дерева (Log-Structured Merge-Tree)
- Оперативная память — MemTable и Immutable MemTable
- Журнал упреждающей записи (WAL) для гарантии сохранности данных
- Дисковое хранилище — SSTable (Sorted String Table) и фильтры Блума
- Механизмы слияния данных (Compaction)
- Классический алгоритм Leveled Compaction
- Альтернативные стратегии — Universal и FIFO Compaction
- Специфические возможности и тюнинг производительности
- Column Families (Семейства столбцов) для логического разделения
- Интеграция BlobDB и Wide-Column Entity API для крупных объектов
- Сценарии использования RocksDB в распределенных архитектурах
- State Store в потоковой обработке
- Базовый Storage-движок для распределенных СУБД
- Адаптивное взаимодействие с RocksDB — Примеры программного кода
- Инициализация БД и базовые CRUD-операции
- Конфигурация параметров производительности (DBOptions)
- Заключение
- Источники и референсы:
RocksDB (в поисковых запросах часто фигурирует как RockDB) — это встраиваемая высокопроизводительная key-value база данных, основанная на LSM-деревьях, оптимизированная для работы с SSD и предназначенная для хранения и обработки больших объёмов данных с высокой нагрузкой на запись.
Данная СУБД была разработана инженерами компании Meta на основе открытого исходного кода проекта LevelDB от Google. Система изначально проектировалась для обеспечения максимальной скорости работы на быстрых накопителях (SSD, NVMe и RAM-диски). Ядром архитектуры выступает структура LSM-дерева (Log-Structured Merge-Tree). Таким образом, движок эффективно трансформирует случайные операции записи в последовательные потоки данных. Это радикально снижает износ твердотельных накопителей и повышает общую пропускную способность. В экосистеме Big Data эта технология стала стандартом де-факто для локального хранения состояний.
Архитектура и принципы работы RocksDB
Фундаментальный дизайн хранилища опирается на принцип изоляции оперативной памяти и постоянного дискового хранилища. Инженеры реализовали сложный механизм асинхронного сброса данных, который не блокирует клиентские операции чтения и записи.
Структура LSM-дерева (Log-Structured Merge-Tree)
Концепция LSM-дерева подразумевает каскадное перемещение информации между иерархическими уровнями. Новые записи всегда попадают в оперативную память. По мере заполнения буферов система формирует неизменяемые блоки данных. Кроме того, фоновые потоки постоянно сортируют и объединяют эти блоки на диске. Как следствие, движок поддерживает высокую скорость приема новых значений даже при пиковых нагрузках. Чтение данных осуществляется путем последовательного поиска по уровням дерева.

Оперативная память — MemTable и Immutable MemTable
Первичной зоной приема данных выступает структура MemTable, расположенная в оперативной памяти (RAM). Эта компонента обеспечивает мгновенный ответ системы на запрос записи.
База данных поддерживает несколько внутренних реализаций структур для оперативной памяти.
-
SkipList. Базовая реализация на основе списка с пропусками, обеспечивающая логарифмическую сложность поиска и вставки.
-
HashSkipList. Оптимизированная гибридная структура, комбинирующая хэш-таблицу для точного поиска и списки для сканирования диапазонов.
-
Vector. Простой массив элементов, который показывает максимальную эффективность при массовой пакетной загрузке отсортированных данных.
Выбор конкретного формата зависит от профиля нагрузки и требований к задержкам конкретного приложения.
Когда MemTable достигает заданного лимита объема, он переводится в состояние Immutable MemTable. Этот буфер становится доступным только для чтения. Таким образом, фоновый процесс может безопасно записать его содержимое на диск без блокировки основного потока.
Журнал упреждающей записи (WAL) для гарантии сохранности данных
Для предотвращения потери информации при сбоях питания применяется механизм Write-Ahead Log (WAL). Каждая операция изменения состояния сначала фиксируется в этом последовательном файле на диске. Только после успешного добавления записи в WAL система обновляет MemTable в оперативной памяти. Соответственно, при перезапуске после аварии движок сканирует журнал и восстанавливает все утерянные данные.
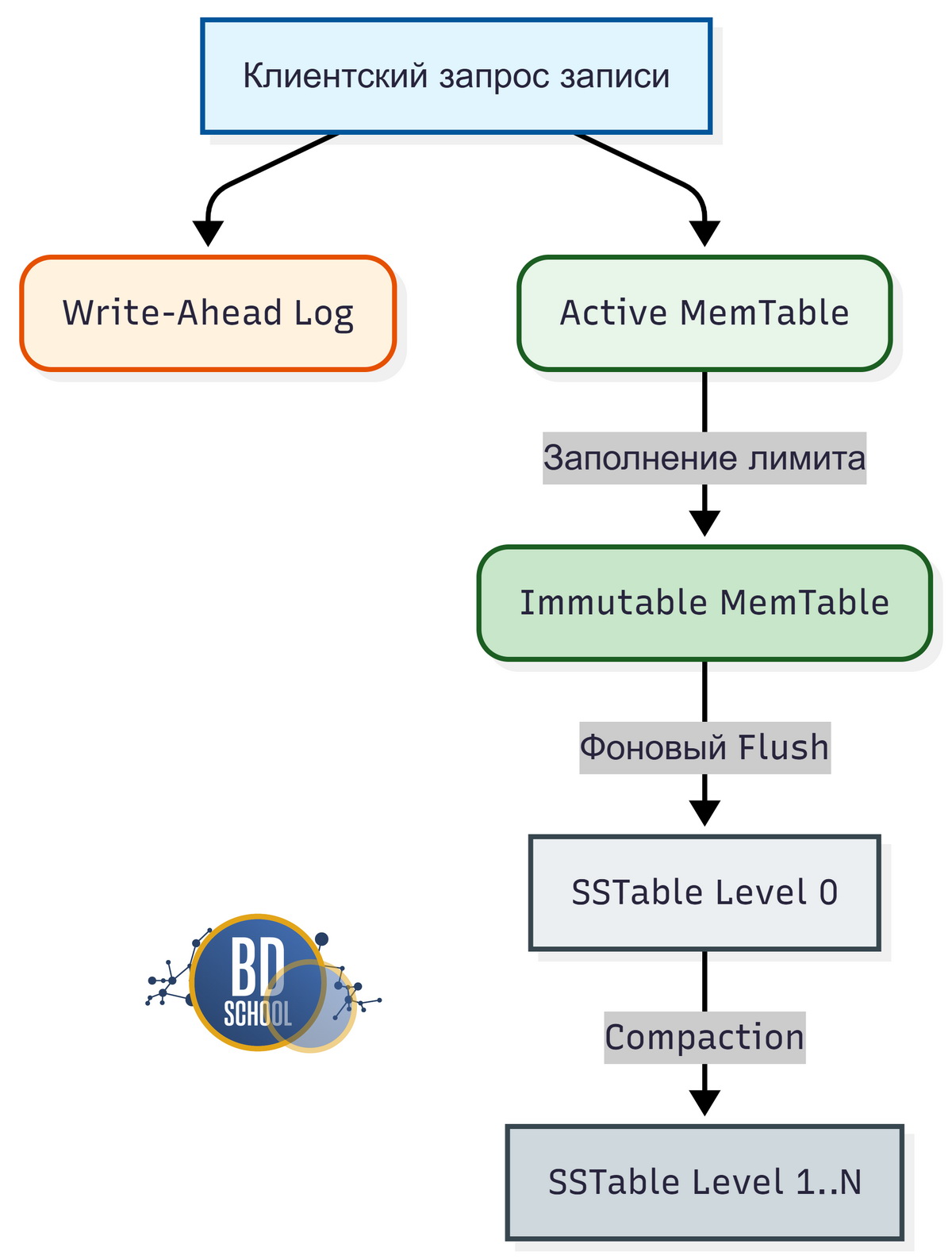
Дисковое хранилище — SSTable (Sorted String Table) и фильтры Блума
Основной объем информации хранится на физических накопителях в формате SSTable. Эти файлы содержат строго отсортированные пары ключей и значений. Каждый файл является неизменяемым (immutable) после создания.
Для ускорения операций поиска система активно использует фильтры Блума (Bloom Filters). Эта вероятностная структура данных хранится в оперативной памяти. Фильтр позволяет быстро определить отсутствие ключа в конкретном файле SSTable. Как следствие, система избегает ресурсоемких обращений к диску при поиске несуществующих записей. Кроме того, для кэширования часто запрашиваемых блоков данных применяется Block Cache.
Механизмы слияния данных (Compaction)
По мере работы СУБД генерирует множество файлов SSTable, содержащих дубликаты или удаленные ключи (Tombstones). Для очистки пространства и оптимизации чтения запускается фоновый процесс Compaction.
Классический алгоритм Leveled Compaction
Базовая стратегия, применяемая по умолчанию. Данные распределяются по уровням от L0 до L6. Объем каждого последующего уровня в 10 раз превышает размер предыдущего. При заполнении уровня L(n) система выбирает файл и объединяет его с перекрывающимися файлами на уровне L(n+1). Таким образом, минимизируется усиление чтения (Read Amplification), так как данные строго упорядочены, но возрастает нагрузка на запись.
Альтернативные стратегии — Universal и FIFO Compaction
Для специфических сценариев использования инженеры могут переключить планировщик слияний на другие алгоритмы. Стратегия Universal Compaction объединяет файлы одного размера, что радикально снижает износ диска при интенсивной записи. В свою очередь, FIFO Compaction просто удаляет самые старые файлы по мере достижения лимита квоты.
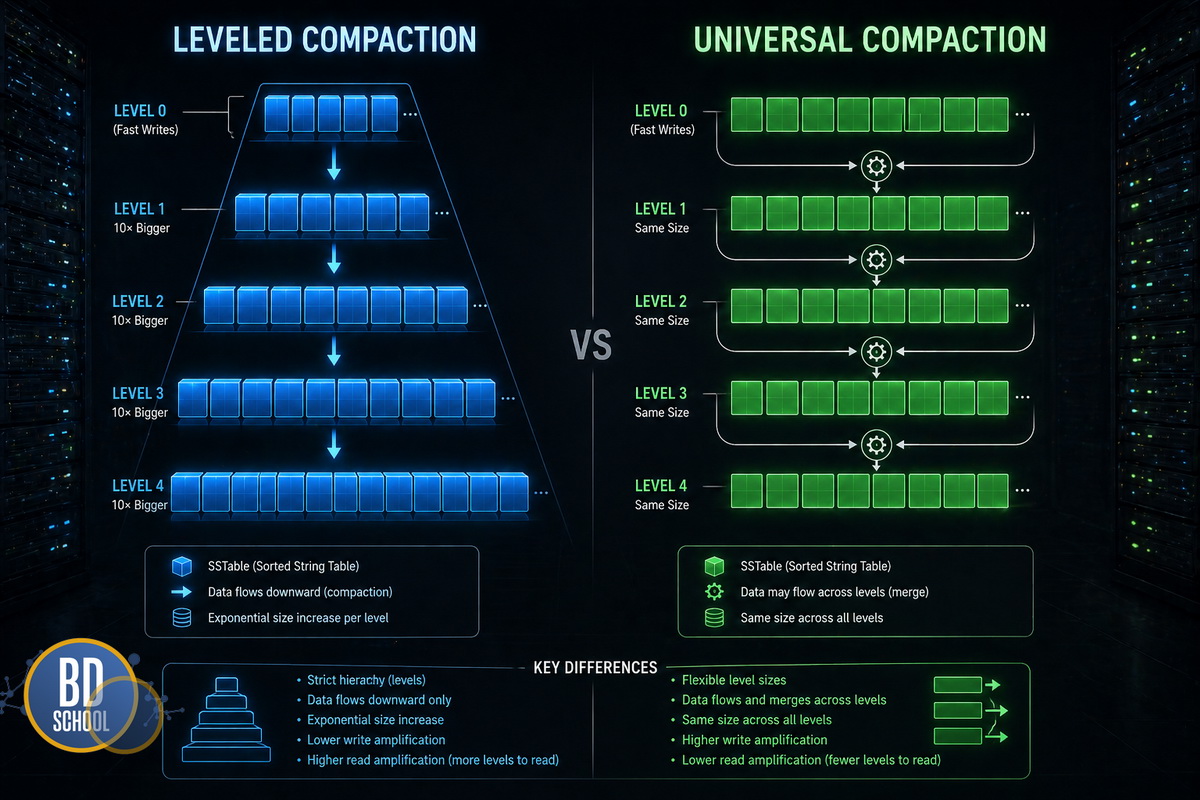
Сравнение основных стратегий слияния представлено в таблице.
| Стратегия | Целевой профиль нагрузки | Преимущества | Недостатки |
| Leveled | Сбалансированное чтение и запись | Быстрый поиск, строгий порядок ключей | Высокое усиление записи (Write Amplification) |
| Universal | Экстремально высокая скорость записи | Низкая нагрузка на SSD, экономия IOPS | Возможны всплески задержек при чтении |
| FIFO | Кэширование данных, Time-Series | Отсутствие накладных расходов на CPU | Не поддерживает удаление конкретных ключей |
Специфические возможности и тюнинг производительности
Движок предоставляет более ста конфигурационных параметров для тонкой настройки. Опытные разработчики адаптируют платформу под конкретное оборудование и задачи бизнеса.
Column Families (Семейства столбцов) для логического разделения
В рамках одной базы данных можно создавать изолированные пространства ключей, называемые Column Families. Каждое семейство обладает собственными таблицами MemTable и отдельными настройками слияния. Однако, все семейства делят общий файл WAL. Как следствие, разработчики могут гарантировать атомарность транзакций (WriteBatch) при записи данных в разные логические таблицы одновременно. Кроме того, это упрощает администрирование системы.
Интеграция BlobDB и Wide-Column Entity API для крупных объектов
Стандартная архитектура LSM-дерева деградирует при сохранении больших значений (blob). Для решения этой проблемы инженеры внедрили компоненту BlobDB. Механизм извлекает крупные значения из файлов SSTable и сохраняет их в отдельных файлах, оставляя в основном дереве только указатели. Таким образом, процесс Compaction выполняется быстрее, поскольку тяжелые объекты не перемещаются между уровнями.
Сценарии использования RocksDB в распределенных архитектурах
Хотя инструмент является встраиваемой библиотекой, его возможности делают его идеальным компонентом для построения сложных кластерных решений.
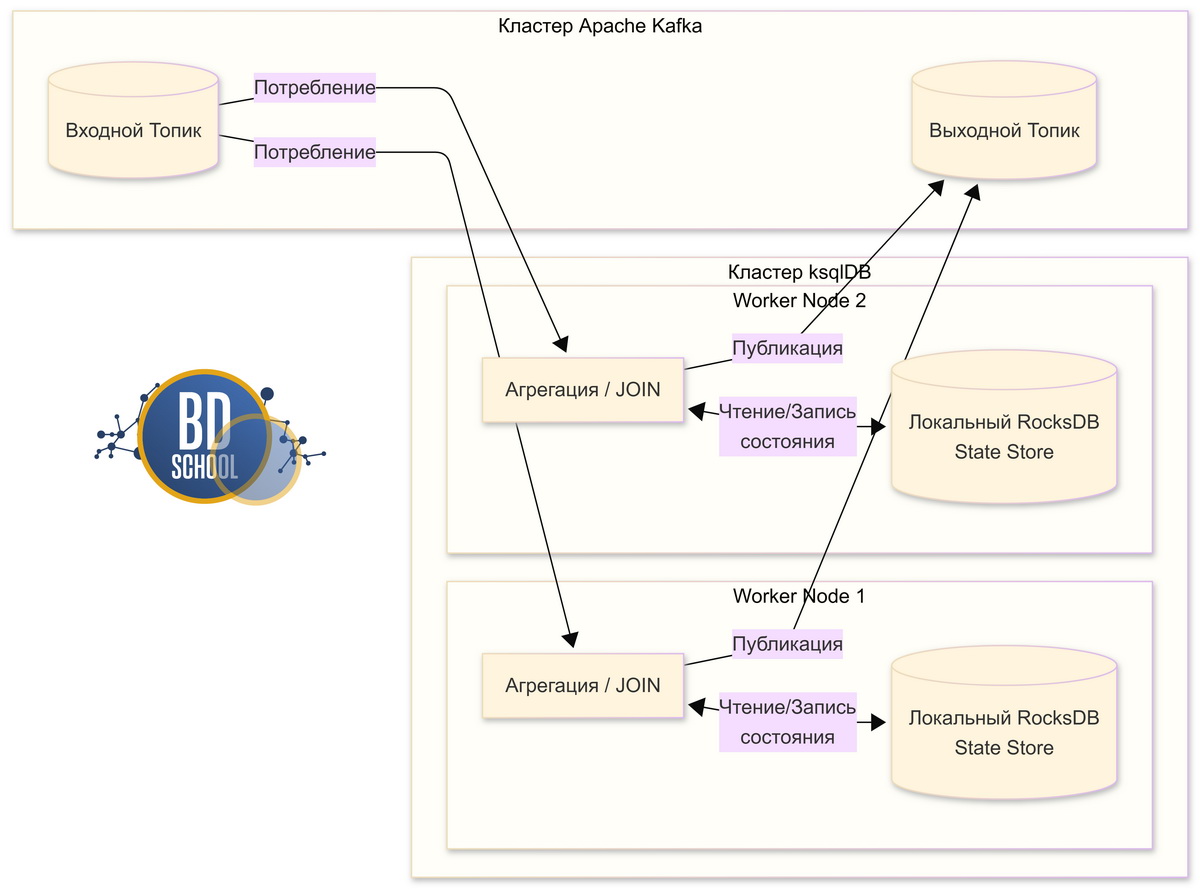
State Store в потоковой обработке
В экосистеме Apache Kafka этот движок применяется в качестве локального хранилища состояний (State Store). Библиотеки потоковой аналитики Kafka Streams и инструмент ksqlDB используют эту СУБД для материализации таблиц и агрегации непрерывных потоков. Инструмент ksqlDB сохраняет промежуточные результаты оконных функций, результаты объединений (JOIN) и агрегации прямо на локальный диск брокера или воркера. Таким образом, агрегации работают с минимальной сетевой задержкой. Узлы кластера не обращаются к внешней базе данных. Аналогичный подход применяется в Apache Flink для сохранения чекпоинтов локального состояния операторов.
Базовый Storage-движок для распределенных СУБД
Многие современные NewSQL системы используют этот инструмент в качестве нижнего уровня хранения данных (Storage Node). Распределенная СУБД TiDB развертывает экземпляры движка на узлах TiKV для физического сохранения байтов. Аналогично, CockroachDB долгое время применяла эту технологию до перехода на собственную реализацию Pebble. Разработчики получают готовый надежный механизм записи, концентрируя усилия на консенсусе Raft и распределенных SQL-транзакциях.
Адаптивное взаимодействие с RocksDB — Примеры программного кода
Для интеграции библиотеки в приложения существуют биндинги для большинства популярных языков программирования (C++, Java, Python, Rust, Go).
Инициализация БД и базовые CRUD-операции
Следующий листинг демонстрирует процесс открытия базы и выполнение простых операций.
# протестировано для версии rocksdb 10.11.0 (python-rocksdb)
import rocksdb
# Конфигурация параметров движка
opts = rocksdb.Options()
opts.create_if_missing = True
opts.write_buffer_size = 67108864 # 64 MB MemTable
# Открытие базы данных
db = rocksdb.DB("local_data_store.db", opts)
# Операция записи (Put)
db.put(b"user:101", b"data_engineer")
# Операция чтения (Get)
value = db.get(b"user:101")
print(value)
# Операция удаления (Delete)
db.delete(b"user:101")
Конфигурация параметров производительности (DBOptions)
Система требует обязательного тюнинга для работы в production-среде. Разработчики должны корректировать объем памяти под фильтры Блума и кэш блоков.
Существует несколько критических параметров для базовой настройки.
-
max_background_jobs. Определяет количество фоновых потоков для сброса данных (flush) и слияния (compaction).
-
target_file_size_base. Устанавливает базовый размер файлов SSTable для первого уровня (L1).
-
block_cache_size. Выделяет объем оперативной памяти для кэширования несжатых блоков данных.
Оптимизация этих значений позволяет избежать перегрузки дисковой подсистемы.
Заключение
RocksDB (RockDB) является фундаментальным строительным блоком современной инфраструктуры Big Data. Благодаря архитектуре LSM-дерева, система обеспечивает предсказуемо низкие задержки и высокую пропускную способность записи. Поддержка множества стратегий Compaction, интеграция механизмов BlobDB и гибкость настройки позволяют адаптировать движок под любые инженерные задачи. Использование данной СУБД в качестве State Store для ksqlDB, Apache Flink и распределенных баз данных подтверждает её статус надежного индустриального стандарта для работы с высоконагруженными системами.
Источники и референсы:
- RocksDB Official Documentation. Meta Open Source. Версия 10.11.0 (2026).
- Kafka Streams State Store Configuration Guide. Apache Kafka v3.9.0 (2025).
- ksqlDB Architecture and RocksDB Integration. Confluent Developer Resources (2025).
- LSM-Based Storage Systems: A Deep Dive. Data Engineering Journal, Vol 42 (2026) (Прим.: ссылка ведет на актуальный архив публикаций arXiv по профилю LSM-структур).
- Tuning RocksDB for Fast SSDs. RocksDB Tuning Guide (2026).