
В октябре 2021 года российская компания «Аренадата Софтвер» выпустила новый продукт для аналитики больших данных под брендом Arenadata. Что такое Arenadata LogSearch (ADLS), при чем здесь Elasticsearch и какие потребности закрывает эта корпоративная адаптация open-source технологии полнотекстового поиска от отечественных разработчиков. Elasticsearch, OpenSearch и Arenadata LogSearch: близнецы или тройняшки? Среди...

Сегодня разберем кейс платформы онлайн-обучения Udemy по разработке собственной системы потоковой аналитики больших данных о событиях пользовательского поведения на Apache Kafka, Hive и сервисах Amazon. Про требования к инфраструктуре отслеживания событий и их реализацию с помощью Apache Kafka, Hive, Kubernetes, AWS S3 и EMR, а также чем AVRO лучше Protobuf....

MLOps и построение конвейеров машинного обучения – одни из самых актуальных задач современной Data Science. Сегодня рассмотрим, чем совместное использование Apache Airflow и Ray полезно для дата-инженера и ML-разработчика. Читайте далее про кластерное развертывание Python-кода ML-моделей и упрощение ETL-процессов с Apache Airflow и Ray. Apache AirFlow для ML: возможности и...
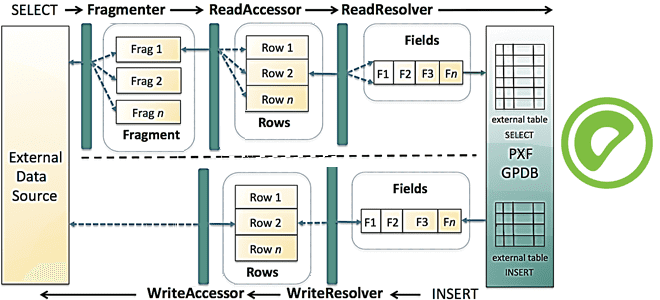
Специально для дата-инженеров, разработчиков OLAP-конвейеров и архитекторов DWH на MPP-СУБД Greenplum и Arenadata DB сегодня рассмотрим, что представляет собой PXF, из каких компонентов он состоит и как они взаимодействуют друг с другом, чтобы обеспечить параллельный высокопроизводительный доступ к данным и объединенную обработку запросов к разнородным источникам. Что PXF и зачем...

В начале сентября 2021 года вышел 3-й релиз языка программирования Scala, который разработчики называют полностью переработанным из-за модернизации системы типов и добавления новых функций. Текущая версия Apache Spark 3.2.0, выпущенная месяцем позже, поддерживает Scala 2.13 и 3.0 с ограничением некоторых возможностей. Читайте далее, как разработчикам распределенных Spark-приложений писать задания на...

В этой статье мы поговорим про основные базовые операции распределенной СУБД Hbase. Также рассмотрим применение этих операций к данным, хранящимся в этой СУБД на практических примерах. Читайте далее про базовые CRUD-операции в Hbase и их особенности. Основные CRUD-операции в распределенной СУБД Hbase HBase - это распределенная NoSQL столбцово-ориентированная (данные представлены...
Добавляя в наши курсы по Apache Kafka еще больше полезных кейсов, сегодня рассмотрим пример интеграции этой распределенной платформы потоковой передачи событий с масштабируемой key-value СУБД GridDB через JDBC-коннекторы Kafka Connect. Apache Kafka как источник данных: source-коннектор JDBC Apache Kafka часто используется в качестве источника или приемника данных для аналитической обработки...

В прошлый раз мы говорили о способе взаимодействия задач между собой в Apache Airflow. Сегодня поговорим о таких сущностях, как соединение (connections) и хуки (hooks). Читайте в этой статье: что такое хук и соединение, как создать и скачать соединение, а также как подключить базу данных в Airflow. Что такое связи...

29 сентября 2021 года вышла новая версия популярного Big Data фреймворка Apache Flink. Мы сделали краткий обзор главных улучшений свежего релиза 1.14 общедоступного дистрибутива, а также его коммерциализации в Ververica Platform 2.6. Узнайте, как потоковая обработка и аналитики больших данных с Apache Flink станет еще проще и эффективнее. Исправление ошибок...

Сегодня рассмотрим, как Uber эффективно обрабатывает миллионы запросов на поездки c помощью технологий надежного хранения и быстрой аналитики больших данных. Вас ждет краткий ликбез по системе геопространственной индексации H3 и рассказ о том, почему компания заменила NoSQL-Cassandra c компонентом Saga интеграционного фреймворка Camel на геораспределенную облачную NewSQL-СУБД Spanner от Google....
Чтобы добавить в наши курсы для дата-инженеров еще больше полезных примеров, сегодня рассмотрим, как построить конвейер преобразования CSV-файлов и загрузить данные в масштабируемую NoSQL-СУБД GridDB с помощью Apache NiFi. Краткий ликбез по GridDB и Apache NiFi в кейсе построения ML-системы для анализа данных временных рядов. Анализ данных временных рядов c...
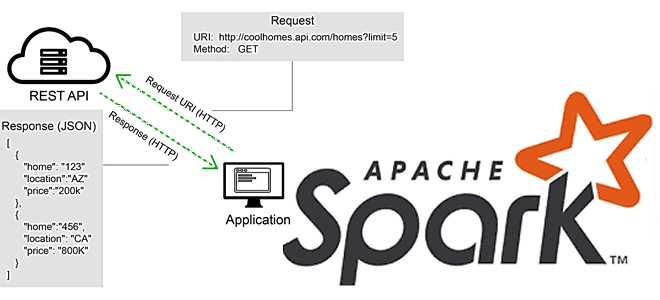
В этой статье для разработчиков Apache Spark разберем, что не так с вызовами REST API в этом фреймворке, и как решить эту проблему с помощью готовых библиотек или создания собственных UDF-функций на PySpark и не только. Для наглядности рассмотрим практический пример вызова REST API на PySpark с библиотекой Rest Data...

Постоянно обновляя наши курсы по Apache Kafka, сегодня рассмотрим еще один полезный инструмент для администраторов, дата-инженеров и разработчиков, который повышает эффективность взаимодействия с этой распределенной платформой потоковой обработки событий. Что такое Saamsa, какие проблемы Kafka она решает и как ее использовать на практике. 5 вопросов разработчика и дата-инженера к Apache...
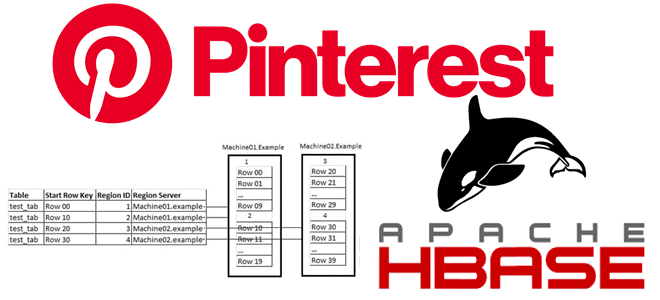
Обучая дата-инженеров и разработчиков распределенных приложений для аналитики больших данных, сегодня рассмотрим кейс компании Pinterest по построению масштабируемого решения для индексации записей в Apache HBase. Чем хранилище Ixia отличается от Lily HBase Indexer, зачем понадобился собственный аналог Solr и ElasticSearch, а также как все это работает в реальном времени с...

Рассмотрим пока еще фантастический пример из ближайшего будущего, где вся информация структурирована в виде графа знаний, доступ к сегментам которого определяется принадлежностью человека или машины к конкретной партии или корпорации. Как построить справочник организаций с помощью ИИ и графовой аналитики больших данных. Постановка задачи: построение справочника организаций Систематизация и упорядочивание...

Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим работу Data Science исследователей из Пизанского университета и сотрудников крупного ритейлера H&M по анализу данных торгового ассортимента компании с помощью ML-моделей на графах. Читайте далее, как машинное обучение на графовых нейросетях автоматизирует подбор сочетаемых предметов одежды и...

Сегодня разберем типовые ошибки, которые часто возникают в системах аналитики больших данных на базе Apache Hadoop YARN, Spark и RESTful-интерфейсу Livy, а также каким образом их избежать. В качестве практического примера используем ранее рассмотренный кейс интерактивной аналитики о пользовательском поведении в фотохостинге Pinterest. Интерактивная аналитика больших данных в Pinterest Недавно...

Недавно мы писали про платформы потоковой обработки событий, альтернативные Apache Kafka и Flink/Spark Streaming. В продолжение этой темы сегодня рассмотрим еще пару вариантов для разработки и самообслуживаемого использования потоковых конвейеров аналитики больших данных: DataCater и Flow. Читайте далее, что это за системы, как они связаны с Apache Kafka и какова...

Сегодня разберем типичный для современной дата-инженерии кейс построения конвейера обработки измененных данных на Apache NiFi с учетом безопасности и масштабируемости API-вызовов. Также рассмотрим, зачем использовать Apache NiFi при межсистемной интеграции через API-вызовы и как реализовать CDC-подход к изменениям в СУБД MySQL с помощью процессоров этого популярного ETL-фреймворка. CDC и интеграция...

В этой статье рассмотрим 2 способа физической группировки данных для ускорения последующей обработки в Apache Hive и Spark: партиционирование и бакетирование. Чем они отличаются друг от друга, что между ними общего и какой рост производительности дает каждый из методов в зависимости от задач аналитики больших данных средствами Spark SQL. Еще...