 353
353 
Содержание
- Принципы работы Copy on First Access на уровне дисковой подсистемы
- Чтение данных с реплики
- Запись данных на целевой том
- Изменение исходного тома
- Сравнение аппаратных алгоритмов репликации c Copy on First Access
- Использование алгоритма в облачных сервисах
- Инициализация дисков AWS EBS
- Восстановление аналитических баз данных
- Классические сценарии использования в инфраструктуре
- Деградация производительности и I/O штрафы
- Программная симуляция контроллера на Python
- Архитектура сети для фоновой синхронизации томов c Copy on First Access
- Отличия физического клонирования от логического
- Заключение
- Референсные ссылки и полезные материалы
COFA (Copy on First Access) — это стратегия управления памятью, при которой данные копируются только при первом обращении к ним, что позволяет отложить накладные расходы и снизить избыточное копирование по сравнению с немедленным дублированием данных. COFA (Copy on First Access) — это аппаратный алгоритм отложенного копирования блоков данных на уровне контроллера системы хранения. Технология позволяет создать мгновенно доступную реплику дискового тома без ожидания полного побайтового переноса информации. Целевой том предоставляется операционной системе как полностью готовый к операциям чтения и записи. Фактический перенос блоков с исходного диска происходит точечно и только в момент первого прямого обращения к ним. Оставшийся объем данных переносится контроллером СХД в асинхронном фоновом режиме. Такой подход кардинально сокращает время простоя (RTO) при восстановлении баз данных из бэкапов. Системные инженеры получают возможность разворачивать терабайтные тестовые среды за несколько секунд.
Принципы работы Copy on First Access на уровне дисковой подсистемы
Процесс инициализации реплики Copy On Firts Access начинается с выделения нового логического тома (LUN) на дисковом массиве. Изначально этот том не содержит физических данных, но операционная система хоста видит его полный заявленный объем. Контроллер СХД выделяет в оперативной памяти специальную битовую карту (bitmap) для этого тома. Битовая карта отслеживает статус синхронизации каждого логического блока (LBA) между источником и репликой. Алгоритм обрабатывает операции ввода-вывода (I/O) по нескольким строгим сценариям.

Чтение данных с реплики
Аналитический сервер запрашивает конкретный блок данных с подключенного целевого тома. Контроллер дискового массива перехватывает этот запрос и проверяет статус сектора в битовой карте. Если блок отмечен как «скопирован», контроллер считывает его напрямую с целевого диска и отдает серверу. Если блок имеет статус «не скопирован», контроллер приостанавливает выполнение запроса хоста. СХД считывает оригинальный блок с исходного тома, записывает его на целевой диск и обновляет статус в битовой карте. Только после завершения этой транзакции данные отправляются ожидающему аналитическому приложению. При всех последующих обращениях к этому блоку чтение будет выполняться локально с реплики без задержек.
Запись данных на целевой том
Процесс записи требует обеспечения строгой консистентности данных для сохранения целостности бэкапа. Допустим, тестовая база данных пытается перезаписать блок на нашей целевой реплике. Контроллер проверяет битовую карту и обнаруживает, что этот блок еще не был синхронизирован с источником. СХД считывает оригинальный блок с исходного диска и помещает его в скрытую резервную область целевого тома. После этого контроллер разрешает тестовой базе данных записать новую информацию поверх этого блока. Это гарантирует, что исходное состояние данных на момент создания снимка останется доступным для процедур отката (rollback).
Изменение исходного тома
Продакшен-база данных постоянно генерирует новые транзакции и перезаписывает блоки на оригинальном исходном томе. Дисковый массив обязан защитить целевую реплику от несанкционированного изменения оригинальных данных. Когда сервер пытается записать новую информацию на исходный LUN, контроллер проверяет битовую карту реплики. Если старая версия изменяемого блока еще не скопирована на целевой том, происходит операция Split I/O. Контроллер читает старый блок с оригинала, копирует его на реплику и только затем разрешает запись новых данных на исходный диск. Эта механика жестко фиксирует состояние реплики (Point-in-Time) на ту секунду, когда команда клонирования была инициирована администратором.

Сравнение аппаратных алгоритмов репликации c Copy on First Access
Архитекторы баз данных часто путают различные механизмы создания снимков и клонирования файловых систем. Важно различать алгоритмы, работающие на уровне блочных устройств, от программных решений на уровне операционной системы.
Существует три основных подхода к обработке I/O-запросов при клонировании данных.
-
Алгоритм Copy on First Access создает полностью независимый физический клон тома. Физическое копирование блока инициируется любой первой операцией (чтением или записью) со стороны хоста.
-
Алгоритм Copy on First Write создает логический снапшот, состоящий из метаданных и виртуальных указателей. Блоки копируются в резервный пул только при попытке их перезаписи на оригинальном томе, а запросы на чтение просто перенаправляются на источник.
-
Алгоритм Copy on Write в in-memory СУБД (например, Redis) работает на уровне страниц оперативной памяти. При запуске команды BGSAVE операционная система делает форк процесса, и копирование страниц в RAM происходит только при их изменении родительским процессом.
Каждая из этих технологий имеет свой профиль нагрузки на оборудование. Понимание этих механизмов позволяет выбрать оптимальную стратегию для резервного копирования высоконагруженных кластеров.
Использование алгоритма в облачных сервисах
Архитектурные концепты аппаратных СХД стали фундаментом для построения систем хранения в публичных облаках. Провайдеры интегрируют механики отложенного доступа в гипервизоры для ускорения инициализации виртуальных инфраструктур.
Инициализация дисков AWS EBS
Процесс создания диска Amazon EBS из снимка в сервисе Amazon S3 является классическим примером ленивой загрузки (Lazy Loading). Когда пользователь разворачивает виртуальную машину, EBS-том переходит в статус available за несколько секунд. Операционная система Linux на инстансе EC2 сразу монтирует файловую систему и начинает загрузку сервисов. Однако физически блоки данных все еще находятся в медленном объектном хранилище S3. Если приложение запрашивает файл, блоки которого еще не перенесены на EBS, гипервизор перехватывает I/O-операцию. Блок экстренно скачивается из S3 на SSD-накопитель тома EBS, после чего запрос операционной системы удовлетворяется. Параллельно гипервизор продолжает фоновую загрузку оставшихся секторов из корзины S3.
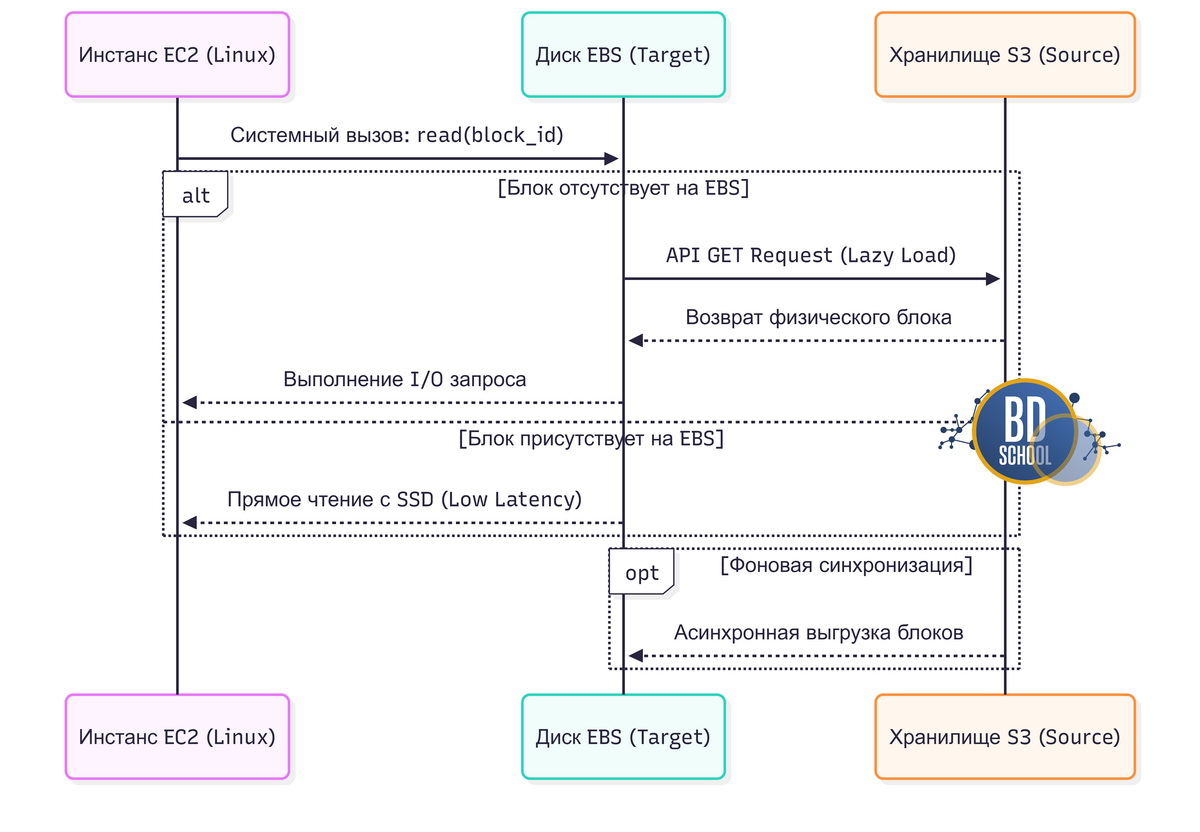
Восстановление аналитических баз данных
Облачные платформы предоставляют колоночные СУБД в формате управляемых сервисов (Managed Services). При восстановлении кластера ClickHouse из резервной копии сервер становится доступен для подключения практически мгновенно. Дисковая подсистема облака использует отложенное копирование для обеспечения работы аналитических запросов без ожидания переноса петабайтов данных.
Рассмотрим пример SQL-запроса, который инициирует экстренную загрузку блоков дисковой подсистемой.
SELECT
domain_name,
count(request_id) AS total_requests,
quantiles(0.5, 0.99)(response_time_ms) AS latency_percentiles
FROM proxy_access_logs
WHERE event_date >= today() - 3
GROUP BY domain_name
ORDER BY total_requests DESC
LIMIT 50;
При выполнении этого агрегационного запроса движок ClickHouse пытается прочитать файлы конкретных партиций за последние три дня. Контроллер облачного диска перехватывает обращения к секторам, скачивает их из бэкапа и передает в СУБД. Исторические партиции за прошлые месяцы будут спокойно скачиваться в фоновом режиме, не потребляя высокий приоритет сетевой полосы.
Классические сценарии использования в инфраструктуре
Технология перехвата блоков на уровне СХД решает критические задачи по обеспечению непрерывности работы бизнеса. Системные инженеры внедряют этот алгоритм для обхода ограничений традиционного копирования файлов.
Технология применяется в корпоративных дата-центрах для реализации следующих архитектурных паттернов.
-
Обеспечение нулевого окна резервного копирования для высоконагруженных транзакционных систем без блокировки таблиц на мастере.
-
Генерация изолированных тестовых сред (песочниц) с актуальными данными продакшена для проверки сложных миграций схем баз данных.
-
Бесшовная миграция логических томов между старыми и новыми аппаратными стойками СХД в фоновом режиме без остановки бизнес-приложений.
Эти паттерны снижают операционную нагрузку на администраторов и минимизируют риски повреждения данных при релизах новых версий ПО.
Деградация производительности и I/O штрафы
Аппаратный перехват запросов неизбежно влечет за собой увеличение времени отклика системы (Latency). Этот эффект называется штрафом производительности (I/O Penalty) первых обращений. Когда база данных запрашивает блок, отсутствующий на реплике, контроллер тратит время на проверку битовой карты, сетевое обращение к источнику и запись на локальный диск. В масштабах высоконагруженной СУБД эти миллисекундные задержки суммируются и приводят к существенному замедлению выполнения первых аналитических запросов. Мониторинг показывает резкие скачки метрики Disk Read Latency сразу после монтирования свежего тома.
Инфраструктурные команды используют несколько методов для минимизации влияния штрафов производительности на бизнес-процессы.
-
Настройка политик QoS (Quality of Service) на контроллерах СХД для выделения максимальной полосы пропускания под фоновую синхронизацию в часы минимальной нагрузки на серверы.
-
Принудительный прогрев блоков (Cache Warming) с помощью утилит
fioилиddв Linux, которые линейно вычитывают весь объем диска до запуска сервиса базы данных. -
Использование Flash-накопителей (NVMe) в качестве буферного кэша на целевом массиве для ускорения записи перехваченных блоков.
Комплексное применение этих методов позволяет сократить период деградации производительности с нескольких часов до нескольких минут.
Программная симуляция контроллера на Python
Логику работы битовых карт и перехвата I/O-операций можно продемонстрировать с помощью базовых структур данных на языке Python. Данный скрипт эмулирует работу дискового контроллера при обработке запросов на чтение к целевому тому.
import time
class StorageControllerEmulator:
def __init__(self, source_lun):
self.source = source_lun
self.target = {}
self.bitmap = set() # Битовая карта для отслеживания скопированных блоков
def read_block(self, block_id):
# 1. Проверка битовой карты: блок уже на реплике?
if block_id in self.bitmap:
return self.target[block_id]
# 2. Перехват I/O (I/O Penalty): симуляция задержки при копировании
time.sleep(0.3)
data_chunk = self.source.get(block_id)
# 3. Запись на целевой диск и обновление статуса
self.target[block_id] = data_chunk
self.bitmap.add(block_id)
return data_chunk
# Оригинальный рабочий том (Source)
production_lun = {
"block_01": b"sys_metadata",
"block_02": b"users_table_index",
"block_03": b"transactions_data"
}
# Инициализация реплики
cofa_volume = StorageControllerEmulator(production_lun)
print("Запуск аналитического запроса...")
# Первый запрос вызывает перехват и копирование блока
start = time.time()
data = cofa_volume.read_block("block_02")
print(f"Первое чтение (Miss). Данные: {data}. Затрачено: {time.time() - start:.4f} сек")
# Второй запрос обслуживается напрямую с реплики
start = time.time()
data = cofa_volume.read_block("block_02")
print(f"Повторное чтение (Hit). Данные: {data}. Затрачено: {time.time() - start:.4f} сек")
Пример наглядно показывает, как первый запрос блокирует выполнение программы из-за искусственной задержки (time.sleep), имитирующей физическое перемещение байтов. При повторном обращении скрипт моментально отдает данные из словаря целевого тома.
Архитектура сети для фоновой синхронизации томов c Copy on First Access
Перенос терабайтов данных между дисковыми массивами генерирует агрессивный сетевой трафик (East-West traffic). Если синхронизация идет через основную сеть передачи данных, коммутаторы ядра могут отбрасывать пакеты клиентских приложений из-за переполнения буферов. Системные архитекторы обязаны физически или логически изолировать трафик репликации СХД от серверов приложений. В классических SAN-архитектурах для этого используются выделенные порты Fibre Channel и отдельные зоны (Zoning) на оптических фабриках. В сетях iSCSI или NVMe-oF настраиваются изолированные VLAN с включенными протоколами контроля потока (PFC). Облачные провайдеры применяют независимые скрытые сети (Underlay Networks) для транспорта блоков между узлами хранения. Это гарантирует стабильную скорость фоновой синхронизации без влияния на работу пользовательских виртуальных машин.
Отличия физического клонирования от логического
При проектировании архитектуры данных необходимо отличать поблочное физическое копирование от логического клонирования файлов в современных СУБД. Аналитические движки вроде Snowflake или механизмы хард-линков в локальных базах данных используют концепцию Zero-copy cloning. Эта концепция работает исключительно на уровне метаданных файловой системы или внутренних таблиц каталога базы. При создании логического клона файлы с данными не дублируются на накопителях. Система просто создает новые указатели на существующие иммутабельные файлы партиций. Алгоритм отложенного доступа, Copy on First Access, работает на фундаментальном аппаратном уровне блочных устройств (Block Storage). Он всегда создает полностью независимую физическую копию данных, которая после завершения фонового процесса займет ровно столько же места на дисковых полках, сколько и оригинал.
Заключение
Алгоритм отложенного копирования, Copy on First Access, остается базовым инструментом для управления жизненным циклом данных в Enterprise-инфраструктуре. Понимание логики перехвата I/O-операций и работы битовых карт позволяет Data-инженерам правильно прогнозировать время готовности систем после аварийного восстановления. Использование стратегий принудительного прогрева файлового кэша эффективно нивелирует временные просадки производительности накопителей. Данная архитектурная концепция успешно перешла из железных корпоративных массивов в основу облачных блочных хранилищ. Умение работать с этими низкоуровневыми механиками необходимо для проектирования отказоустойчивых кластеров и оптимизации затрат на хранение резервных копий.
Референсные ссылки и полезные материалы
- Smith, J. (2025). The Hidden Cost of Cold Starts: Defeating EBS Lazy Loading in AI Pipelines. Medium.
- Dhandala, N. (2026). How to Integrate OTel Arrow with Apache Arrow-Native Backends Like ClickHouse. OneUptime Blog.
- Codemia Engineering (2025). Zero-Copy I/O: From sendfile to io_uring – Evolution and Impact on Latency. Codemia.