
Продолжая разговор про форматы Big Data файлов, сегодня мы рассмотрим разницу между линейными и колоночными типами, а также расскажем о том, как выбирать между AVRO, Sequence, Parquet, ORC и RCFile при работе с Apache Hadoop, Kafka, Spark, Flume, Hive, Drill, Druid и других средствах работы с большими данными. Итак, форматы...

Мы уже упоминали формат Parquet в статье про Apache Avro, одну из наиболее распространенных схем данных Big Data, часто используемую в Kafka, Spark и Hadoop. Сегодня рассмотрим более подробно, чем именно хорошо Apache Parquet и как он отличается от других форматов Big Data. Что такое Apache Parquet и как он...

Мы уже рассказывали, зачем нужна интеграция Apache Kafka и Spark Streaming. Сегодня рассмотрим, как технически организовать такой Big Data конвейер по непрерывной обработке потоковых данных в режиме реального времени. Способы интеграции Наладить двустороннюю связь между Apache Kafka и Spark Streaming возможны следующими 2-мя способами: получение сообщений через службу синхронизации Zookeeper...
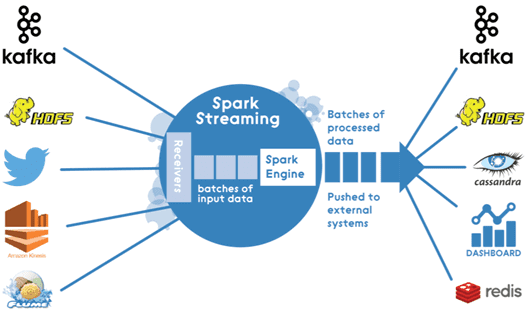
В этой статье мы рассмотрим архитектуру Big Data конвейера по непрерывной обработке потоковых данных в режиме реального времени на примере интеграции Apache Kafka и Spark Streaming. Что такое Spark Streaming и для чего он нужен Spark Streaming – это надстройка фреймворка с открытым исходным кодом Apache Spark для обработки потоковых...

Apache Kafka – не единственный программный брокер сообщений и система управления очередями, используемая в высоконагруженных Big Data проектах. Кафка часто сравнивают с другим популярным продуктом аналогичного назначения – RabbitMQ. В сегодняшней статье мы рассмотрим, чем похожи и чем отличаются Apache Kafka и RabbitMQ, а также поговорим о том, что следует...

Мы уже рассказывали о сериализации, схемах данных и их важности в Big Data на примере Schema Registry для Apache Kafka. В продолжение ряда статей про основы Кафка для начинающих, сегодня мы поговорим про Apache Avro – наиболее популярную схему и систему сериализации данных: ее особенностях и применении в технологиях Big...
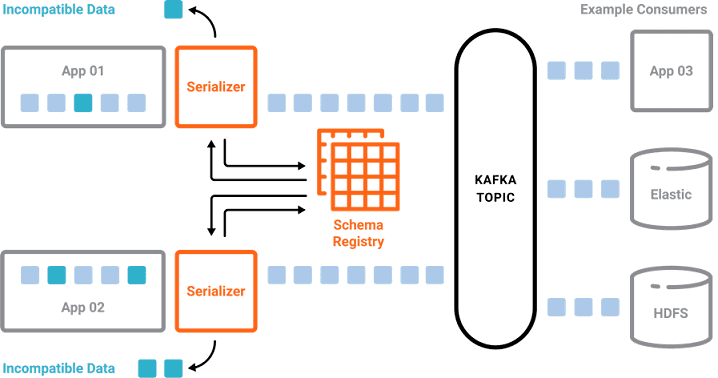
Продолжая серию публикаций про основы Apache Kafka для начинающих, в этой статье мы рассмотрим, зачем этой распределенной системе управления сообщениями нужен реестр схем данных (Schema Registry) и что такое сериализация файлов Big Data. Что такое схемы данных в Big Data и как они используются Понятие схемы неразрывно связано с форматом...

В рамках серии публикаций про основы Apache Kafka для начинающих, сегодня мы поговорим про информационную безопасность этой популярной в сфере Big Data распределенной системы управления сообщениями: шифрование, защищенные протоколы, аутентификация, авторизация и другие средства cybersecurity. Что обеспечивает безопасность Apache Kafka в кластере Big Data Информационная безопасность Apache Kafka основана на...
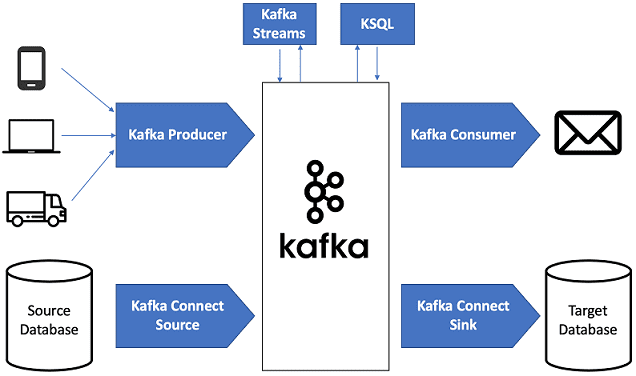
Продолжая разговор про основы Apache Kafka, сегодня мы рассмотрим, почему этот распределённый брокер сообщений стал таким популярным в архитектуре систем Big Data. Читайте в нашей статье, как Кафка обеспечивает высокую производительность процессов сбора и агрегации информационных потоков от множества источников, надежно гарантируя долговечную сохранность сообщений, и эффективно интегрируется с другими...
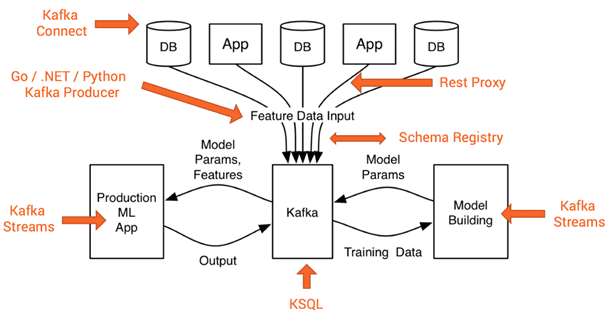
Рассмотрев основы Apache Kafka, сегодня мы расскажем о месте этого распределённого брокера сообщений в архитектуре Big Data систем. Читайте в нашей статье, какие компоненты Кафка обеспечивают ее использование в программных продуктах машинного обучения (Machine Learning, ML), интернете вещей (Internet Of Things, IoT), системах бизнес-аналитики (Business Intelligence, BI), а также других...

Мы уже упоминали Apache Kafka в статье про промышленный интернет вещей (Industrial Internet Of Things, IIoT). Сегодня поговорим о том, где и для чего еще в Big Data проектах используется эта распределённая, горизонтально масштабируемая система обработки сообщений. Как работает Apache Kafka Apache Kafka позволяет в режиме онлайн обеспечить сбор и...

Даже после очистки и нормализации данных, выборка еще не совсем готова к моделированию. Для машинного обучения (Machine Learning) нужны только те переменные, которые на самом деле влияют на итоговый результат. В этой статье мы расскажем, что такое отбор или выделение признаков (Feature Selection) и почему этот этап подготовки данных (Data...

Мы уже рассказали, что такое нормализация данных и зачем она нужна при подготовке выборки (Data Preparation) к машинному обучению (Machine Learning) и интеллектуальному анализу данных (Data Mining). Сегодня поговорим о том, как выполняется нормализация данных: читайте в нашем материале о методах и средствах преобразования признаков (Feature Transmormation) на этапе их...

Нормализация данных – это одна из операций преобразования признаков (Feature Transformation), которая выполняется при их генерации (Feature Engineering) на этапе подготовки данных (Data Preparation). В этой статье мы расскажем, почему необходимо нормализовать значения переменных перед тем, как запустить моделирование для интеллектуального анализа данных (Data Mining). Что такое нормализация данных и чем она...

Извлечение признаков (Feature Extraction) из текста – часто встречающаяся задача Data Mining, а именно этапа генерации признаков. Интеллектуальный анализ текста получил название Text Mining. В этом случае Feature Extraction относится к сфере NLP, Natural Language Processing – обработка естественного языка. Это отдельное направление искусственного интеллекта и математической лингвистики [1]. Здесь...

Генерация признаков – пожалуй, самый творческий этап подготовки данных (Data Preparation) для машинного обучения (Machine Learning). Этот этап еще называют Feature Engineering. Он наступает после того, как выборка сформирована и очистка данных завершена. В этой статье мы поговорим о том, что такое признаки, какими они бывают и как Data Scientist...

Выборка, полученная в результате первого этапа подготовки данных (Data Preparation), еще пока не пригодна для обработки алгоритмами машинного обучения, поскольку информацию необходимо очистить. Сегодня мы расскажем, что такое очистка данных (Data Cleaning) для Data Mining, зачем она нужна и как выполнять этот этап Data Preparation. Что такое очистка данных для...
Мы уже рассказывали о важности этапа подготовки данных (Data Preparation), результатом которого является обработанный набор очищенных данных, пригодных для обработки алгоритмами машинного обучения (Machine Learning). Такая выборка, называемая датасет (dataset), нужна для тренировки модели Machine Learning, чтобы обучить систему и затем использовать ее для решения реальных задач. Однако, поскольку в...

CRISP-DM, SEMMA и другие стандарты Data Mining не случайно выделяют подготовку данных в отдельную фазу. Data Preparation - весьма трудоемкий итеративный процесс, который занимает до 80% всех затрат ресурсов и времени в жизненном цикле Data Mining и включает следующие задачи обработки исходных («сырых») данных [1]: Выборка данных – отбор признаков...

Сегодня большие данные и технологии распределенного реестра до сих пор являются самыми популярными ИТ-темами. Возможности их внедрения в каждую прикладную сферу, от банковской отрасли до медицины, обсуждаются на конференциях всех уровней, корпоративных совещаниях и государственных советах [1]. Принесет ли объединение Big Data и блокчейн дополнительные бонусы, в каких случаях не...