 400
400 
Содержание
- Архитектура и скрытые проблемы OS Page Cache
- Иллюзия скорости стандартного файлового чтения
- Серьезная проблема двойного кэширования информации
- Принципы работы паттерна через Direct IO
- Концепция Zero Cache против паттерна Zero-copy
- Сценарии использования паттерна в Big Data проектах
- Бонусный обзор инструмента от компании Rocicorp
- Заключение
- Ссылки и материалы
Zero Cache — это архитектурный паттерн проектирования высоконагруженных систем хранения данных. Он подразумевает полный и намеренный отказ приложения от использования системного кэша операционной системы. Программа напрямую взаимодействует с физическим дисковым накопителем через интерфейс прямого ввода-вывода. Это позволяет избежать бессмысленного двойного расхода дорогостоящей оперативной памяти. База данных получает полный архитектурный контроль над всеми своими вычислительными ресурсами.
В мире современной Big Data данный термин часто вызывает сильную путаницу. Многие начинающие инженеры ошибочно считают любой кэш абсолютным благом. Они полагают, что промежуточный буфер всегда безусловно ускоряет работу приложения. Но для мощных промышленных баз данных это правило перестает работать. Разработчики намеренно отключают кэширование на уровне ядра операционной системы. Этот сложный низкоуровневый подход надежно спасает аналитические системы от деградации производительности.
Термин стал особенно популярным в последние несколько тяжелых лет. Непрерывно растет общий физический объем обрабатываемой корпоративной цифровой информации. Вычислительные системы становятся все более сложными и требовательными каждый день. Разработчикам приходится искать абсолютно новые нестандартные пути глубокой оптимизации. Стандартные системные методы работы памяти серверов больше не работают эффективно. Инженеры вынуждены спускаться на самый низкий уровень управления аппаратурой.
Архитектура и скрытые проблемы OS Page Cache
Для глубокого понимания этой проблемы нужно заглянуть глубоко под капот. Архитектура обычного чтения любого дискового файла включает невидимого системного посредника. Этим посредником неизбежно выступает ядро вашей серверной операционной системы. Оно берет на себя всю сложную работу дисковых файловых операций.
Иллюзия скорости стандартного файлового чтения
Когда вы просто читаете файл, биты данных идут в память. Операционная система автоматически сохраняет их в свой огромный специальный буфер. Это пространство оперативной памяти называется знаменитым термином Page Cache. Следующее чтение этого же файла будет абсолютно мгновенным фоновым процессом. Операционная система отдаст его прямо из быстрой транзитной оперативной памяти. Звучит просто отлично для базовых и простых рутинных пользовательских задач.
Но теперь представьте очень мощную аналитическую колоночную базу данных. Она непрерывно сканирует огромные терабайты сырой информации каждую секунду времени. Ваша операционная система наивно пытается поместить все эти терабайты в буфер. Доступная свободная оперативная память сервера очень быстро заканчивается. Немедленно начинается агрессивный системный процесс вытеснения старых полезных страниц памяти. Важные системные данные удаляются ради одного единственного тяжелого аналитического запроса.
Производительность всего вашего вычислительного кластера резко падает глубоко вниз. Опытные дата-инженеры называют это страшным эффектом вымывания полезного системного кэша. Это самая главная системная причина нестабильности многих неопытных аналитических проектов.
Серьезная проблема двойного кэширования информации
Дальше текущая техническая ситуация становится еще намного сложнее и хуже. Каждая современная промышленная СУБД имеет свой собственный оптимизированный внутренний кэш. Она бережно хранит там самые важные поисковые индексы и блоки. Мощная база данных отлично знает логику своей повседневной бизнес-работы. У нее есть невероятно сложные внутренние алгоритмы предсказания будущей нагрузки.
При стандартном чтении дискового файла возникает критическая архитектурная ошибка проектирования. Появляется вредный эффект бессмысленного двойного кэширования одной и той же информации. Одни и те же гигабайты дублируются во внутреннем буфере базы данных. И эти же самые данные занимают место в системном буфере операционной системы.
Это просто огромная и совершенно нелепая трата доступной серверной памяти. Память исторически остается самым дорогим вычислительным ресурсом на любом сервере. Архитектура прямого доступа весьма элегантно решает именно эту насущную проблему. Она позволяет вашей СУБД работать напрямую с физическим контроллером диска. База данных жестко запрещает ядру сервера вмешиваться в этот процесс. Вся огромная ответственность полностью ложится на плечи создателей базы данных.
Принципы работы паттерна через Direct IO
Давайте детально разберем программную техническую реализацию этого интересного архитектурного паттерна. Главным системным программным инструментом здесь выступает технология интерфейса прямого доступа. Это специальный конфигурационный флаг при программном открытии любого дискового файла. В ядре популярной операционной системы Linux он носит название O_DIRECT.
Использование этого системного флага полностью и навсегда меняет стандартный маршрут данных. Ядро операционной системы больше вообще не копирует прочитанную информацию в буфер. Данные стремительно летят с контроллера диска прямо в память приложения. База данных сама полностью и безраздельно управляет этим сложным низкоуровневым процессом. Ей больше совершенно не нужны никакие медленные программные прослойки абстракции.
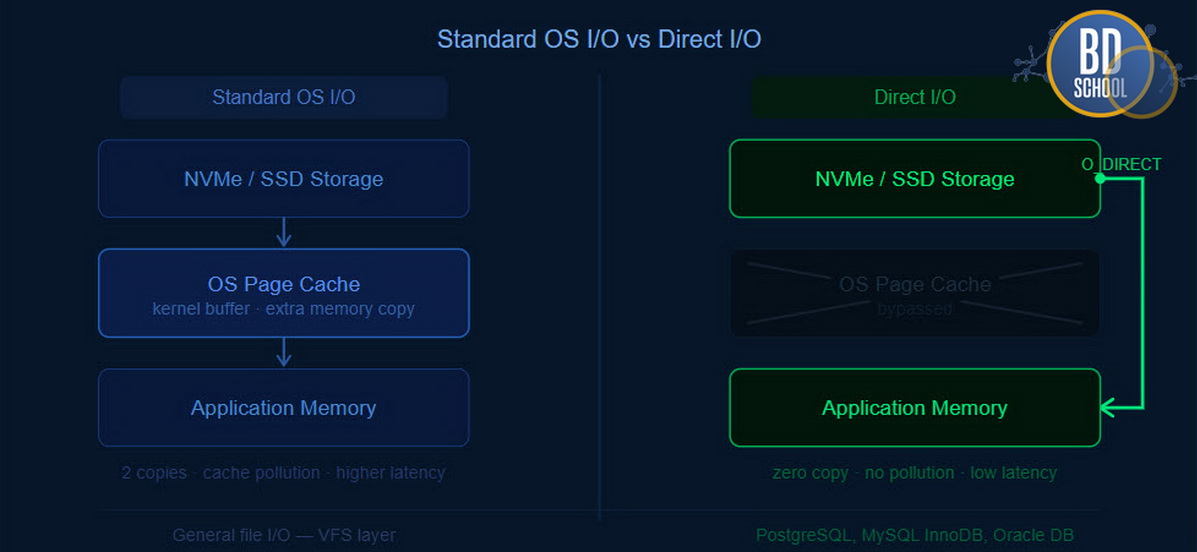
Однако программно работать с этой технологией не так уж просто. Программист обязан строго соблюдать жесткие системные аппаратные правила выравнивания памяти. Выделенный буфер в вашем приложении должен быть точно выровнен аппаратно. Размер всех читаемых данных тоже должен быть строго кратен размеру сектора. Иначе операционная система мгновенно прервет работу и выдаст фатальную ошибку.
Ниже представлен список главных архитектурных преимуществ использования интерфейса прямого доступа.
-
Радикальное снижение бесполезной фоновой вычислительной нагрузки на центральный процессор сервера.
-
Полное системное устранение вредного разрушительного эффекта вымывания полезного горячего кэша.
-
Глобальная экономия дорогостоящей оперативной памяти в вашем распределенном вычислительном кластере.
-
Абсолютно предсказуемая линейная скорость последовательного чтения данных с физического диска.
-
Полный и безраздельный архитектурный контроль над аппаратными ресурсами со стороны СУБД.
Эти важнейшие факторы делают данный программный подход совершенно незаменимым инструментом разработчика. После внедрения паттерна высоконагруженная база данных начинает работать потрясающе предсказуемо.
Для лучшей визуальной наглядности давайте посмотрим на базовый пример программного кода. Именно так выглядит реализация обхода буфера на популярном языке программирования Python.
import os
# Открываем системный файл с обязательным флагом O_DIRECT
# Это самый ключевой момент в архитектуре системного прямого доступа
file_path = "large_big_data_export.bin"
fd = os.open(file_path, os.O_RDONLY | os.O_DIRECT)
# Читаем байты данных напрямую в выделенную оперативную память приложения
# Размер нашего буфера строго кратен аппаратному физическому размеру сектора
buffer_size = 4096
data = os.read(fd, buffer_size)
print(f"Успешно прочитано байт напрямую с физического накопителя: {len(data)}")
os.close(fd)
Концепция Zero Cache против паттерна Zero-copy
Новички в системном низкоуровневом программировании очень часто путают эти два термина. Они действительно звучат весьма похоже для неискушенного слуха молодого инженера. Но они решают абсолютно разные фундаментальные инженерные задачи программной дисковой оптимизации. Давайте навсегда внесем кристальную инженерную ясность в этот сложный технический вопрос.
Наш обсуждаемый термин означает прямой бескомпромиссный отказ от любого промежуточного хранения. Мы принципиально не хотим временно хранить прочитанные данные в системном буфере. Мы читаем их напрямую в рабочую оперативную память самого работающего приложения. Это надежно защищает серверный кластер от бессмысленного двойного расхода дорогой памяти. Ваша база данных становится единственным полновластным владельцем всей загруженной с диска информации.
А вот смежный термин Zero-copy элегантно решает проблему лишнего программного копирования. Обычно это касается исключительно быстрой потоковой передачи мультимедийных файлов по сети. Система берет нужный огромный файл с диска и сразу отдает сетевой карте. Ваше приложение вообще физически не трогает эти огромные проходящие транзитные данные. Здесь очень часто программистами используется невероятно быстрый системный вызов ядра sendfile. Обе технологии отлично ускоряют работу серверов, но действуют совершенно разными системными путями.
Сценарии использования паттерна в Big Data проектах
Глубокое понимание сухой архитектурной академической теории — это только половина вашего дела. Важно точно и ясно знать моменты применения этого мощного архитектурного паттерна. Прямой доступ к накопителю нужен далеко не всем современным коммерческим проектам.
Он идеально и гармонично подходит для невероятно тяжелой аналитики огромных объемов данных. Представьте мощные аналитические подсистемы современных больших корпоративных хранилищ сырых данных. Например, невероятно популярные аналитические решения ClickHouse или массивно-параллельный кластер СУБД Greenplum. Они круглосуточно сканируют гигантские денормализованные широкие таблицы от начала до конца. Если они будут использовать стандартный системный кэш, кластер просто зависнет навсегда. Системный промежуточный буфер моментально переполнится совершенно ненужным одноразовым информационным мусором.
Ниже перечислены самые частые типовые сценарии целесообразного применения данной низкоуровневой технологии.
-
Регулярное полное ночное сканирование огромных исторических аналитических таблиц в хранилище.
-
Сложная внутренняя фоновая работа систем управления классическими реляционными базами данных.
-
Массовый высоконагруженный сетевой стриминг огромных видеофайлов без промежуточной обработки центральным сервером.
-
Ежедневное программное создание резервных копий совершенно безумных объемов корпоративной информации.
-
Построение распределенных высоконагруженных кластеров для новейших объектных файловых систем нового поколения.
Именно в этих конкретных специфических случаях прямой ввод-вывод дает максимальный профит. Общая вычислительная производительность IT инфраструктуры компании мгновенно вырастает в несколько раз.
А вот типичным маленьким микросервисным веб-приложениям этот подход только сильно навредит. Обычно они читают крошечные конфигурационные текстовые файлы по многу раз подряд. Системный буфер здесь просто жизненно и критически необходим для общей скорости ответа.
Для тонкого управления кэшированием в базах часто используются специальные декларативные конфигурационные настройки.
-- Пример базовой системной настройки параметров в популярной СУБД PostgreSQL -- Эти критичные параметры напрямую управляют использованием памяти рабочим сервером ALTER SYSTEM SET shared_buffers = '16GB'; ALTER SYSTEM SET effective_cache_size = '48GB'; -- СУБД всегда параллельно использует свой внутренний кэш и системный кэш -- Вы можете предельно тонко настраивать этот деликатный баланс распределения системной памяти SELECT pg_reload_conf();
Бонусный обзор инструмента от компании Rocicorp
В самое последнее время наш технический термин внезапно получил совершенно новое значение. Известная зарубежная технологическая компания Rocicorp недавно выпустила свой крутой инновационный программный продукт. Это важная серверная вычислительная часть их фреймворка для быстрой двунаправленной синхронизации данных. Их новый производительный серверный компонент буквально и совершенно официально называется zero-cache.
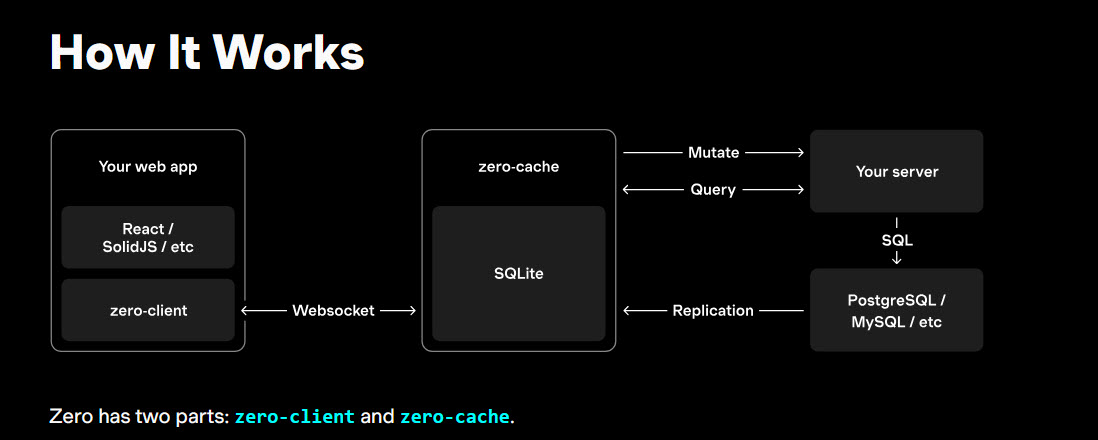
Этот мощный инструмент весьма изящно решает сложную архитектурную проблему актуальности данных клиента. Он просто отлично работает в популярной современной микросервисной архитектуре Local-First веб-разработки. Клиентское мобильное или десктопное веб-приложение всегда имеет самую свежую локальную копию данных. Центральный облачный сервер мгновенно и сверхнадежно пушит изменения на все подключенные устройства.
Название этого классного коммерческого продукта говорит само за себя опытным инженерам. Разработчикам больше совершенно не нужно мучительно строить сложные многоуровневые слои программного кэширования. Вам больше не нужны хрупкие нестабильные внешние системы вроде мощного кластера Redis. Синхронизация состояний происходит напрямую между центральной облачной базой и конечным пользовательским клиентом. Это невероятно сильно упрощает архитектурную жизнь всем современным уставшим фронтенд-разработчикам. Однако всегда нужно помнить один весьма критический и важный смысловой нюанс концепции. Это уже полностью готовый коммерческий программный продукт, а не низкоуровневый системный паттерн.
Заключение
Мы весьма детально и максимально глубоко разобрали важнейшую архитектурную концепцию системного программирования. Использование паттерна полного обхода буфера и прямого аппаратного доступа творит настоящие чудеса. Это сверхнадежно спасает ваши высоконагруженные промышленные серверы от острой критической нехватки оперативной памяти.
Современные мощные аналитические базы данных обязаны сами филигранно управлять своими аппаратными ресурсами. Ваша стандартная операционная система не всегда знает рабочую ситуацию лучше самих инженеров. Полный архитектурный отказ от системного буфера навсегда убирает бессмысленное и вредное двойное кэширование памяти. Это делает максимально предсказуемой тяжелую рутинную работу самых сложных корпоративных аналитических SQL запросов. Вы отлично знаете про новый классный движок синхронизации от известной компании Rocicorp. Обязательно грамотно используйте эти ценные фундаментальные знания для построения сверхнадежных высоконагруженных хранилищ данных.