
В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, что такое DataStax Enterprise Graph. Читайте далее, как немецкая ИТ-компания Traversals с помощью этой распределенной графовой СУБД построила масштабное аналитическое решение для кибербезопасности, обнаружения мошенничества, анализа конкурентов и оповещения клиентов в реальном времени. Также разберем, при...

В одной из статей мы говорили о TaskFlow API, который позволяет задачам передавать и получить друг от друга информацию. За кулисами этого приема и передачи в Apache Airflow лежит XCom. Сегодня расскажем вам о том, как взаимодействуют задачи через XCom, а также, как задаются параметры конфигурации через особые переменные Apache...

Продолжая недавний разговор про потоковую передачу событий и соответствующие Big Data инструменты, сегодня рассмотрим не отдельные фреймворки обработки данных в режиме реального времени, а комплексные платформы, которые объединяют сразу несколько технологий для интерактивной аналитики больших данных. Вас ждет краткий обзор Cloudera Streaming Analytics, Materialize и Rockset: что это такое, как...

Продвигая наши курсы по Greenplum и Arenadata DB, сегодня рассмотрим, что представляет собой облачная платформа VMware Tanzu Greenplum, где ее можно развернуть и каковы преимущества cloud-решения по сравнению с локальной версией этой MPP-СУБД. Что такое VMware Tanzu Greenplum и чем это отличается от open-source версии Напомним, в 2020 году корпорация...

Сегодня в качестве полезного примера для обучения дата-инженеров и разработчиков Spark-приложений, разберем кейс компании Pinterest по интерактивной аналитике больших данных средствами SQL-модуля этого популярного фреймворка. Читайте далее, почему дата-инженеры решили заменить HiveServer2 на Spark Thrift JDBC/ODBC, зачем понадобилось писать собственный клиент поверх Apache Livy и как это было сделано. Зачем...
Хотя Apache Kafka стала стандартом де-факто для потоковой передачи событий, на этой платформе можно реализовать и пакетный режим вычислений. В рамках обучения дата-инженеров, сегодня рассмотрим, как совместить пакетную парадигму обработки Big Data с потоковой, развернув конвейер аналитики больших данных на Apache Kafka. Пакеты и потоки: versus или вместе Пакетную и потоковую...
В недавней статье про преимущества хранилища метаданных Apache Hive и другие плюсы этого популярного инструмента SQL-on-Hadoop, мы упоминали формат открытых таблиц Iceberg как альтернативу для хранения огромных наборов аналитических данных. Он добавляет высокопроизводительные SQL-подобные таблицы в вычислительные механизмы Spark, Trino, Presto, Flink и Hive. Сегодня рассмотрим подробнее, что такое Apache Iceberg и...
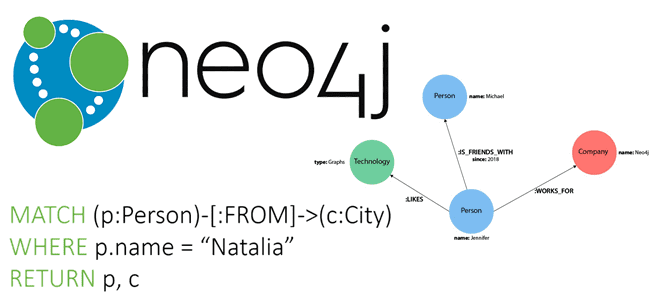
Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим ключевые отличия графовых СУБД от реляционных, а также познакомимся с основами Neo4j и ее языком запросов - Cypher. Также вас ждет практический пример построения несложного графа средствами Cypher. Когда графовые СУБД лучше реляционных и почему Несмотря на...

Сегодня рассмотрим, как методы графовой аналитики больших данных помогают бороться с эпидемией финансовых мошенничеств: выявлять номера злоумышленников, идентифицировать фрод-транзакции, выявлять и предотвращать схемы отмывания денег. Читайте далее, что под капотом AML-систем и как инструменты Data Science предотвращают злоупотребление методами социальной инженерии. Немного истории: что такое социальная инженерия и чем это...

В продолжение недавней статьи для дата-инженеров про альтернативные платформы потоковой передачи событий вместо Apache Kafka, сегодня рассмотрим пример аналитики больших данных средствами Flink SQL, записи результатов в Elasticsearch и их визуализации в Kibana. Читайте далее, чем Redpanda отличается от Kafka, а Flink – от Apache Spark с точки зрения потоковой...

В рамках обучения разработчиков Spark-приложений, аналитиков данных и дата-инженеров, сегодня рассмотрим, как улучшить и визуализировать понимание обработки данных в этом Big Data фреймворке. Читайте далее про API встроенных механизмов наблюдения за качеством данных в Apache Spark и открытые библиотеки профилирования на примере Deequ. 2 уровня абстракции мониторинга Spark-приложений для дата-инженера...

При том, что Apache Kafka является фреймворком №1 в потоковой обработке Big Data, эта распределенная платформа передачи событий имеет специфические недостатки и ограничения, которые затрудняют ее использование в некоторых сценариях. Сегодня рассмотрим, что именно в Apache Kafka усложняет жизнь администраторам, разработчикам и дата-инженерам, а также как Redpanda решает эти проблемы....

Добавляя в наши курсы для дата-инженеров по Apache Airflow полезные примеры, сегодня рассмотрим тонкости контроля доступа к DAG в этой платформе. Читайте далее, какие роли есть в Apache Airflow, каковы разрешения для них и как Flask AppBuilder осуществляет управление доступом к пользовательскому интерфейсу веб-сервера. Безопасность DAG’ов в Apache AirFlow: роли...

Анализ данных в рамках пользовательский сеансов (сессий) – довольно востребованный кейс в Apache Spark, который не так просто реализовать из-за особенностей потоковой и пакетной обработки, а также эксплуатационных расходов. Сегодня рассмотрим, как работают сеансовые окна Spark Structured Streaming и каковы ограничения этого фреймворка. Что такое сеансовые окна: краткий ликбез по...

В этой статье для разработчиков Apache Kafka рассмотрим пример масштабирования потоковой обработки событий с Akka Streams. Читайте далее, что не так с параллелизмом при одновременном выполнении событий на запись, как Akka Streams решает эту проблему и при чем здесь Apache Kafka. Проблемы масштабирования потоковой обработки в Kafka Streams Масштабная потоковая...

На протяжении всей истории человечества пандемии являлись причинами глобальных макроэкономических изменений. Например, эпидемия чумы привела к окончательному падению монгольской империи, изменив баланс сил между мусульманским и европейским миром в пользу последнего. А эпидемия испанки, разразившаяся в конце первой мировой войны, привела к окончательной капитуляции Германии. Последняя пандемия COVID-19 изменила мир...
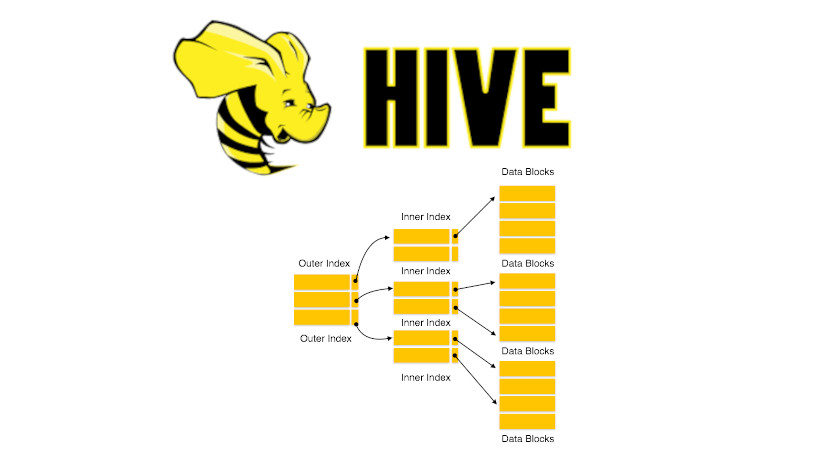
В прошлый раз мы говорили про драйвер JDBC и его использование в Hive. Сегодня поговорим про особенности создания и работы индекса в распределенной Big Data платформе Apache Hive. Читайте далее про особенности работы с индексами в распределенной среде Big Data СУБД Hive. Какую роль играет использование индекса при обработке Big...

Чтобы добавить в наши курсы для дата-инженеров по технологиям Apache Kafka, Spark, AirFlow, NiFi, Flink и Greenplum, еще больше практических примеров, сегодня разберем кейс ритейлера Леруа Мерлен. Читайте далее, как сотрудники российского отделения этой международной компании интегрировали в единую платформу более 350 реляционных СУБД и NoSQL-источников с помощью CDC-подхода на...
Сегодня рассмотрим пример построения интеллектуальными конвейера потоковой обработки видео с Apache Kafka и алгоритмами машинного обучения. Читайте далее, зачем для этого нужен протокол RTSP, что такое библиотека Sarama и как интегрировать алгоритмы машинного/глубокого обучения в систему видеоаналитики реального времени. Потоковая видеоаналитика: прием мультимедиа в реальном времени Видеоаналитика – одно из...
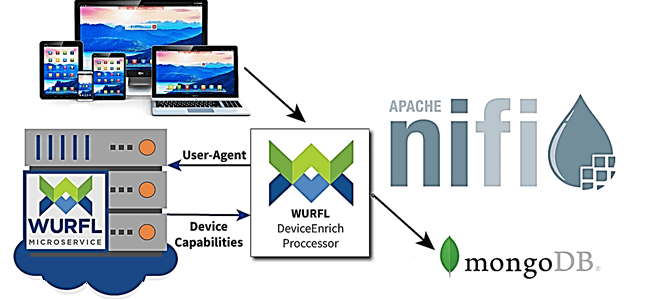
Развивая наши курсы по Apache NiFi для дата-инженеров и администраторов, сегодня рассмотрим, как как обогатить поток данных, сделав информацию об устройстве доступной для систем, которые хранят или потребляют данные в следующих этапах конвейера. Также разберем, зачем нужна технология детектирования устройств, что такое WURFL и как это реализовать в Apache NiFi....