
Недавно мы рассказывали, что аналитика больших данных с помощью технологий Big Data – это необязательно удел только крупных корпораций. В этой статье мы рассмотрим реальный бизнес-кейс, как извлечь выгоду из накопленных данных о своих пользователях, применяя для этого возможности NoSQL-СУБД Elasticsearch для полнотекстового поиска по полуструктурированным данным и веб-интерфейс визуализации...

Чтобы наглядно показать, как аналитика больших данных и машинное обучение помогают быстро решить актуальные бизнес-проблемы, сегодня мы рассмотрим кейс компании Леруа Мерлен. Читайте в нашей статье про нахождение аномалий в сведениях об остатках товара на складах и в магазинах с помощью моделей Machine Learning, а также про прикладное использование Apache...

Недавно мы разбирали особенности интеграции Apache Kudu и Spark. В продолжение этой темы, сегодня поговорим про некоторые особенности выполнения SQL-операций с данными при интеграции этих Big Data фреймворков, а также рассмотрим пример записи данных в мульти-мастерный кластер Куду через Impala с помощью API Data Frame на PySpark. Что приносит Kudu...
Продолжая разбирать production-кейсы реального использования этих технологий Big Data, сегодня поговорим подробнее, каковы плюсы совместного применения Kudu, Spark Streaming, Kafka и Cloudera Impala на примере аналитической платформы для мониторинга событий информационной безопасности банка «Открытие». Также читайте в нашей статье про возможности этих технологий в контексте машинного обучения (Machine Learning), в...

Сегодня мы рассмотрим практический кейс использования Apache Kudu с Kafka, Storm и Cloudera Impala в крупной китайской корпорации, которая производит смартфоны. На базе этих Big Data технологий компания Xiaomi построила собственную платформу для BI-аналитики больших данных и генерации отчетности в реальном времени. История Kudu-проекта в Xiaomi Корпорация Xiaomi начала использовать...
Вчера мы говорили про интеграцию Apache Kudu со Spark SQL, Kafka и Cloudera Impala для эффективной организации озера данных (Data Lake), обеспечивающего быструю аналитику больших данных в режиме реального времени. В продолжение этой темы, сегодня рассмотрим 5 примеров практического использования kudu в Big Data проектах, уделив особое внимание системам бизнес-аналитики...

В продолжение темы про совместное использование Apache Kudu с другими технологиями Big Data, сегодня рассмотрим, как эта NoSQL-СУБД работает вместе с Kafka, Spark и Cloudera Impala для построения озера данных (Data Lake) для быстрой аналитики больших данных в режиме реального времени. Также читайте в нашей статье про особенности интеграции Apache...

В этой статье продолжим разговор про Apache Kudu и рассмотрим, как эта NoSQL-СУБД используется с Hadoop и Cloudera Impala, чем она полезна в организации озера данных (Data Lake) и почему Куду не заменяет, а успешно дополняет HDFS и HBase для эффективной работы с большими данными (Big Data). Apache Kudu в...

Сегодня поговорим про еще один open-source проект от Apache Software Foundation – Bigtop, который позволяет собрать и протестировать собственный дистрибутив Hadoop или другого Big Data фреймворка, например, Greenplum. Читайте в нашей статье, что такое Apache Bigtop, как работает этот инструмент, какие компоненты он включает и где используется на практике. Что...
Сегодня рассмотрим облачные сервисы и платформы ELK-стека, которые позволяют использовать все функциональные преимущества Elasticsearch с Kibana без развертывания собcтвенной ИТ-инфраструктуры (on-demand), интегрируя их с другими облачными приложениями. Читайте в нашей статье, что такое Elastic Cloud Enterprise и чем это отличается от Amazon Elasticsearch Service, Open Distro и других cloud-решений. Такие...

В этой статье поговорим про интеграцию ELK-стека с экосистемой Apache Hadoop: зачем это нужно и с помощью каких средств можно организовать обмен данными между HDFS и Elasticsearch, а также при чем здесь Apache Spark, Hive и Storm. Еще рассмотрим несколько практических примеров, где реализована такая интеграция Big Data систем для...

Сегодня поговорим, как связать Elasticsearch с Apache Kafka: рассмотрим, зачем нужны коннекторы, когда их следует использовать и какие особенности популярных в Big Data форматов JSON и AVRO стоит при этом учитывать. Также читайте в нашей статье, что такое Logstash Shipper, чем он отличается от FileBeat и при чем тут Kafka...

В этой статье рассмотрим несколько примеров по аналитике больших данных в Elasticsearch (ES), а также разберем возможности алгоритмов машинного обучения в ELK Stack. Читайте, как использовать NoSQL-СУБД ES в качестве озера данных для проверки различных бизнес-гипотез с помощью Machine Learning, показывая результаты моделирования в интерфейсе Kibana: практическая аналитика Big Data....

Сегодня рассмотрим основные преимущества и недостатки ELK-стека. Читайте в этой статье, чем хороши Elasticsearch с Logsatsh и Kibana, а также каковы их основные недостатки и ограничения для использования в реальных Big Data проектах. Также мы собрали для вас несколько практических примеров, где и как используется Elasticsearch в интернет-магазинах, банках и...
В этой статье рассмотрим ELK-инфраструктуру: разберем, зачем поисковый движок Elasticsearch использует сборщик логов Logstash и при чем здесь визуальный интерфейс Kibana. Также поговорим, в каких Big Data проектах используются эти системы и для чего. Зачем вам Elasticsearch: полнотекстовый поиск по Big Data Чтобы определить, почему деньги пропали с банковского счета или...
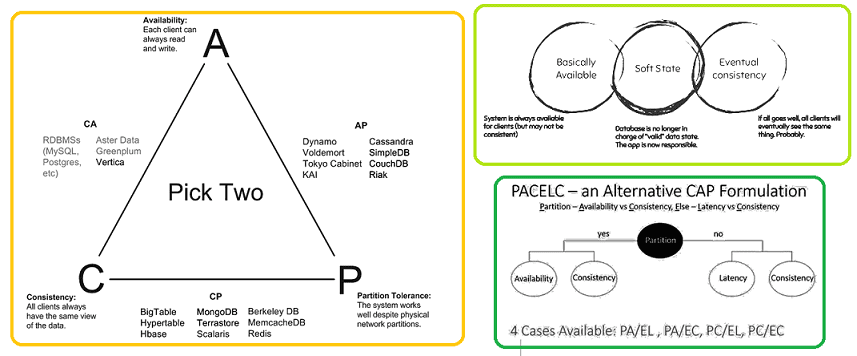
В этой статье мы расскажем про краеугольный камень распределенных Big Data систем – CAP-теорему, в которой одновременно возможно реализовать только 2 свойства из 3-х, по аналогии с треугольником ограничений в проектном менеджменте «Быстро-Качественно-Дешево». Также рассмотрим, за что критикуют модель CAP и почему современные NoSQL-СУБД стоит рассматривать с позиций BASE и...

Рассмотрев ключевые сходства и различия Cassandra и HBase, сегодня мы поговорим, в каких случаях стоит выбирать ту или иную нереляционную СУБД для обработки больших данных (Big Data) в NoSQL-хранилище. Где используются NoSQL-СУБД в Big Data Прежде всего отметим основные области применения рассматриваемых нереляционных СУБД. Проанализировав наиболее известные примеры использования (use...

Cassandra и HBase считаются наиболее популярными NoSQL-СУБД в мире Big Data. Сегодня мы поговорим, что между ними общего и чем отличаются эти нереляционные базы данных, сравнив их по 10 ключевым параметрам: от архитектуры до инструментальных средств. Что общего между Apache Cassandra и HBase: 5 главных сходств Прежде всего отметим, чем...

Продолжая разговор про примеры практического использования Apache Cassandra в реальных Big Data проектах, сегодня мы расскажем вам о рекомендательной системе стримингового сервиса Spotify на базе этой нереляционной СУБД в сочетании с другими технологиями больших данных: Kafka, Storm, Crunch и HDFS. Рекомендательная система Spotify: зачем она нужна и что должна делать...

Благодаря быстроте, надежности и другим достоинствам Apache Cassandra, эта распределенная NoSQL-СУБД широко применяется во многих Big Data проектах по всему миру. В этой статье мы собрали для вас несколько интересных примеров реального использования Кассандры в 5 ключевых направлениях современного ИТ. Где используется Apache Cassandra: 5 главных приложений c примерами Промышленные...