 408
408 
Содержание
- Введение в концепцию отложенной записи
- Архитектура механизма отложенной записи
- Принципы работы и балансировка производительности
- Защита данных через упреждающее журналирование
- Сценарии использования в популярных системах
- Буферизация сообщений в Apache Kafka
- MemTable в архитектуре Apache Cassandra
- Влияние железа на механизмы буферизации
- Узкие места кэша и системный троттлинг
- Примеры кода для настройки и мониторинга
- Заключение
- Референсы и полезные материалы
Отложенная запись (Write pending) — это временное накопление информации в оперативной памяти сервера перед физическим сохранением на жесткий диск. Этот архитектурный паттерн группирует множество мелких операций изменения данных для их последующей эффективной потоковой записи.
Введение в концепцию отложенной записи
Современные приложения генерируют колоссальные потоки информации ежесекундно. Сохранять каждый байт напрямую на физический носитель слишком долго. Скорость работы жестких дисков и твердотельных накопителей сильно уступает скорости оперативной памяти. Разница во времени доступа может достигать десятков тысяч раз. Если система будет ждать физического сохранения каждого запроса, она моментально зависнет.
Механизм отложенной записи элегантно решает эту фундаментальную проблему физики. Сервер быстро принимает пакет данных в свою сверхбыструю оперативную память. Пользователь сразу получает подтверждение успешного выполнения своей операции. Приложение продолжает свою работу без длительных блокировок. Фактический перенос байтов на диск происходит позже в полностью фоновом режиме. Этот процесс протекает незаметно для внешних клиентов базы данных.
Архитектура механизма отложенной записи
Каждая операция сохранения проходит строго определенный жизненный цикл. База данных сначала резервирует место в своем внутреннем кэше. Новая информация записывается в специальные блоки оперативной памяти. Инженеры традиционно называют такие измененные блоки грязными страницами.
Этот термин означает наличие новых данных без копии на диске. Операционная система непрерывно следит за общим количеством таких страниц. Когда их становится слишком много, запускается процедура очистки.

Специальные системные воркеры забирают грязные страницы из оперативной памяти. Они выстраивают данные в ровные длинные цепочки. Затем эти крупные блоки отправляются на контроллер физического диска. Страницы в памяти получают статус чистых после завершения этой медленной операции. Теперь память можно использовать для новых пользовательских запросов.
Практическое применение Big Data аналитики для решения бизнес-задач
Код курса
PRUS
Ближайшая дата курса
7 сентября, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Принципы работы и балансировка производительности
Главная выгода отложенной записи заключается в многократном росте пропускной способности. Система избегает случайного доступа к жесткому диску. Множество разрозненных мелких запросов объединяются в один крупный блок. Потоковая запись крупных блоков работает с максимальной скоростью накопителя. Это снижает износ оборудования и экономит вычислительные ресурсы сервера.
Однако у этого паттерна есть серьезный недостаток. Оперативная память является энергозависимой средой хранения. Внезапное отключение питания сервера приведет к полной потере содержимого кэша. Все данные в статусе ожидания записи исчезнут навсегда. Для предотвращения таких катастроф инженеры используют дополнительные механизмы надежности.
Ниже перечислены основные способы защиты отложенных данных в памяти.
- Журналирование транзакций перед изменением основных таблиц.
- Репликация измененных блоков памяти по сети на резервные узлы.
- Использование встроенных батареек на аппаратных дисковых контроллерах.
Комбинация этих методов гарантирует сохранность бизнеса при любых авариях. Системные администраторы гибко настраивают баланс между скоростью и надежностью. Жесткие требования бизнеса всегда определяют финальную конфигурацию серверов.
Защита данных через упреждающее журналирование
Журнал упреждающей записи является индустриальным стандартом защиты баз данных. В англоязычной литературе этот механизм называется Write-Ahead Logging или просто WAL. Он гениально совмещает высокую скорость кэша и надежность диска.
Каждое изменение сначала дописывается строго в конец специального файла журнала. Эта операция выполняется последовательно и не требует долгих поисков по диску. Только после этого меняется целевая страница в оперативной памяти.
Ниже показан детальный поток данных этого механизма.
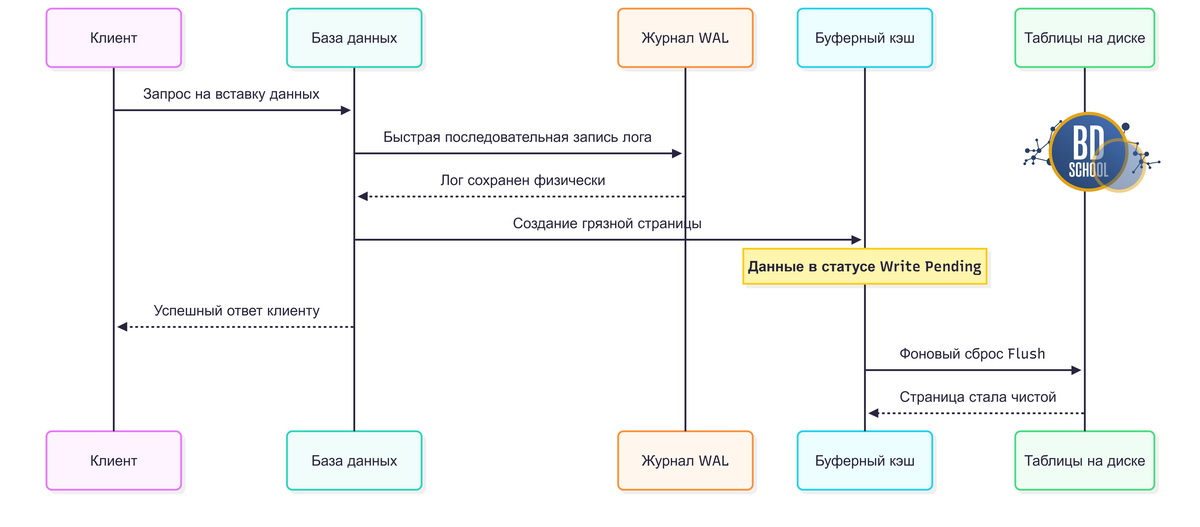
Если сервер падает, грязные страницы в оперативной памяти стираются. Но при перезапуске система читает файл журнала с диска. Она находит все операции, которые не успели сброситься из кэша. База данных аккуратно повторяет эти действия в памяти заново. Строгая консистентность восстанавливается без участия администратора.
Сценарии использования в популярных системах
Концепция ожидания записи применяется практически в любой современной платформе данных. Разница кроется лишь в деталях программной реализации. Инженеры адаптируют этот механизм под конкретные задачи каждого хранилища.
Рассмотрим самые яркие примеры архитектурных решений на рынке.
Буферизация сообщений в Apache Kafka
Этот популярный брокер активно использует отложенную запись на стороне брокера. Одно из главных архитектурных решений Kafka заключается в том, что она не управляет дисковым кэшем самостоятельно (как это делают классические СУБД вроде PostgreSQL), а полностью делегирует эту задачу операционной системе Linux.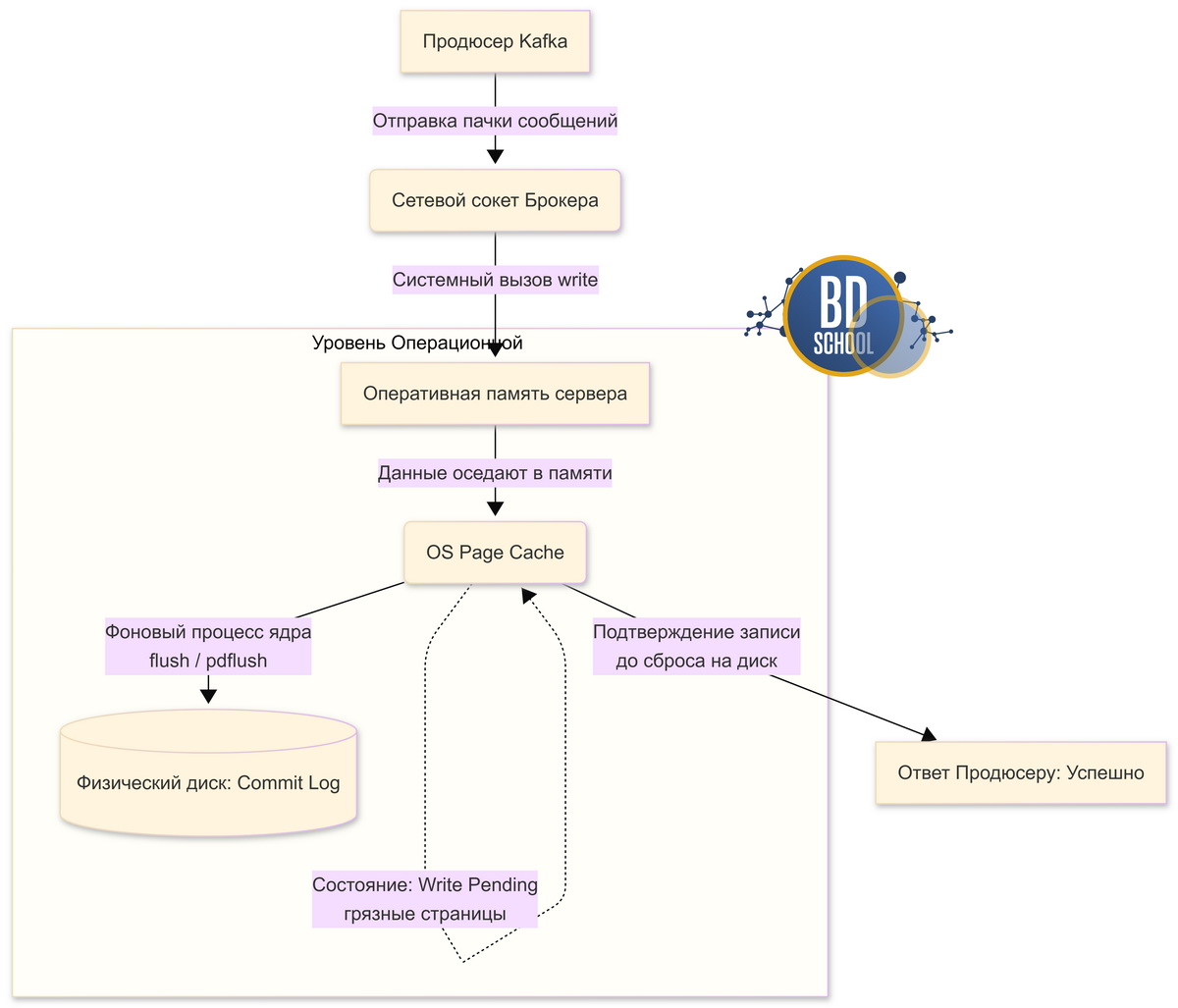
Вот как выглядит реальный процесс Write Pending в Kafka:
- Брокер получает пачку сообщений от продюсера по сети.
- Брокер вызывает системный вызов для записи данных в файл лога (Commit Log).
- ОС Linux перехватывает эту запись и помещает данные в свою оперативную память — OS Page Cache.
- В этот момент данные получают статус «грязных страниц» (dirty pages). Это и есть состояние Write Pending.
- Если продюсер запросил подтверждение (например, acks=1), брокер отвечает «Успешно», хотя физически данные всё ещё висят в оперативной памяти сервера.
- Позже, в фоновом режиме, ядро Linux (процессы flush или kupdate) сбрасывает эти грязные страницы на физический жесткий диск.
Если что то из вышеперечисленного вам непонятно, приходите к нам на курс по Администрированию Apache Kafka — мы там все это подробно рассматриваем!
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
5 октября, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
MemTable в архитектуре Apache Cassandra
Колоночная база данных спроектирована для максимальной скорости записи метрик. Новые значения не ищут свое место в существующих дисковых файлах. Они моментально оседают в специальной структуре памяти MemTable. Одновременно происходит параллельная фиксация в журнале транзакций.
Когда таблица в памяти переполняется, происходит однократный сброс. Данные сливаются на диск в виде нового неизменяемого файла. Файлы позже объединяются в фоне специальным процессом компактизации. Эта изящная архитектура устраняет главную проблему медленных случайных записей.
Влияние железа на механизмы буферизации
Тип физического носителя диктует свои правила игры для программного обеспечения. Традиционные жесткие диски имеют вращающиеся пластины и магнитные головки. Им физически больно обрабатывать мелкие случайные порции данных. Для них отложенная запись является единственным способом выжить под нагрузкой.
Твердотельные диски лишены механических движущихся частей. Они отлично справляются со случайным доступом к блокам памяти. Однако у них существует фундаментальная проблема износа кремниевых ячеек. Каждая ячейка выдерживает строго ограниченное количество циклов перезаписи.
Механизм буферизации спасает корпоративные накопители от быстрой деградации. Он укрупняет блоки и сокращает общее количество физических обращений. Это критически важно для высоконагруженных промышленных баз данных. Инвестиции в достаточный объем оперативной памяти всегда окупаются долгим сроком службы дисков.
Узкие места кэша и системный троттлинг
Любые аппаратные ресурсы имеют свои жесткие ограничения. Объем буферного кэша оперативной памяти не является бесконечным. База данных не может копить грязные страницы вечно. Если фоновый сброс не успевает за потоком новых данных, возникает проблема.
Система достигает критического порога заполнения памяти. В этот момент операционная система включает защитные механизмы. Начинается принудительное замедление новых входящих клиентских запросов. Этот неприятный процесс называют системным троттлингом.
Симптомы троттлинга всегда выглядят крайне тревожно для бизнеса.
- Резко возрастает время отклика пользовательского веб-приложения.
- В системных логах появляются ошибки истечения времени ожидания.
- Процессор сервера перегружен потоками ввода-вывода.
Единственный способ исправить ситуацию заключается в грамотной настройке лимитов. Инженеры настраивают так называемые водяные знаки памяти. Фоновый сброс должен начинаться задолго до полного переполнения буфера. Плавная постоянная работа диска всегда предпочтительнее внезапных авральных сбросов.
Примеры кода для настройки и мониторинга
Отличным примером управляемой отложенной записи является база данных Apache HBase. В ней механизм буферизации встроен прямо в архитектуру узла данных.
Когда клиент отправляет новую запись, она поступает на сервер региона. Система сначала делает быструю последовательную отметку в защитном журнале WAL. Затем информация помещается в специальную структуру оперативной памяти. Эта область памяти традиционно называется MemStore.
Именно здесь данные официально получают статус ожидания записи. Сервер моментально отправляет клиенту подтверждение успешного сохранения транзакции. Информация копится в оперативной памяти до достижения заданного предела. Затем запускается фоновый сброс данных в постоянный дисковый файл HFile.
Инженеры управляют этим поведением через конфигурационный файл кластера. Ниже представлен классический пример настроек в формате XML.
<configuration>
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
</property>
<property>
<name>hbase.regionserver.global.memstore.upperLimit</name>
<value>0.40</value>
</property>
<property>
<name>hbase.regionserver.global.memstore.lowerLimit</name>
<value>0.35</value>
</property>
</configuration>
Эти параметры позволяют детально контролировать баланс нагрузки. Первый параметр задает жесткий размер локального буфера для одного региона. Остальные настройки устанавливают глобальные водяные знаки для всего сервера.
Когда общий объем грязных страниц достигает верхнего лимита, начинается сброс. Система агрессивно сохраняет файлы до достижения нижнего комфортного порога. При правильной настройке этих дробей дисковая подсистема работает плавно. Сервер избегает внезапных пауз и неприятного системного троттлинга.
Сложные реляционные базы требуют глубокого мониторинга своих внутренних процессов. Инженерам необходимо понимать эффективность работы механизмов фонового сброса. Для этого используются встроенные системные представления словаря данных.
Пример простого SQL запроса для проверки статистики в PostgreSQL.
SELECT buffers_clean, buffers_backend, maxwritten_clean, buffers_alloc FROM pg_stat_bgwriter;
Этот запрос возвращает критически важные метрики работы фонового писателя. Большое значение очищенных серверными процессами буферов сигнализирует о проблеме. Это означает, что фоновый писатель не справляется со своей работой. Пользовательские запросы вынуждены сами сбрасывать данные на диск. Это прямое показание к изменению настроек конфигурационного файла базы данных.
Практическое применение Big Data аналитики для решения бизнес-задач
Код курса
PRUS
Ближайшая дата курса
7 сентября, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Заключение
Механизм отложенной записи является скрытым двигателем современных распределенных систем. Он виртуозно нивелирует гигантскую разницу в скорости между памятью и дисками. Кэширование позволяет строить высоконагруженные сервисы реального времени. Пользователи получают моментальный отклик благодаря магии буферов в оперативной памяти.
Однако за высокую пропускную способность всегда нужно платить. Инженерам необходимо глубоко понимать риски использования энергозависимой памяти. Настройка журналов упреждающей записи и правильная конфигурация сброса критически важны. Баланс между производительностью и надежностью является главным искусством проектирования архитектуры. Надеюсь, данная статья помогла вам разобраться в этом сложном процессе.
Референсы и полезные материалы
- Официальная документация PostgreSQL 17 (2025) глава WAL Configuration. Доступно по ссылке: https://www.postgresql.org/docs/17/wal-configuration.html
- Документация Apache Kafka 3.9 (2026) раздел Producer Configs. Доступно по ссылке: https://kafka.apache.org/39/documentation.html#producerconfigs
- Блог DataStax (2025) внутреннее устройство MemTable. Доступно по ссылке: https://www.datastax.com/blog/2025/cassandra-architecture-memtable