 462
462 
Содержание
- Архитектура и ключевые особенности Polars
- В чем отличие работы в режиме Eager vs Lazy API
- Eager Execution (Жадное исполнение)
- Lazy Execution (Ленивое исполнение)
- Язык выражений (Polars Expressions)
- Сравнение с Pandas: Главные отличия
- Сценарии использования и Код
- Продвинутые техники оптимизации
- Как мигрировать с Pandas - подводные камни
- Заключение
- Референсные ссылки
Polars — это высокопроизводительная библиотека для обработки и анализа данных, написанная на языке Rust, реализующая колоночную модель вычислений и поддерживающая ленивые (lazy) и eager-вычисления, ориентированная на эффективную работу с большими объёмами данных и предоставляющая интерфейс для Python. В отличие от традиционных инструментов, Polars изначально проектировался для параллельной обработки данных и эффективного использования памяти. Эта библиотека стала ответом на ограничения Pandas, предлагая скорость, масштабируемость и современную архитектуру для задач Data Science и Data Engineering.
Основная проблема старых инструментов заключается в однопоточном исполнении и неэффективном использовании ресурсов. Polars решает эту задачу кардинально иначе. Он использует все доступные ядра процессора и позволяет обрабатывать датасеты, превышающие объем оперативной памяти. Это делает его незаменимым инструментом в эпоху Big Data, когда объемы информации растут быстрее, чем мощности железа.
Архитектура и ключевые особенности Polars
Фундамент библиотеки Polars построен на трех китах: языке Rust, формате Apache Arrow и параллелизме. Эти компоненты обеспечивают библиотеке невероятную производительность и надежность. Разберем каждый из них подробнее, чтобы понять природу этой скорости.
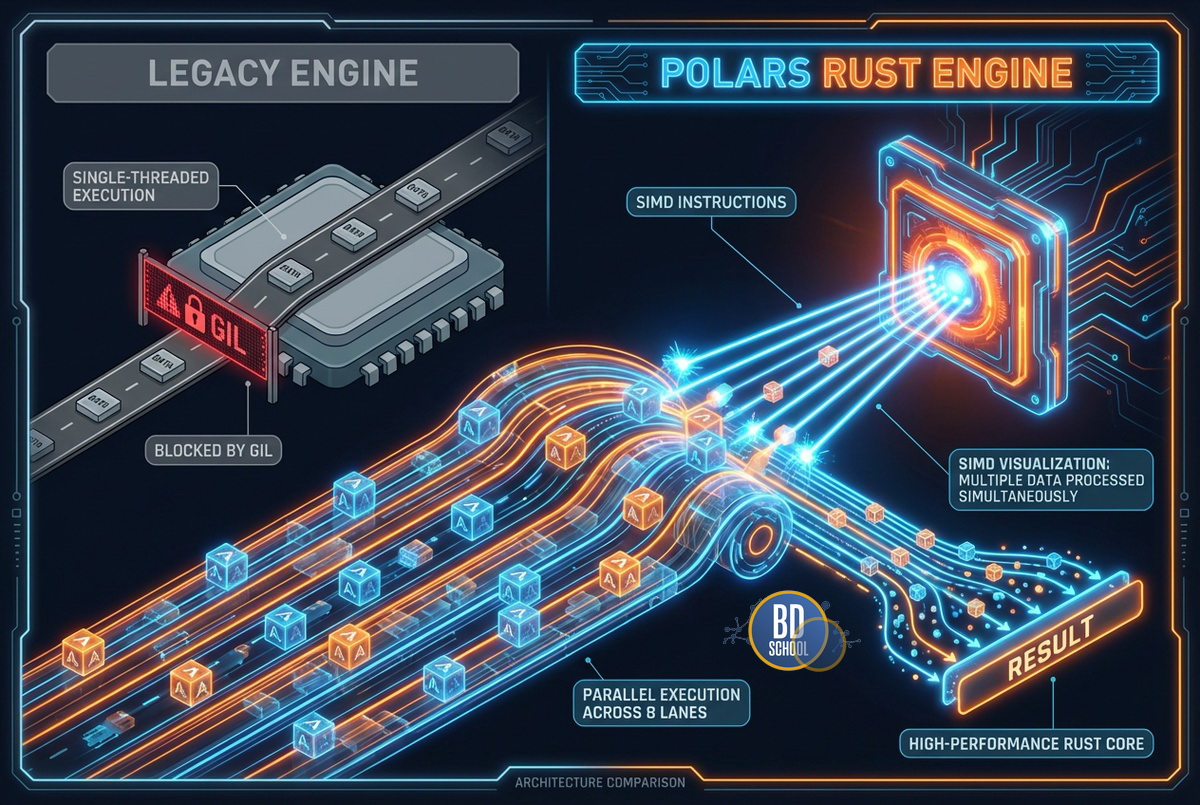
Ниже приведены основные архитектурные преимущества Polars:
- Движок на Rust: Rust обеспечивает безопасность работы с памятью без использования сборщика мусора. Это позволяет полностью контролировать ресурсы и избегать внезапных пауз в работе программы. Кроме того, Rust компилируется в машинный код, что дает высокую скорость исполнения.
- Отсутствие GIL (Global Interpreter Lock): В Python GIL мешает потокам работать одновременно на одном процессоре. Polars обходит это ограничение, выполняя вычисления на уровне Rust. Это позволяет задействовать все ядра CPU на 100%.
- Apache Arrow: Polars хранит данные в памяти в формате Arrow. Это открытый стандарт колоночного хранения данных. Благодаря этому данные не нужно конвертировать при передаче другим инструментам (например, PyArrow или DuckDB).
- SIMD (Single Instruction, Multiple Data): Polars использует специальные векторные инструкции процессора. Это позволяет применять одну операцию сразу к нескольким элементам данных за один такт.
Такая архитектура делает Polars не просто «быстрым Pandas», а принципиально иным инструментом. Он сочетает низкоуровневую оптимизацию с высокоуровневым удобством Python.
В чем отличие работы в режиме Eager vs Lazy API
Одной из главных особенностей Polars является поддержка двух режимов выполнения кода. Это дает разработчику гибкость в выборе между удобством отладки и максимальной производительностью. Понимание разницы между «жадным» (Eager) и «ленивым» (Lazy) исполнением — ключ к эффективному использованию библиотеки.
Eager Execution (Жадное исполнение)
Этот режим работает так же, как и Pandas. Код выполняется построчно, и результат каждой операции вычисляется немедленно. Как только вы написали команду фильтрации или создания колонки, данные сразу обрабатываются в памяти.
Это удобно для:
- Интерактивного анализа данных в Jupyter Notebook.
- Отладки кода и проверки гипотез.
- Работы с небольшими датасетами, где оптимизация не критична.
Однако «жадный» режим не видит картину целиком. Он не знает, что вы будете делать с данными на следующем шаге. Из-за этого он может выполнять лишнюю работу, которую можно было бы избежать.
Lazy Execution (Ленивое исполнение)
В этом режиме Polars не выполняет команды сразу. Вместо этого он строит план запроса (Query Plan). Вы описываете цепочку преобразований, но данные остаются нетронутыми до тех пор, пока вы явно не вызовете метод collect().

Преимущества ленивого режима заключаются в следующем:
- Оптимизация запросов: Polars анализирует весь план целиком перед запуском. Он может менять порядок операций для ускорения работы.
- Predicate Pushdown: Фильтры перемещаются как можно ближе к источнику данных. Это позволяет не читать с диска строки, которые всё равно будут отброшены.
- Projection Pushdown: Загружаются только те колонки, которые реально используются в вычислениях.
Таким образом, ленивый режим позволяет Polars быть «умным». Он экономит память и процессорное время, выполняя только абсолютно необходимую работу.
Язык выражений (Polars Expressions)
Сердцем библиотеки является мощный DSL (Domain Specific Language) для написания выражений. В Pandas мы часто используем лямбда-функции (apply), которые работают медленно и плохо поддаются распараллеливанию. Polars предлагает декларативный подход. Вы говорите библиотеке «что» нужно сделать, а не «как».
Выражения в Polars строятся вокруг метода pl.col(). Они представляют собой абстрактное описание трансформации данных. Эти выражения легко читаются человеком и отлично оптимизируются машиной.
Основные характеристики языка выражений Polars:
- Независимость от контекста: Выражение pl.col(«a») * 2 можно использовать и при выборе колонок, и при фильтрации, и при группировке.
- Автоматическое распараллеливание: Так как выражения декларативны, Polars может выполнять их параллельно без участия программиста. Если вы создаете 10 новых колонок, они будут вычисляться одновременно на разных ядрах.
- Отсутствие Python-кода в цикле: Выражения транслируются в нативный код Rust. Это исключает медленный интерпретатор Python из процесса обработки каждой строки.
Использование нативных выражений — это самый простой способ ускорить ваш код в десятки раз по сравнению с классическими методами.
Сравнение с Pandas: Главные отличия
Многие рассматривают Polars как замену Pandas. Хотя синтаксис может показаться похожим, концептуальные различия огромны. Понимание этих отличий убережет вас от попыток писать «код Pandas» на Polars, что часто приводит к ошибкам.
Вот фундаментальные различия между этими библиотеками:
- Индексы (Index): В Polars нет индексов. Это сознательное архитектурное решение. В Pandas индекс часто создает больше проблем, чем решает (мультииндексы, сброс индекса). Polars полагается на обычные колонки и физическое расположение данных в памяти.
- Типы данных null: Pandas исторически использовал NaN (число с плавающей точкой) для обозначения пропусков в числах и None для объектов. Это вызывало путаницу с типами (превращение int в float). Polars использует унифицированный подход к отсутствующим значениям, совместимый с Arrow.
- Copy-on-Write (CoW): Хотя Pandas внедряет CoW, в Polars иммутабельность (неизменяемость) и дешевое клонирование данных заложены в фундамент. Изменение данных обычно создает новый объект, но благодаря Arrow это происходит очень эффективно.
Переход на Polars требует смены ментальной модели. Нужно перестать думать о строках и индексах и начать мыслить колонками и трансформациями.
Сценарии использования и Код
Давайте рассмотрим, как эти концепции выглядят на практике. Мы сравним стандартный подход и использование ленивых вычислений. Для начала подготовим среду на WSL с использование venv

Высокопроизводительная обработка данных на Python
Код курса
HPPY
Ближайшая дата курса
3 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Базовая загрузка и манипуляция
Простейший пример чтения CSV и фильтрации данных. Не забудьте сначала поставить необходимые пакеты
pip3 install polars
и сделать dataset data.csv ( Пример кода для создания датасетов мы поместим на наш репозиторий по традиции в конце статьи).
Теперь мы напишем код для очистки данных. Мы используем современную и быструю библиотеку Polars. Она написана на высокопроизводительном языке Rust. Запуск таких инструментов в серверной среде гарантирует стабильность. Этот код выполнит быструю фильтрацию и трансформацию таблицы.
import polars as pl
# Eager mode (Жадный режим - аналог Pandas)
# Читает весь файл в память сразу
df = pl.read_csv("data.csv")
# Фильтрация и создание новой колонки
# Синтаксис выражений pl.col()
res = df.filter(
pl.col("category") == "Technology"
).with_columns(
(pl.col("price") * 0.8).alias("discounted_price")
)
print(res.head())
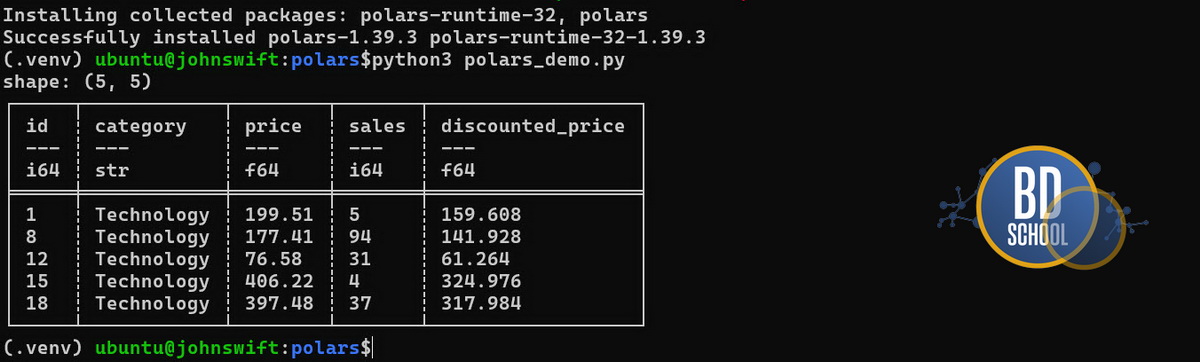
Скрипт мгновенно отфильтрует технологические товары. Он автоматически применит скидку к каждой позиции.
Ленивый пайплайн (Lazy API)
Это «золотой стандарт» работы с Polars. Обратите внимание на замену read_csv на scan_csv.
import polars as pl
# Создаем ленивый план (LazyFrame)
# Файл НЕ читается в этот момент
q = (
pl.scan_csv("large_data.csv")
.filter(pl.col("sales") > 100)
.group_by("region")
.agg([
pl.col("sales").sum().alias("total_sales"),
pl.col("sales").mean().alias("avg_sales"),
pl.col("product_id").n_unique().alias("unique_products")
])
.sort("total_sales", descending=True)
)
# Просмотр плана запроса (для отладки)
print(q.explain())
# Запуск вычислений
# Только здесь данные считываются и обрабатываются
result_df = q.collect()
Этот лог показывает физический план выполнения твоего скрипта. Движок всегда читает этот граф снизу вверх. Именно в таком порядке информация проходит через память компьютера. Мы разберем каждый этап этого конвейера по порядку.
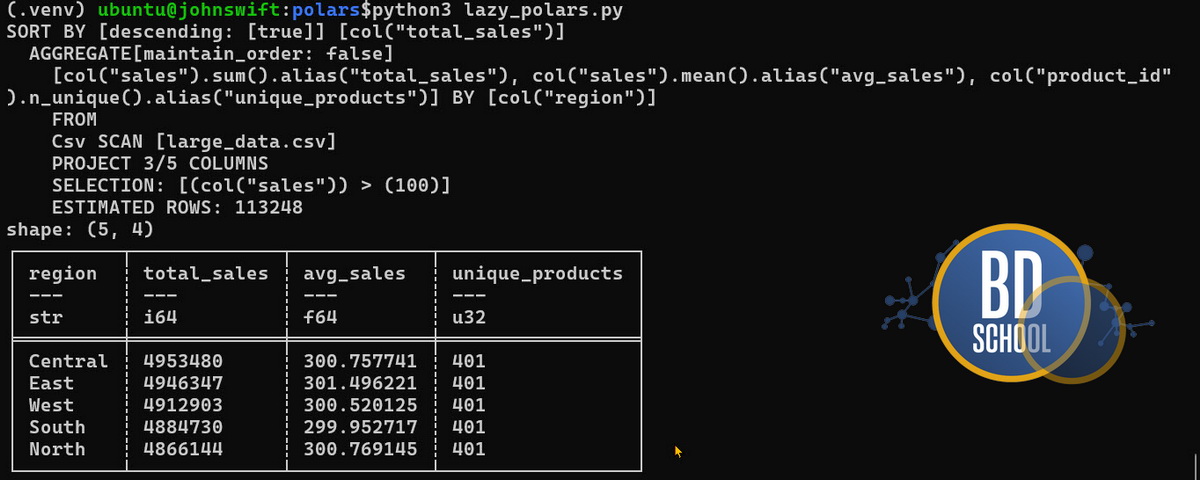
Чтение источника и оценка объема
На самом нижнем уровне происходит первичное обращение к файлу. Строка Csv SCAN [large_data.csv] фиксирует начало чтения данных с диска. Рядом находится параметр ESTIMATED ROWS: 113248. Это базовая оценка количества строк в наборе данных. Внутренний оптимизатор использует эту цифру для первоначального выделения оперативной памяти.
Проталкивание проекции
Чуть выше располагается запись PROJECT 3/5 COLUMNS. Это наглядная иллюстрация работы механизма Projection Pushdown. Инструмент проанализировал написанный код до начала вычислений.
Оптимизатор выявил следующие условия для загрузки нужных атрибутов.
-
Для итогового результата требуются только три колонки.
-
Это столбцы region, product_id и sales.
-
Колонки id и date полностью игнорируются системой. В итоге программа поместит в память только полезную информацию.
Такой подход экономит массу системных ресурсов при обработке гигантских файлов.
Проталкивание предикатов
Дальше идет строка SELECTION: [(col(«sales»)) > (100)]. Здесь мы видим применение механизма Predicate Pushdown. Фильтрация запускается на самом раннем этапе.
Данное техническое решение дает несколько серьезных преимуществ при вычислениях.
-
Записи с продажами меньше ста отсекаются немедленно.
-
Ненужная информация не попадает на следующие этапы конвейера.
-
Радикально снижается нагрузка на процессор при группировке. Система применяет заданные условия фильтрации прямо во время чтения диска.
Это кардинально отличает ленивое исполнение от классического жадного подхода.
Агрегация и вычисления
Следующий блок отвечает за группировку нужных данных. Запись AGGREGATE[maintain_order: false] указывает на старт процесса. Флаг false означает отказ от сохранения исходного порядка строк. Это осознанное решение для экономии времени. Отказ от лишней сортировки внутри групп ускоряет вычисления.
Сам процесс математической обработки состоит из нескольких параллельных шагов.
-
Библиотека берет данные и группирует их по колонке region.
-
Параллельно вычисляется общая сумма продаж для поля total_sales.
-
Одновременно считается среднее значение для поля avg_sales.
-
Затем подсчитывается количество уникальных товаров для unique_products. Все перечисленные математические функции выполняются за один единственный проход.
Высокая скорость достигается благодаря строгой типизации и векторизации языка Rust.
Финальная сортировка
На самом верху плана находится последняя инструкция алгоритма. Это строка SORT BY [descending: [true]] [col(«total_sales»)]. Программа берет уже сжатую и агрегированную таблицу. Затем она сортирует итоговые записи по убыванию суммы продаж. Только после этого готовый результат передается в твою переменную.
Представленный лог отлично доказывает высочайшую эффективность ленивого подхода. Платформа проделала огромную подготовительную работу до запуска реальных вычислений.
Варианты скриптов для формирования датасетов смотри здесь на GitHub где лежит код к данной статье.
Продвинутые техники оптимизации
Polars предоставляет мощные инструменты для работы с данными, которые не помещаются в оперативную память (RAM). Это решает одну из самых болезненных проблем аналитиков — MemoryError. Используя продвинутые техники, можно обрабатывать гигабайты данных на обычном ноутбуке.
J,hf,jnrf 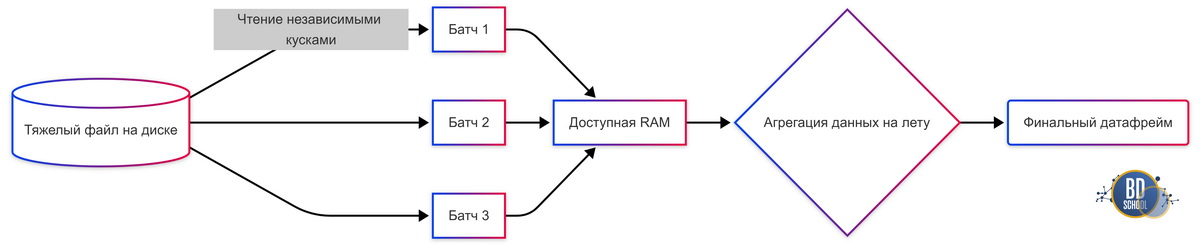
Ключевые механизмы оптимизации включают:
- Streaming API (Потоковая обработка):
При использовании метода collect(streaming=True), Polars обрабатывает данные частями (чанками). Он не загружает весь датасет в память целиком. Это позволяет выполнять агрегацию и join операций на данных, объем которых превышает RAM. - Projection Pushdown (Проталкивание проекции):
Оптимизатор запросов сканирует ваш код и определяет, какие колонки реально нужны для финального результата. Если в файле 100 колонок, а вы используете только 3, Polars загрузит только эти 3. Это работает автоматически в ленивом режиме. - Predicate Pushdown (Проталкивание предикатов):
Аналогично колонкам, фильтры (filter) применяются как можно раньше. Если вы фильтруете данные по дате, Polars постарается отсечь лишние строки еще на этапе чтения файла (если формат файла это поддерживает, например, Parquet).
Эти техники превращают Polars из простой библиотеки в полноценный аналитический движок, сравнимый по логике работы с базами данных.
Как мигрировать с Pandas — подводные камни
Переход с Pandas на Polars может быть непростым из-за привычек. Синтаксис похож, но логика отличается. Чтобы миграция прошла успешно, важно знать типичные ошибки новичков.
Список частых проблем при переходе:
- Итерация по строкам: В Pandas итерация медленная, но возможная (iterrows). В Polars это строжайшее табу. Всегда используйте векторные выражения. Если вы пишете цикл for для обработки данных, вы делаете что-то не так.
- Обращение по индексу: Попытка использовать .loc[] или .iloc[] для сложной логики выбора вызовет боль. Polars поощряет реляционный подход (как в SQL): фильтрация условий и джойны, а не поиск по координатам.
- Привычка к inplace операциям: Pandas часто использует inplace=True. Polars следует принципам функционального программирования. Методы возвращают новый (или обновленный) Frame, а не изменяют старый «на месте».
Понимание этих нюансов сэкономит вам часы отладки и позволит сразу писать быстрый код.
Заключение
Polars — это не просто альтернатива Pandas, это эволюция инструментов обработки данных. Благодаря архитектуре на Rust, использованию Apache Arrow и умному оптимизатору запросов, он предлагает производительность, недостижимую для инструментов предыдущего поколения. Для задач, где важна скорость обработки больших массивов данных или экономия памяти, Polars становится стандартом де-факто в экосистеме Python.
Референсные ссылки
- [Polars User Guide: Официальная документация] (https://pola-rs.github.io/polars-book/)
- [Ritchie Vink: Polars — Blazingly Fast DataFrames in Rust & Python] (https://www.youtube.com/watch?v=tLKd-QvU-8A)
- [Keahey, T. (2023). Moving from Pandas to Polars] (https://towardsdatascience.com/moving-from-pandas-to-polars-725845247926)